We briefly explain the principles behind dynamic programming and then give its definition.
An Introductory Example
In the figure below there is a tree consisting of a root node labelled  and two leaf nodes colored grey. For each edge, there is a cost. Your task is to find the lowest cost path from the root node to a leaf.
and two leaf nodes colored grey. For each edge, there is a cost. Your task is to find the lowest cost path from the root node to a leaf.

There are a number of ways to solve this, such as enumerating all paths. However, we are interested in one approach where the problem is solved backwards, through a sequence of smaller sub-problems. Specifically, once we reach the penultimate node on the left (in the dashed box) then it is clearly optimal to go left with a cost of  . This solves an easier sub problem and, after solving each sub problem, we can then attack a slightly bigger problem. If we solve for each leaf in this way we can solve the problem for the antepenultimate nodes (the node before the penultimate node).
. This solves an easier sub problem and, after solving each sub problem, we can then attack a slightly bigger problem. If we solve for each leaf in this way we can solve the problem for the antepenultimate nodes (the node before the penultimate node).
Thus the problem of optimizing the cost of the original tree can be broken down to a sequence of much simpler optimizations given by the shaded boxed below.
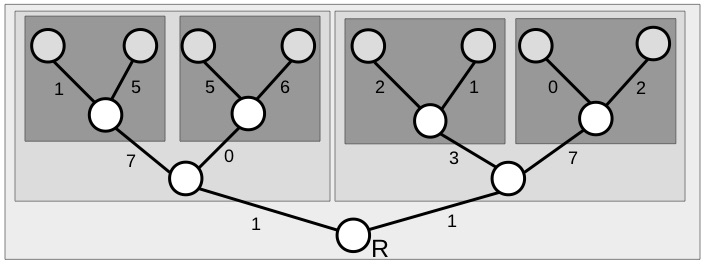
From this we see the optimal path has a cost of 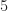 and consists of going right, then left, then right.
and consists of going right, then left, then right.
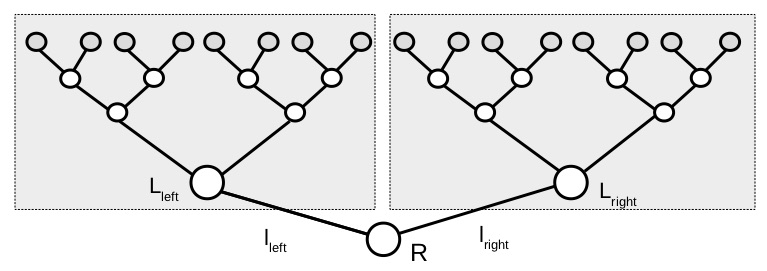
Let’s consider the problem a little more generally in the next figure. The tree on the righthand-side has a lowest cost path of value  and the lefthand-side tree has lowest cost
and the lefthand-side tree has lowest cost  and the edges leading to each, respective tree, have costs
and the edges leading to each, respective tree, have costs  and
and  . Once the decision to go left or right is made (at cost or ) it is optimal to follow the lowest cost path (at cost or ). So
. Once the decision to go left or right is made (at cost or ) it is optimal to follow the lowest cost path (at cost or ). So  , the minimal cost path from the root to a leaf node satisfies
, the minimal cost path from the root to a leaf node satisfies
Similarly, convince yourself that the same argument applies from any node  in the tree network that is
in the tree network that is
} \right\}.")
where  is the minimum cost from to a leaf node and where for
is the minimum cost from to a leaf node and where for 
 is the node to the lefthand-side or righthand-side of . The equation above is an example of the Bellman equation for this problem, and in our example, we solved this equation recursively starting from leaf nodes and working our way back to the root node.
is the node to the lefthand-side or righthand-side of . The equation above is an example of the Bellman equation for this problem, and in our example, we solved this equation recursively starting from leaf nodes and working our way back to the root node.
The idea of solving a problem from back to front and the idea of iterating on the above equation to solve an optimisation problem lies at the heart of dynamic programming.
Definition
We now give a general definition of a dynamic programming:
Time is discrete  ;
;  is the state at time
is the state at time  ;
;  is the action at time ; The state evolves according to functions
is the action at time ; The state evolves according to functions 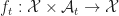 . Here
. Here
. \label{DP:Plant}\tag{Plant eq}")
This is called the Plant Equation. A policy 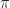 choses an action
choses an action 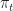 at each time . The (instantaneous) reward for taking action
at each time . The (instantaneous) reward for taking action  in state at time is
in state at time is  and
and  is the reward for terminating in state at time
is the reward for terminating in state at time  .
.
Def.[Dynamic Program] Given initial state 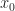 , a dynamic program is the optimization
, a dynamic program is the optimization 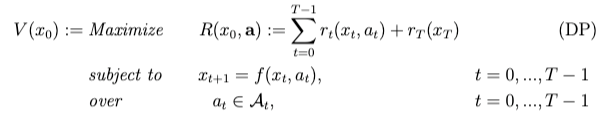
Further, let  (Resp.
(Resp. 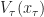 ) be the objective (Resp. optimal objective) for when the summation is started from
) be the objective (Resp. optimal objective) for when the summation is started from 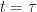 , rather than
, rather than  .
.
Thrm [Bellman’s Equation]  and for
and for 

where  and
and  .
.
Proof. Let  . Note that
. Note that 
 &= \max_{{\bf a}_t} \left\{ R_t(x_t,{\bf a}_t) \right\} = \max_{a_t} \max_{{\bf a}_{t+1}}\left\{ r_{t}(x_t,a_t) + R_{t+1}({x_{t+1},\bf a}_t) \right\} \\ &= \max_{a_t} \left\{ r_{t}(x_t,a_t) +\max_{{\bf a}_{t+1}} R_{t+1}(x_{t+1},{\bf a}_t) \right\} =\max_{a_t\in\mathcal{A}_t}\left\{ r_t(x_t,a_t) + V_{t+1} (x_{t+1}) \right\} . \end{aligned}")


One thought on “Dynamic Programming”