Q-learning is an algorithm, that contains many of the basic structures required for reinforcement learning and acts as the basis for many more sophisticated algorithms. The Q-learning algorithm can be seen as an (asynchronous) implementation of the Robbins-Monro procedure for finding fixed points. For this reason we will require results from Robbins-Monro when proving convergence.
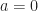
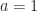
=\begin{cases} \kappa(x),& \text{for }a=0\quad\textit{ (the stopping cost)}\\ c(x),& \text{for }a=1\quad\textit{ (the continuation cost)}, \end{cases}")
 = \maxi_{\Pi \in {\mathcal P} } \quad R(x,\Pi) := \mathbb{E}_{x_0} \left[ \sum_{t=0}^{\infty} \beta^{t} r(X_t,\pi_t) \right] \, .")
