We review a method for finding fixed points then extend it to slightly more general, modern proofs. This is a much more developed version of an earlier post. We now cover the basic Robbin-Monro proof, Robbins-Siegmund Theorem, Stochastic Gradient Descent and Asynchronous update (as is required for Q-learning).
Often it is important to find a solution to the equation
")
by evaluating 

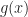
 + \epsilon_n")
and hope solve for 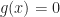
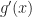

where we chose the sequence 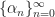

Before proceeding here are a few different use cases:
- Quartiles. We want to find
such that
for some fixed
. But we can only sample the random variable
.
- Regression. We preform regression
, but rather than estimate
we want to know where
.
- Optimization. We want to optimize a convex function
whose gradient is
for some large
. To find the optimum at
whose gradient,
, is an bias estimate of
The following result contains the key elements of the Robbins-Monro proof
Prop 1. Suppose that 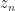
 + c_n")
where 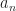
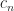

then 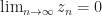
Proof. We can assume that equality holds, i.e., 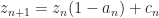

Now for all 
 = \sum_{k=1}^{n-1} c_k - \sum_{k=1}^{n-1} a_k z_k")
Since 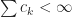
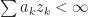


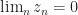

The following proposition is a Martingale version of the above result.
Thrm 1 [Robbins-Siegmund Theorem] If
 Z_n +c_n")
for positive adaptive RVs 

then
Proof. The results is some manipulations analogous to the Robbins-Monro proof and a bunch of nice reductions to Doob’s Martingale Convergence Theorem.
First note the result is equivalent to proving the result with 
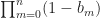
 Z'_n +c'_n\,,")
where 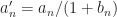

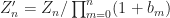
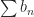
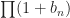
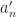
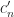
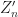
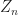

Now notice

is a super-martingale. We want to use Doob’s Martingale convergence theorem; however, we need to apply a localization argument to apply this. Specifically, let 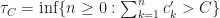

So 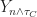
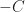
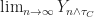
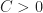




Now notice

So like in the last proposition, since 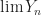

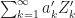
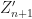
Finally since we assume 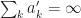
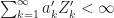
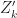
Stochastic Gradient Decent
Suppose that we have some function
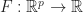
 = \mathbb E_X [ f(X ; \theta) ]")
that we wish to minimize. We suppose that the function 
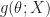
![\mathbb E [g(\theta;X) ] = G(\theta)](https://s0.wp.com/latex.php?latex=%5Cmathbb+E+%5Bg%28%5Ctheta%3BX%29+%5D+%3D+G%28%5Ctheta%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
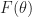
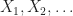
 where
where 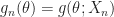

(Note here we may assume that 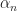
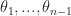
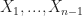
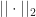
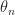
Thrm 2 [Stochastic Gradient Descent] Suppose that 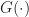
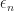
such that
,

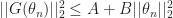
![\mathbb E [ || \epsilon_n||_2^2 | \mathcal F_n ] \leq K](https://s0.wp.com/latex.php?latex=%5Cmathbb+E+%5B+%7C%7C+%5Cepsilon_n%7C%7C_2%5E2+%7C+%5Cmathcal+F_n+%5D+%5Cleq+K+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Then 
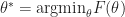
![\lim \mathbb E [ || \theta_n - \theta^* ||_2^2 ] =0](https://s0.wp.com/latex.php?latex=%5Clim+%5Cmathbb+E+%5B+%7C%7C+%5Ctheta_n+-+%5Ctheta%5E%2A+%7C%7C_2%5E2+%5D+%3D0&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Let’s quickly review the conditions above. First consider Condition 1. Note condition 
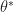
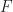

Proof.
 \cdot ( \theta_n -\theta^* ) - \alpha_n \epsilon_n \cdot ( \theta_n - \alpha_n G(\theta_n) -\theta^* ) + \alpha^2_n || \epsilon_n||_2^2 + \alpha^2_n ||G(\theta_n) ||_2^2\end{aligned}")
Taking expecations with respect to ![\mathbb E [ | \mathcal F_n]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E+%5B+%7C+%5Cmathcal+F_n%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 \cdot ( \theta_n -\theta^* ) + \alpha^2_n \mathbb E [ || \epsilon_n||_2^2 | \mathcal F_n ] + \alpha^2_n ||G(\theta_n) ||_2^2 \\ \leq & - \alpha_n \mu || \theta_n -\theta^* ||_2^2 + \alpha^2_n K + \alpha^2_n (A+ B ||\theta_n -\theta^* ||_2^2)\end{aligned}")
Thus, rearranging
 || \theta_{n} - \theta^* ||_2^2 + \alpha_n^2 (K+A)")
Thus by Thrm 1, 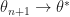
 \mathbb E [ || \theta_{n} - \theta^* ||_2^2 ] + \alpha_n^2 (K+A)")
We can apply Prop 1 (note that 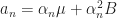
![\mathbb E || \theta_{n+1} - \theta^* ||_2^2 ] \rightarrow 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E+%7C%7C+%5Ctheta_%7Bn%2B1%7D+-+%5Ctheta%5E%2A+%7C%7C_2%5E2+%5D+%5Crightarrow+0&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
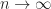
Finally we remark that in the proof we analyzed 
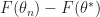
Fixed Points and Asynchronous Update
We now consider Robbins-Monro from a slightly different perspective. Suppose we have a continuous function 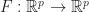
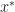
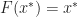
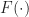
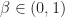
 - F(y) ||_{\infty} \leq \beta || x- y ||_{\infty} \, .")
Here 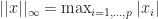

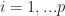
 = x_i(t) + \alpha_i(t) ( F_i(x(t)) - x_i(t) + \epsilon_i(t)) \tag{RM-Async}")
where 
 = \infty, \qquad \sum_{t} \alpha_i^2(t) < C\, . \tag{RM step}")
for some constant 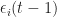

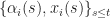
 | \mathcal F_t ] = 0\, . \qquad \text{and} \qquad \mathbb E [ \epsilon^2_i(t) | \mathcal F_t ] \leq A + B \max_j | x_j(t) |^2\, . \label{RM:noise}")
Note that in the above we let the step rule depend on 


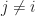
We can analyze the convergence of this similarly
Thrm 3. Suppose that 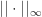
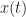
 = x^*")
where 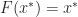
We will prove the result under the assumption that
Prop 2. If we further assume that
||_{\infty} < \infty \,")
with probability 1 then Thrm 3 holds.
We may assume with out loss of generality that 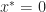
-x^* = x_i(t)-x^* + \alpha_i(t) ( F_i(x(t))- F_i(x^*) - x_i(t)+x^* + \epsilon_i(t)) \, .")
Given the assumption above that 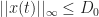
 D_k")
Here we choose 
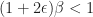
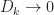

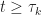

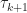
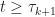
 ||_{\infty} < D_{k+1}")
We use two recursions to bound the behavior of 
 & = (1 - \alpha_i(t) ) W_i(t) + \alpha_i(t) w_i(t) \\ Y_i(t+1) & = (1-\alpha_i(t) ) Y_i(t) + \alpha_i(t) \beta D_k\, .\end{aligned}")
for 
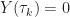
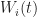
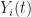
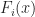
![]()
in Lemma 1 below. Further we notice that is a Robbin-Monro recursion for 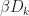
Lemma 1.

![]()
Proof. We prove the result by induction. The result is clearly true for 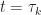
 & = (1-\alpha_i(t) ) x_i(t) + \alpha_i(t) F_i(\bm x^i(t)) +\alpha_i(t) w_i(t) \\ & \leq ( 1 - \alpha_i(t) ) ( Y_i(t) + W_i(t ) ) + \alpha_i(t) \beta D_k + \alpha_i(t) \epsilon_i(t) \\ & = Y_i(t+1) + W_i(t+1) \end{aligned}") In the inequality above with apply the induction hypothesis on
In the inequality above with apply the induction hypothesis on 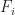
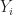
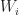
Lemma 2.  | =0")
Proof. Letting 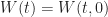
^2 | \mathcal F_t ] \leq (1- 2\alpha(t) + \alpha^2) W(t)^2 + \alpha(t)^2 \mathbb E [ \epsilon (t)^2 | \mathcal F_t ].")
From the Robbins-Siegmund Theorem (Prop 1), we know that
 =0.")
Lemma 3. ![]()
Proof. Notice  - \beta D_k = (1-\alpha_i(t) ) ( Y_i(t) - \beta D_k ) = ... = \left( \prod_{s=1}^t (1-\alpha_i(s) ) \right) ( Y_i(0) - \beta D_k )") The result holds since
The result holds since 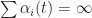
We can now prove Prop [Tsit:Prop].
Proof of Prop 2. We know that 
 | \leq Y_i(t) + | W_i(t ) | \xrightarrow[t\rightarrow\infty]{} \beta D_k")
as required. Thus these exists 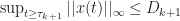
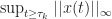

Proving Boundedness of
We now prove that
Prop 3.
To prove this proposition, we define a processes that bounds the max of 
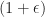
 := \max_{\tau \leq t } ||x(\tau) ||_\infty")
and we define 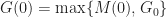
 = \begin{cases} G(t) & \text{if } M(t+1) < (1+\epsilon) G(t), \\ (1+\epsilon)^k G(t) & \text{if } M(t+1) \geq (1+\epsilon) G(t)\, . \end{cases}")
where in the above 
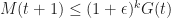
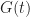
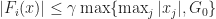
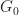

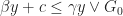
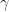

Also we define 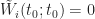
 = (1 - \alpha_i(t) ) \tilde W_i(t; t_0) + \alpha_i(t) \tilde w_i(t)\, , \quad \text{where} \quad \tilde w_i (t) = \frac{ w_i(t) }{ G(t) }\, .")
Notice, like before, 
Lemma 4. If 

 | \leq G(t_0) + \tilde W_i(t; t_0) G(t_0)\, .")
Proof. The result is somewhat similar to Lemma [Tsit:bdd]. At 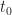
 | \leq M(t_0) \leq G(t_0)\, .") Now assuming that the bound is true at time
Now assuming that the bound is true at time
 & = (1-\alpha_i(t)) x_i(t) + \alpha_i(t) F_i(\bm x^i(t)) + \alpha_i(t) w_i(t) \\ \leq & (1-\alpha_i(t)) \{ G(t_0) + \tilde W_i(t;t_0) G(t_0) \} + \alpha_i(t) \gamma G(t_0) (1+\epsilon) + \alpha_i(t) \tilde w_i(t) G(t_0) \\ \leq & G(t_0) + [ (1-\alpha_i) \tilde W_i(t;t_0) + \alpha_i \tilde w_i(t) ] G(t_0)\, .\end{aligned}")
Above we bound 
Lemma 5. | = 0")
Proof. Since 
 | \mathcal F_t ] = 0 \quad \text{and} \quad \mathbb E [ \tilde w_i(t)^2 | \mathcal F_t ] \leq K\, .")
We know that 
 - W_i(t; t_0 ) & = (1 - \alpha_i(t) ) \Big[ W_i(t-1; 0 ) - W_i(t-1; t_0 ) \Big] \\ & =\dots = \prod_{s=t_0}^t (1-\alpha(s) ) \cdot W(t_0; 0)\, .\end{aligned}") Thus,
Thus,
 | \leq | W_i(t_0;0) | + | W_i(t;0)| \,.")
As required both terms on the righthand-side go to zero.
Proof of Prop 3. To prove the proposition we will show that
So we’d know by Lemma 5 that there exists a 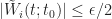
 | \leq G(t_0) + \tilde W_i(t; t_0) G(t_0) \leq G(t_0) (1+\epsilon/2) \, .")
Thus since 
Literature
The Robbin-Munro proceedure is due to Robbins and Munro and the Robbin Sigmund Theorem is due to Robbins and Sigmund. Good notes are given by Francis Bach. The Asynchronous implementation is due to Tsitsiklis, though we replace the a couple of results their with the Robbins-Sigmund theorem.
Robbins, Herbert; Monro, Sutton. A Stochastic Approximation Method. Ann. Math. Statist. 22 (1951), no. 3, 400–407. doi:10.1214/aoms/1177729586.
Robbins, Herbert, and David Siegmund. “A convergence theorem for non negative almost supermartingales and some applications.” Optimizing methods in statistics. Academic Press, 1971. 233-257.
Francis Bach. Optimisation et Apprentissage Statistique https://www.di.ens.fr/~fbach/orsay2019.html
Tsitsiklis, John N. “Asynchronous stochastic approximation and Q-learning.” Machine learning 16.3 (1994): 185-202.

One thought on “Robbins-Monro”