For infinite time MDPs, we cannot apply to induction on Bellman’s equation from some initial state – like we could for finite time MDP. So we need some algorithms to solve MDPs.
At a high level, for a Markov Decision Processes (where the transitions 
- (Policy Improvement) Here you take your initial policy
and find a new improved new policy
, for instance by solving Bellman’s equation:
 \in \argmax_{a\in \mathcal A} \left\{ r(x,a) + \beta \mathbb{E}_{x,a} \left[ R(\hat{X},\pi_0) \right] \right\}")
- (Policy Evaluation) Here you find the value of your policy. For instance by finding the reward function for policy
 = \mathbb E^\pi_{x} \left[ \sum_{t=0}^\infty \beta r(X_t,\pi(X_t))\right]")
Value iteration
Value iteration provides an important practical scheme for approximating the solution of an infinite time horizon Markov decision process.
Def. Take 

 \in & \argmax_{a\in {\mathcal A} } \left\{ r(x,a) + \beta \mathbb{E}_{x,a} \left[ V_s(\hat{X}) \right] \right\} \\ V_{s+1}(x) & = \max_{a\in {\mathcal A} } \left\{ r(x,a) + \beta \mathbb{E}_{x,a} \left[ V_s(\hat{X}) \right] \right\}\end{aligned}")
for 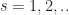
We can think of the two display equations above, respectively, as the policy improvement and policy evaluation steps. Notice, that we don’t really need to do the policy improvement step to do each iteration. Notice the policy evaluation step evalutes one action under the new policy 
The following result shows that Value Iteration converges to the optimal policy.
Thrm 1. For positive programming, i.e. where all rewards are positive and the discount factor 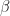
![(0,1]](https://s0.wp.com/latex.php?latex=%280%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 \leq V_{s+1}(x) \nearrow V(x), \quad \text{as}\quad s\rightarrow \infty\,.")
Here 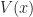
The following lemma is the key property for value iterations convergence, as well as a number of other algorithms.
Lemma 1. For reward function 
 = \max_{a\in {\mathcal A} } \left\{ r(x,a) + \beta \mathbb{E}_{x,a} \left[ R(\hat{X}) \right] \right\}.")
Show that if 


Proof. Clearly,
 + \beta \mathbb{E}_{x,a} \left[ R(\hat{X}) \right] \geq r(x,a) + \beta \mathbb{E}_{x,a} \left[ \tilde{R}(\hat{X}) \right].")
Now maximize both sides over 

Proof of Thrm 1. Note that 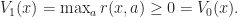

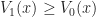
 \geq V_s(x)\, .")
Since 

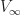

Next note that 
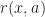



 \geq R_s(x,\Pi) \, .")
Now take limits 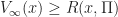

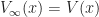
Ex. A robot is placed on the following grid.

The robot can chose the action to move left, right, up or down provided it does not hit a wall, in this case it stays in the same position. (Walls are colored black.) With probability 0.8, the robot does not follow its chosen action and instead makes a random action. The rewards for the different end states are colored above. Write a program that uses, Value Iteration to find the optimal policy for the robot.
Ans. Notice that the robot does not just take the shortest root. (I.e. some forward planning is required)

Policy Iteration
We consider a discounted program with rewards 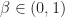
Def [Policy Iteration] Given the stationary policy 


 \in \argmax_{a\in{\mathcal A} } \; r(x,a) + \beta \mathbb{E}_{x,a} \left[ R(\hat{X},\Pi) \right]")
where 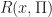

 = r(x,\mathcal I \Pi (x)) + \beta \mathbb{E}_{x,a} \left[ R(\hat{X},\mathcal I \Pi) \right]")
Policy iteration is the algorithm that takes

Starting from a stationary policy 
Thrm 2. Under Policy Iteration
 \geq R(x,\Pi_n)")
and, for bounded programming,
 \nearrow V(x) \qquad \text{as} \quad n \rightarrow \infty")
By the optimality of 
 = r(x,\pi(x)) + \beta \mathbb E_{x,\pi(x)} \left[ R(\hat{X},\Pi) \right] \leq r(x,\mathcal I \Pi (x)) + \beta \mathbb E_{x,\mathcal I \pi(x)} \left[ R(\hat{X},\Pi) \right]\end{aligned}")
Thus from the last part of Thrm 2 in Markov Chains: A Quick Review, we know that 
First note that
 + \beta \mathbb E_{x,a} \left[ R(\hat{X},\Pi) \right] & \leq r(x,\mathcal I \pi(x)) + \beta \mathbb E_{x,\mathcal I(x)} \left[ R(\hat{X},\Pi) \right] \\ & { \leq } r(x, \mathcal I \pi(x)) + \beta \mathbb E_{x,\mathcal I \Pi} \left[ R(\hat{X},\mathcal I \Pi) \right] = R(x,\mathcal I \Pi) .\end{aligned}")
We can use the above inequality to show that the following process is a supermartingale
 + \sum_{s=0}^{t-1} \beta^s r(X_s,\pi^*(X_s))")
where 

 + r(X_t, \pi^*(X)t) - R(X_t,\Pi_{T-t}) \Big| \mathcal F_t \right] \\ & = \beta^t \mathbb E^* \left[ \beta \mathbb E^*_{X_t,\pi^*(X_t)} \left[ \beta R(\hat{X},\Pi_{T-t-1}) + r(X_t,\pi^*(X_t)) - R(X_t,\Pi_{T-t}) \right] \Big| \mathcal F_t \right] \\ & \leq 0\, .\end{aligned}")
Since 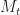

Therefore, as required,
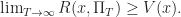
Ex. Write a program that uses, Policy iteration to find the optimal policy for the robot below:

Ans.
- Note we are implicity assuming an optimal stationary policy exists. We can remove this assumption by considering a
-optimal (non-stationary) policy. However, the proof is a little cleaner under our assumption.↩
