We consider a continuous time analogue of Markov Decision Processes.
Time is continuous 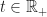


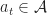
Def [Plant Equation] Given functions 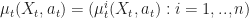
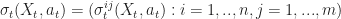
 dt + \sigma_t(X_t,a_t) \cdot d B_t")
where 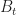
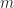
A policy 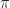
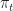
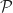



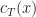

Def [Diffusion Control Problem] Given initial state 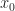
 Further, let
Further, let 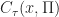
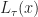
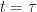
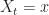

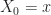
Def [Hamilton-Jacobi-Bellman Equation] For a Diffusion Control Problem , the equation + \partial_t L_t(x) + \mu_t(x,a)\cdot \partial_x L_t(x) + \frac{1}{2} [\sigma^\T \sigma]\cdot \partial_{xx} L_t(x) - \alpha L_t(x). \right\}") is called the Hamilton-Jacobi-Bellman equation.1 It is the continuous time analogue of the Bellman equation [[DP:Bellman]].
is called the Hamilton-Jacobi-Bellman equation.1 It is the continuous time analogue of the Bellman equation [[DP:Bellman]].
Heuristic Derivation of the HJB equation
We heuristically develop a Bellman equation for stochastic differential equations using our knowledge of the Bellman equation for Markov decision processes and our heuristic derivation of the Stochastic Integration. This is analogous to continuous time control.
Perhaps the main thing to remember is that (informally) the HJB equation is

Here Ito’s formula is applied to the optimal value function at time 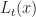
We suppose (for simplicity) that 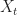

 \delta + \sigma_t(X_t,\pi_t) (B_{T+\delta}-B_t)")
for small 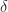
 \approx \mathbb{E} \Bigg[ \sum_{t\in \{0,\delta,...,T-\delta\}} \!\! (1-\alpha \delta)^{\frac{t}{\delta}} c_t(X_t,\pi_t) \delta + (1-\alpha \delta)^{\frac{T}{\delta}}c_T(X_T) \Bigg].")
This follows from the definition of a Riemann Integral and since 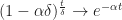
 = \min_{a\in\mathcal{A}} \left\{ c_t(x,a) \delta + (1-\alpha \delta) \mathbb{E}_{x, a} \left[L_{t+\delta}(X_{t+\delta})\right] \right\}.")
or, equivalently,
 + \frac{1}{\delta} \mathbb{E}_{x, a} \left[L_{t+\delta}(X_{t+\delta}) - L_t(x) \right] - \alpha \mathbb{E}_{x, a} \left[L_{t+\delta}(X_{t+\delta}) \right] \right\}.")
Now by Ito’s formula 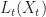
 - L_t(X_t)\\ \approx & \left[ \partial_t L + \mu_t(X_t,\pi_t) \cdot \partial_x L +\frac{\sigma_t(X_t,\pi_t)^2}{2} \partial_{xx} L \right] \delta + \partial_x L \cdot \sigma_t(X_t,\pi_t) \cdot (B_{t+\delta} - B_t) \end{aligned}")
Thus
 - L_t(x) \right] = \partial_t L + \mu_t(X_t,\pi_t) \cdot \partial_x L +\frac{\sigma_t(X_t,\pi_t)^2}{2} \partial_{xx} L")
Substituting in this into the above Bellman equation and letting 
 + \partial_t L + \mu_t(x,a) \cdot \partial_x L +\frac{\sigma_t(x,a)^2}{2} \partial_{xx} L - \alpha L_{t}(x) \right\}.")
The following gives a rigorous proof that the HJB equation is the right object to consider for a diffusion control problem.
Thrm [Davis-Varaiya Martingale Prinicple of Optimality] Suppose that there exists a function 
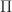
 + \int_{0}^{t} e^{-\alpha \tau} c_{\tau} (X_\tau, \Pi) d\tau")
is a sub-martingale and, moreover that for some policy 
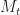
 = \min_{\Pi \in {\mathcal P}} \mathbb{E} \left[ \int_{0}^{T} e^{-\alpha \tau} c_{\tau} (X_\tau, \pi_\tau) d\tau + c_T(X_T) \right].")
Since
= M_0 \leq \mathbb E [M_T] = \underbrace{ \mathbb E_{X_0} \Big[ \int_0^T e^{-\alpha s} c_{\tau} (X_\tau , \Pi_\tau) d\tau + \underbrace{L_T(X_T)}_{C_T(X_T)} \Big] }_{ C(x_0,\Pi) } \end{aligned}") Therefore
Therefore 
If 
 =L_0(X_0) \leq C(X_0,\Pi)")
for all policies

- Here
is the dot-product of the Hessian matrix
with
. I.e. we multiply component-wise and sum up terms.↩
