The Cross Entropy Method (CEM) is a generic optimization technique. It is a zero-th order method, i.e. you don’t gradients.1 So, for instance, it works well on combinatorial optimization problems, as well as reinforcement learning.
Continue reading “Cross Entropy Method”Category: Control
Stochastic Control Notes Update
I’ve updated the stochastic control notes here:
Stochastic_Control_2020_May.pdf
These still remain a work in progress.
(Typos/errors/mishaps found are welcome)
A quick summary of what is new:
- I’ve updated a section on the ODE method for stochastic approximation.
- I’ve improved the discussion around Temporal Difference methods and included some proofs.
- I’ve added a proof of convergence for SARSA.
- I’ve added a section on Lyapunov functions in continuous time
- La Salle, exponential convergence, and online convex optimization…
- I’ve started a section on Policy Gradients but there is more recent proofs to include
- I’ve started a section on Deep Learning for RL.
Lyapunov Functions
Lyapunov functions are an extremely convenient device for proving that a dynamical system converges. We cover:
- The Lyapunov argument
- La Salle’s Invariance Principle
- An Alternative argument for Convex Functions
- Exponential Convergence Rates
Kalman Filter
Kalman filtering (and filtering in general) considers the following setting: we have a sequence of states 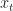
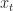
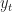

Temporal Difference Learning – Linear Function Approximation
For a Markov chain 
 := \mathbb E_{x} \left[ \sum_{t=0}^\infty r(\hat x_t) \right]")
associated with rewards given by 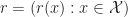

 = \bm w^\top \bm \phi (x) = \sum_{j\in \mathcal J} w_j \phi_j(x) .")
Continue reading “Temporal Difference Learning – Linear Function Approximation”
Stochastic Linear Regression
We consider the following formulation of Lai, Robbins and Wei (1979), and Lai and Wei (1982). Consider the following regression problem,

for 
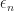

Typically for a regression problem, it is assumed that inputs 



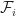

Foster-Lyapunov
Foster’s Lemma provides a natural condition to prove the positive recurrence of a Markov chain.
Experts and Bandits (non-stochastic)
- Weighted majority algorithm its variant for Bandit Problems.
More on Merton Portfolio Optimization
Diffusion Control Problems
- The Hamilton-Jacobi-Bellman Equation.
- Heuristic derivation of the HJB equation.
- Davis-Varaiya Martingale Prinicple for Optimality
