Q-learning is an algorithm, that contains many of the basic structures required for reinforcement learning and acts as the basis for many more sophisticated algorithms. The Q-learning algorithm can be seen as an (asynchronous) implementation of the Robbins-Monro procedure for finding fixed points. For this reason we will require results from Robbins-Monro when proving convergence.
A key ingredient is the notion of a 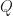



 = \mathbb E_{x,a} [ r(x,a) + \beta \max_{\hat{a}} Q(\hat{X},\hat{a}) )]\, .")
Def. [Q-learning] Given a state 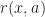
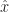
 \xleftarrow[]{\alpha} r(x,a) + \beta \max_{a'\in \mathcal A} Q(\hat{x},a') - Q(x,a)")
where 
![x \xleftarrow[]{\alpha} dx](https://s0.wp.com/latex.php?latex=x+%5Cxleftarrow%5B%5D%7B%5Calpha%7D+dx&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
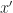

To implement this as an algorithm, we assume that we have a sequence of state-action-reward-next_state quadruplets 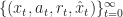
Thrm 1. For a sequence of state-action-reward triples 
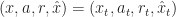
 = Q_t(x,a) + \alpha_t ( x,a) \left( r + \max_{a'} Q_t(x',a') - Q_t(x,a) \right)")
if the sequence of state-action-reward triples visits each state and action infinitely often, and if the learning rate 
 = \infty , \qquad \sum_{t=1}^\infty \alpha^2_t(x,a) < \infty")
then, with probability 
 \rightarrow Q^*(x,a)")
where 
Proof. We essentially show that the result is a consequence of Theorem 3 in Robbins-Monro. We note that the optimal 
\, ,")
with
![]()
for each 


 - \bm F ( \bm Q_2) ||_{\infty} \leq \beta || \bm Q_1 - \bm Q_2 ||_{\infty} \, .")
Now notice that the
 =Q_t(x,a) + \alpha_t(x,a) ( F(\bm Q)(x,a) - Q_t(x,a) + \epsilon(x,a)) \, ,")
where = r + \beta \max_{\hat{a}} Q(\hat{X},\hat{a}) - \mathbb E_{x,a} [ r(x,a) + \beta \max_{\hat{a}} Q(\hat{X},\hat{a}) ]")
for 
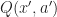


 | \mathcal F_t] = 0")
and, a quick calculation shows,1 that
^2 | \mathcal F_t] \leq 2 r^2_{\max} + 2 \beta^2 \max_{x,a} Q_t(x,a)^2 \, .")
From this we see that we are working in the setting of Theorem 3 in Robbins-Monro and that the conditions of that theorem are satisfied. Thus it must be that
 \xrightarrow[t\rightarrow\infty ]{} Q^*(x,a)")
where 

Literature.
The argument here is depends heavily on the fixed point results. But the main source used is
Tsitsiklis, John N. “Asynchronous stochastic approximation and Q-learning.” Machine learning 16.3 (1994): 185-202.
- Note
↩
