Markov decision processes are essentially the randomized equivalent of a dynamic program.
A Random Example
Let’s first consider how to randomize the tree example introduced.
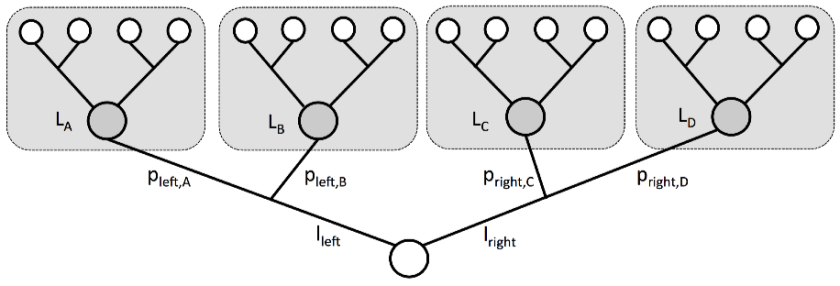
Below is a tree with a root node and four leaf nodes colored grey. At the route node you choose to go left or right. This incurs costs 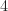 and
and 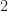 , respectively. Further, after making this decision there is a probability for reaching a leaf node. Namely, after going left the probabilities are
, respectively. Further, after making this decision there is a probability for reaching a leaf node. Namely, after going left the probabilities are 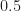 &
& 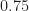 , and for turning right, the probabilities are
, and for turning right, the probabilities are  & . For each leaf node there is there is a cost, namely,
& . For each leaf node there is there is a cost, namely,  and
and  .
.
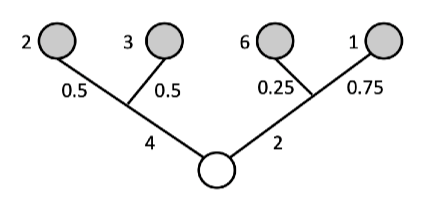
Given you only know the probabilities (and not what happens when you choose left or right), you’d want to take the decision with lowest expected cost. The expected cost for left is 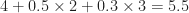 and for right is
and for right is  . So go right.
. So go right.
Below we now replace the numbers above with symbols. At the route node you can choose the action to go left or right. These, respective, decisions incur costs of  and
and  . After choosing left, you will move to state
. After choosing left, you will move to state  with probability
with probability  or to state
or to state  with probability
with probability  and similarly choosing right states
and similarly choosing right states  &
&  can be reached with probabilities
can be reached with probabilities  &
&  . After reaching node (resp. ,,) the total expected cost thereafter is
. After reaching node (resp. ,,) the total expected cost thereafter is  (resp.
(resp.  ,
,  ,
, 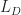 ).
).
Show that the optimal expected cost from the route node,  satisfies
satisfies

where here the random variable 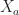 denotes the state in
denotes the state in 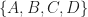 reached after action is taken. The cost from choosing “left“ is :
reached after action is taken. The cost from choosing “left“ is :

and the cost for choosing “right” is:

The optimal cost is the minimum of these two is
where here the random variable denotes the state in reached after action is taken. Notice how we abstracted away the future behaviour after arriving at , , , . Into a single cost for each state: , , , . And we can propagate this back to get the costs at the route state  . I.e. we can essentially apply the same principle as dynamic programming here.
. I.e. we can essentially apply the same principle as dynamic programming here.
Definitions
A Markov Decision Process (MDP) is a Dynamic Program where the state evolves in a random (Markovian) way.
Def [Markov Decision Process] Like with a dynamic program, we consider discrete times  , states
, states  , actions
, actions  and rewards
and rewards  . However, the plant equation and definition of a policy are slightly different.
. However, the plant equation and definition of a policy are slightly different.
Like with a Markov chain, the state evolves as a random function of the current state and action, ![f: \mathcal{X}\times \mathcal{A}_t \times [0,1] \rightarrow \mathcal{X}](https://s0.wp.com/latex.php?latex=f%3A+%5Cmathcal%7BX%7D%5Ctimes+%5Cmathcal%7BA%7D_t+%5Ctimes+%5B0%2C1%5D+%5Crightarrow+%5Cmathcal%7BX%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . Here
. Here
 \equiv f(X_t,a_t)")
where  are IIDRVs uniform on
are IIDRVs uniform on ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . This is called the Plant Equation.
. This is called the Plant Equation.
A policy 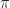 choses an action
choses an action 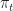 at each time
at each time  as a function of past states
as a function of past states  and past actions
and past actions 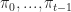 . We let
. We let 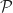 be the set of policies. A policy, a plant equation, and the resulting sequence of states and rewards describe a Markov Decision Process.
be the set of policies. A policy, a plant equation, and the resulting sequence of states and rewards describe a Markov Decision Process.
As noted in the equivalence above, we will usually suppress dependence on 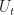 . Also, we will use the notation
. Also, we will use the notation
] = \mathbb{E} [G(F_t(x_t,a_t;U))] \quad\text{and} \quad \mathbb{E}_{x, a} [G(\hat{X})] = \mathbb E [ G(f(x,a;U))]")
where here and here after we use 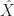 to denote the next state (after taking action
to denote the next state (after taking action  in state
in state  ). Notice in both equalities above, the term on the right depends on only one random variable,
). Notice in both equalities above, the term on the right depends on only one random variable, 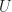 .
.
Objective is to find a process that optimizes the expected reward.
Def [Markov Decision Problem] Given initial state 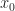 , a Markov Decision Problem is the following optimization
, a Markov Decision Problem is the following optimization  Further, let
Further, let 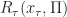 (Resp.
(Resp. 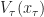 ) be the objective (Resp. optimal objective) for when the summation is started from time
) be the objective (Resp. optimal objective) for when the summation is started from time 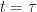 and state
and state  , rather than
, rather than  and
and 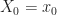 . We often call
. We often call 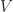 to value function of the MDP.
to value function of the MDP.
The next result shows that the Bellman equation follows essentially as before but now we have to take account for the expected value of the next state.
Def [Bellman Equation] Setting 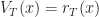 for
for 
 = \max_{a_t\in\mathcal{A}_t} \left\{ r_t(x_t,a_t) + \mathbb{E}_{x_t,a_t} \left[ V_{t+1}(X_{t+1})\right] \right\}.")
The above equation is Bellman’s equation for a Markov Decision Process.
Let 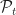 be the set policies that can be implemented from time to
be the set policies that can be implemented from time to  . Notice it is the product actions at time and the set of policies from time
. Notice it is the product actions at time and the set of policies from time  onward. That is
onward. That is  .
.
 &= \max_{\Pi_t \in \mathcal{P}_t} \mathbb{E}_{x_t \pi_t} \left[ \sum_{t=0}^{T-1} r_t(X_t,\pi_t) + r_T(X_T) \right]\\ &= \max_{\pi_t } \max_{\Pi \in \mathcal{P}_{t+1}} \Bigg\{ r_t(x_t,\pi_t) + \mathbb{E}_{x_t \pi_t} \Bigg[ \mathbb{E}_{X_{t+1} \pi_{t+1}} \Bigg[ \sum_{\tau=t+1}^{T-1} r_{\tau}(X_\tau,\pi_\tau) + r_T(X_T) \Bigg]\Bigg]\Bigg\}\\ &= \max_{a\in\mathcal{A} } \Bigg\{ r_t(x_t,a) + \mathbb{E}_{x_t\, a} \Bigg[ \underbrace{ \max_{\Pi \in \mathcal{P}_{t+1}} \mathbb{E}_{X_{t+1} \pi_{t+1}} \Bigg[ \sum_{\tau=t+1}^{T-1} r_{\tau}(X_\tau,\pi_\tau) + r_T(X_T) \Bigg] }_{ =V_{t+1}(x_{t+1}) } \Bigg]\Bigg\} \end{aligned}") 2nd equality uses structure of , takes the
2nd equality uses structure of , takes the  term out and then takes conditional expectations. 3rd equality takes the supremum over
term out and then takes conditional expectations. 3rd equality takes the supremum over  , which does not depend on , inside the expectation and notes the supremum over is optimized at a fixed action
, which does not depend on , inside the expectation and notes the supremum over is optimized at a fixed action  (i.e. the past information did not help us.)
(i.e. the past information did not help us.)
Ex. You need to sell a car. At every time 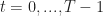 , you set a price
, you set a price  and a customer then views the car. The probability that the customer buys a car at price
and a customer then views the car. The probability that the customer buys a car at price  is
is  . If the car isn’t sold be time then it is sold for fixed price
. If the car isn’t sold be time then it is sold for fixed price  ,
,  . Maximize the reward from selling the car and find the recursion for the optimal reward when
. Maximize the reward from selling the car and find the recursion for the optimal reward when  .
.
Ex. You own a call option with strike price . Here you can buy a share at price making profit  where
where 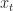 is the price of the share at time . The share must be exercised by time . The price of stock
is the price of the share at time . The share must be exercised by time . The price of stock 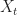 satisfies
satisfies  for
for 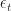 IIDRV with finite expectation. Show that there exists a decresing sequence
IIDRV with finite expectation. Show that there exists a decresing sequence  such that it is optimal to exercise whenever
such that it is optimal to exercise whenever  occurs.
occurs.
Ex. You own an expensive fish. Each day you are offered a price for the fish according to a distribution density 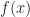 . You make the accept or reject this offer. With probability
. You make the accept or reject this offer. With probability  the fish dies that day. Find the policy that maximizes the profit from selling fish.
the fish dies that day. Find the policy that maximizes the profit from selling fish.
Ex. Consider an MDP where rewards are now random, i.e. after we have specified the state and action the reward 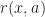 is still an independent random variable. Argue that this is the same as a MDP with non-random rewards given by
is still an independent random variable. Argue that this is the same as a MDP with non-random rewards given by  = \mathbb E [r(x,a)]")
Ex. Indiana Jones is trapped in a room in a temple. There are  passages that he can try and escape from. If he attempts to escape from passage
passages that he can try and escape from. If he attempts to escape from passage 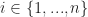 then either: he esacapes with probability
then either: he esacapes with probability  ; he dies with probability
; he dies with probability  ; or with probability
; or with probability  the passage is a deadend and he returns to the room which he started from. Determine the order of passages which Indiana Jones must try in order to maximize his probability of escape.
the passage is a deadend and he returns to the room which he started from. Determine the order of passages which Indiana Jones must try in order to maximize his probability of escape.
Ex. You invest in properties. The total value of these properties is in year  .
.
Each year , you gain rent of  and you choose to consume a proportion
and you choose to consume a proportion ![a_t\in [0,1]](https://s0.wp.com/latex.php?latex=a_t%5Cin+%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) of this rent. The remaining proportion is reinvested in buying new property.
of this rent. The remaining proportion is reinvested in buying new property.
Further you pay mortgage payments of 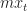 which are deducted from your consumed wealth. Here
which are deducted from your consumed wealth. Here  .
.
Your objective is to maximize the wealth consumed over years.
Briefly explaining why we can express this problem as a finite time dynamic program with
=x + rx(1-a),\qquad r_t(x,a) = x(ra-m),\qquad r_T(x)=0\ ,")
prove that if  for some constant
for some constant 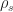 then
then
\rho_{s-1} -m \} .")

2 thoughts on “Markov Decision Processes”