The Cross Entropy Method (CEM) is a generic optimization technique. It is a zero-th order method, i.e. you don’t gradients.1 So, for instance, it works well on combinatorial optimization problems, as well as reinforcement learning.
Continue reading “Cross Entropy Method”Category: Optimization
Lyapunov Functions
Lyapunov functions are an extremely convenient device for proving that a dynamical system converges. We cover:
- The Lyapunov argument
- La Salle’s Invariance Principle
- An Alternative argument for Convex Functions
- Exponential Convergence Rates
Kalman Filter
Kalman filtering (and filtering in general) considers the following setting: we have a sequence of states 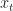
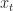
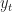

Bayesian Online Learning
We briefly describe an Online Bayesian Framework which is sometimes referred to as Assumed Density Filer (ADF). And we review a heuristic proof of its convergence in the Gaussian case.
Stochastic Linear Regression
We consider the following formulation of Lai, Robbins and Wei (1979), and Lai and Wei (1982). Consider the following regression problem,

for 
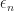

Typically for a regression problem, it is assumed that inputs 



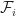

Robbins-Munro
We review the proof by Robbins and Munro for finding fixed points. Stochastic gradient descent, Q-learning and a bunch of other stochastic algorithms can be seen as variants of this basic algorithm. We review the basic ingredients of the original proof.
The Simplex Algorithm
The Simplex Theorem suggests a method for solving linear programs . It is called the Simplex Algorithm.
Linear Programming
A linear program is a constrained optimization problem with a linear objective, 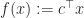
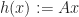
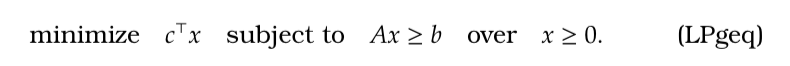
Experts and Bandits (non-stochastic)
- Weighted majority algorithm its variant for Bandit Problems.
