Thus far we have considered finite time Markov decision processes. We now want to solve MDPs of the form  = \maxi_{\Pi \in {\mathcal P} } \quad R(x,\Pi) := \mathbb{E}_{x_0} \left[ \sum_{t=0}^{\infty} \beta^{t} r(X_t,\pi_t) \right] \, .")
We can generalize Bellman’s equation to infinite time, a correct guess at the form of the equation would, for instance, be
 = \max_{a\in {\mathcal A}} \Big\{ r(x,a) + \beta {\mathbb E}_{x,a} \left[ V(\hat{X}) \right] \Big\}, \qquad x\in \mathcal X\, .")
Previously we solved Markov Decisions Processes inductively with Bellman’s equation. In infinite time, we can not directly apply induction; however, we see that Bellman’s equation still holds and we can use this to solve our MDP. For now we will focus on the case of discounted programming: here we assume that
 | < \infty \qquad \text{and} \qquad \beta \in (0,1)\, .")
We will cover cases where 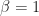
At this point it is useful define the concept of a 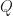


Def. [Q-Factor] The 
 = \mathbb E_{x,a} [ r(x,a) + \beta R(\hat{X}))]\, .")
Similarly the 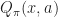

 =\max_{\pi} Q_{\pi}(x,a).")
The following result shows that if we have solved the Bellman equation then the solution and its associated policy is optimal.
Thrm. For a discounted program, the optimal policy 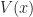
 = \max_{a\in {\mathcal A}} \Big\{ r(x,a) + \beta {\mathbb E}_{x,a} \left[ V(\hat{X}) \right] \Big\}.")
Moreover, if we find a function 
 = \max_{a\in {\mathcal A} } \left\{ r(x,a) + \beta \mathbb{E}_{x,a} \left[ R(\hat{X}) \right] \right\}")
then 
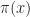
 \in \argmax_{a\in \mathcal A} \left\{ r(x,a) + \beta \mathbb E_{x,a} \left[ R(\hat{X}) \right] \right\}")
Then 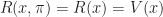
Proof. We know that ![R_t(x,\Pi) = r(x,\pi_0) + \beta \mathbb E [ R_{t-1}(\hat{X},\hat{ \Pi} ) ].](https://s0.wp.com/latex.php?latex=R_t%28x%2C%5CPi%29+%3D+r%28x%2C%5Cpi_0%29+%2B+%5Cbeta+%5Cmathbb+E+%5B+R_%7Bt-1%7D%28%5Chat%7BX%7D%2C%5Chat%7B+%5CPi%7D+%29+%5D.+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

 & = r(x,\pi_0) + \beta \mathbb E_{x,\pi_0} \left[ R(\hat{X},\hat{\Pi}) \right]\\ &\leq r(x,\pi_0) + \beta \mathbb E_{x,\pi_0} \left[ V(\hat{X}) \right]\,.\end{aligned}") For the inequality, above, we maximize
For the inequality, above, we maximize 
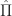
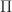
 \leq \sup_{\pi_0 \in {\mathcal A}} \left\{ r(x,\pi_0) + \beta \mathbb{E}_{x,\pi_0} \left[ V(\hat{X}) \right] \right\}.")
At this point we have that the Bellman equation but with an inequality. We need to prove the inequality in the other direction. For this, we let 
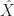
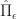
 \geq V(\hat{\Pi}) - \epsilon.")
We have that
 & \geq R(x,\pi_\epsilon) = r(x,a) + \beta \mathbb{E}_{x,a} \left[ R(\hat{X},\hat{\Pi}_\epsilon) \right] \\ & \geq r(x,a) + \beta \mathbb{E}_{x,a} \left[ V(\hat{X}) \right] - \epsilon \beta\end{aligned}")
The first inequality holds by the sub-optimality of 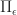

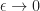
 \geq \max_{a\in {\mathcal A}} \Big\{ r(x,a) + \beta {\mathbb E}_{x,a} \left[ V(\hat{X}) \right] \Big\}.")
Thus we now have that
 = \max_{a\in {\mathcal A}} \Big\{ r(x,a) + \beta {\mathbb E}_{x,a} \left[ V(\hat{X}) \right] \Big\}.")
So at this point we know that the optimal value function satisfies the Bellman equation. For the next part of the result we need to show that the solution to this recursion is unique.
Suppose that 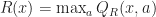
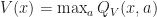
 - Q_R({x,a}) = \beta \mathbb E [ V(\hat{X}) - R(\hat{X}) ] = \beta \mathbb E [ \max_{a'} Q_V(\hat{X},a) - \max_{a'} Q_R(\hat{X},a') ]")
Thus
 - \max_{a'} Q_R(\hat{x},a') | \leq \beta || Q_V - Q_R ||_{\infty}\, .")
Since 

 = \max_a Q_R(x,a) = \max_a Q_V(x,a)=V(x)\, .")
So solutions to the Bellman equation are unique for discounted programming. Finally we must show that if we can find a policy that solves the Bellman equation, then it is optimal.
If we find a function
 = \max_{a\in {\mathcal A} } \left\{ r(x,a) + \beta \mathbb{E}_{x,a} \left[ R(\hat{X}) \right] \right\}, \quad \pi(x) \in \argmax_{a\in \mathcal A} \left\{ r(x,a) + \beta \mathbb E_{x,a} \left[ R(\hat{X}) \right] \right\}")
then note that the MDP induced by 

![R(x) = r(x,\pi(x)) + \beta \mathbb E_{x,\pi(x)} [ R(\hat{X})]](https://s0.wp.com/latex.php?latex=R%28x%29+%3D+r%28x%2C%5Cpi%28x%29%29+%2B+%5Cbeta+%5Cmathbb+E_%7Bx%2C%5Cpi%28x%29%7D+%5B+R%28%5Chat%7BX%7D%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
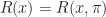

It is worth collating together a similar result for
Prop. a) Stationary
 = \mathbb E_{x,a} [ r(x,a) + \beta Q_{\pi}(\hat{X},\pi(\hat{X}) )]\, .")
b) Bellman’s Equation can be re-expressed in terms of
 = \mathbb E_{x,a} [ r(x,a) + \beta \max_{\hat{a}} Q^*(\hat{X},\hat{a}) )]\, .")
The optimal value function satisfies
 = \max_{a\in \mA} Q^*(x,a).")
c) The operation
 = \mathbb E_{x,a} [ r(x,a) + \beta Q_{\pi}(\hat{X},\pi(\hat{X}) )]\,")
is a contraction with respect to the supremum norm, that is,
 - \bm F ( \bm Q_2) ||_{\infty} \leq || \bm Q_1 - \bm Q_2 ||_{\infty}\, .")
Proof. a) We can think of extending the state space of our MDP to include states 
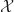



 = \mathbb E_{x,a} [ r(x,a) + \beta R(\hat{X},\pi )]")
where 
 = \mathbb E_{x,\pi(x)} [ r(x,\pi(x)) + \beta R(\hat{X},\pi )] = R(x,\pi )")
Thus, as required,
b) Further it should be clear that the optimal value function for the extended MDP discussed has a Bellman equation of the form
 &= \mathbb E_{x,a} [ r(x,a) + \beta V(\hat{X})] \\ V(x) & = \max_{a\in\mathcal A} \mathbb E_{x,a} [ r(x,a) + \beta V(\hat{X})]\end{aligned}")
Comparing the first equation above with the second, it should be clear that 
 = \mathbb E_{x,a} [ r(x,a) + \beta \max_{\hat{a}\in \mathcal A} Q^*(\hat{X},\hat{a}) )]\, .")
c) The proof of this part is already embedded in the previous Theorem. Note that
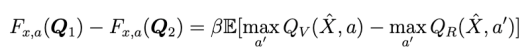
Thus
- \bm F(\bm Q_2) ||_{\infty} \leq \beta \max_{\hat{x}} | \max_{a} Q_1(\hat{x},a) - \max_{a'} Q_2(\hat{x},a') | \leq \beta || \bm Q_1 - \bm Q_2 ||_{\infty}\, ,") as required.
as required.

One thought on “Infinite Time Horizon”