The M/G/$\infty$ has Poisson arrivals and general service times; here, the number of jobs in service is Poisson distributed. Campbell’s theorem extends the proof idea by giving the moment generating function of sums taken over the points of a Poisson process.
Author: appliedprobability
Kingman’s Bound
We next describe an elegant and useful bound for a single-server queue (G/G/1) due to John Kingman:
![\displaystyle \mathbb E[w]\leq\frac{1}{2}\frac{\sigma_s^2+\sigma_a^2}{\bar s-\bar a}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5Bw%5D%5Cleq%5Cfrac%7B1%7D%7B2%7D%5Cfrac%7B%5Csigma_s%5E2%2B%5Csigma_a%5E2%7D%7B%5Cbar+s-%5Cbar+a%7D.&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Lindley’s Recursion and the G/G/1 Queue
Lindley’s recursion gives a useful formula relating waiting times in a queue to general inter-arrival and service times.
Consider a FIFO single-server queue. We define:
as the inter-arrival time between the
th and
th arrivals;
as the service time of the
as the waiting time of the
, with
.
Lindley’s Recursion
The waiting time of the

If 

The process 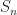
A Server with General Service: The M/G/1 Queue
We consider a queue with Poisson arrivals of rate 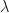

Continue reading “A Server with General Service: The M/G/1 Queue”
Renewal Processes and Residual Service
The assumption of exponential inter-arrival times is often reasonable. The Poisson process provides a useful model for many real-world systems when arrivals are drawn independently from a large population. However, the assumption of exponential service times is usually less realistic.
Exponential service times are a useful starting point because the resulting models can often be analysed using the well-developed theory of continuous-time Markov chains. These models allow us to understand the main features of a queueing system and build intuition before introducing more realistic service-time distributions.
Erlang Link and The Infinite Server Queue
The Erlang link and M/M/$\infty$ queue are models in which jobs do not wait. In the Erlang link, jobs are lost when all servers are busy, while in the M/M/$\infty$ queue every job begins service immediately.
Continue reading “Erlang Link and The Infinite Server Queue”
A Call Centre Queue (M/M/N)
Consider a queue where 

We can think of this as a simple model of a call centre. Some customers receive service immediately when there are idle servers. Otherwise, they must wait in the queue for the next available server.
Little’s Law
Little’s Law is such a fundamental result in queueing theory that it is called a “law.” It states that the average number of jobs in a system is equal to the average arrival rate multiplied by the average time spent in the system. It applies to any system involving waiting, provided that the system is not overloaded.
Little’s Law
For a queueing system in equilibrium,

where


We use the letter 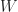
A single-server queue (M/M/1)
We consider what is perhaps the simplest and most tractable queueing model: a single-server queue with Poisson arrivals and exponential service times. This is called the M/M/1 queue.
Continue reading “A single-server queue (M/M/1)”Poisson Arrivals See Time Averages (PASTA)
We are often interested in the state an arriving customer observes in a queue. If arrivals are Poisson, then the average arrival sees the system in its equilibrium state.
This may seem counterintuitive. When a customer arrives, we might expect the system to be slightly emptier in anticipation of the arrival. However, this is not the case for Poisson processes: they are uniformly distributed over time, and arrivals after time 
