Discrete time Dynamic Programming was given in the post Dynamic Programming. We now consider the continuous time analogue.
Time is continuous 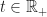


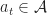

.")
This is called the Plant Equation. A policy 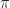
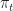





Def [Dynamic Program] Given initial state 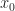

Further, let 

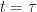

When a minimization problem where we minimize loss given the costs incurred is replaced with a maximization problem where we maximize winnings given the rewards received. The functions 




Def [Hamilton-Jacobi-Bellman Equation] For a continuous-time dynamic program , the equation
+ \partial_t L_t(x) + f_t(x,a)\partial_x L_t(x) - \alpha L_t(x). \right\}")
is called the Hamilton-Jacobi-Bellman equation. It is the continuous time analogoue of the Bellman equation.
A Heuristic Derivation of the HJB Equation
We now argue why the Hamiliton-Jacobi-Bellman equation is a good candidate for the Bellman equation in continuous time.
A good approximation to the plant equation is
")
for 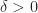
 := \sum_{t\in\{0,\delta,...,(T-\delta)\} } (1-\alpha \delta)^{ {t}/{\delta}}c_t(x_t,a_t) \delta + (1-\alpha \delta)^{ {t}/{\delta}}c_T(x_T) \end{aligned}") This follows from the definition of the Riemann Integral and we further use the fact that
This follows from the definition of the Riemann Integral and we further use the fact that 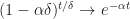

The Bellman equation for the discrete time dynamic program with objective and plant equation is
 = \min_{a\in \mathcal{A}}\left\{ c_t(x,a)\delta + (1-\alpha \delta) L_{t+\delta}(x_t+\delta f_t(x,a)) \right\}")
If we minus 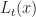
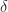
+ \partial_t L_t(x) + f_t(x,a)\partial_x L_t(x) - \alpha L_t(x)\, , \right\}")
where here we note that, by the Chain rule,
 L_{t+\delta}(x+\delta f) - L_t(x)}{\delta} \xrightarrow[\delta \rightarrow 0]{ }\partial_t L_t(x) + f_t(x,a)\partial_x L_t(x) - \alpha L_t(x).")
Thus we derive the HJB equation as described above.
The following result shows that if we solve the HJB equation then we have an optimal policy.
Thrm 1 [Optimality of HJB] Suppose that a policy 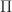

Proof. Using shorthand 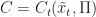
\right)&=e^{-\alpha t} \left\{ c_t(\tilde{x}_t,\tilde{\pi}_t) - \left[ c_t(\tilde{x}_t,\tilde{\pi}_t) - \alpha C + f_t(\tilde{x}_t,\tilde{\pi}_t) \partial_x C + \partial_t C\right]\right\}\\ &\leq e^{-\alpha t} c_t(\tilde{x}_t,\tilde{\pi}_t) \end{aligned}") The inequality holds since the term in the square brackets is the objective of the HJB equation, which is not maximized by
The inequality holds since the term in the square brackets is the objective of the HJB equation, which is not maximized by 

Linear Quadratic Regularization
Def. [LQ problem] We consider a dynamic program of the form

Here 



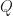
Def [Riccarti Equation] The differential equation with
 = -Q-\Lambda(t)A - A^\top \Lambda(t) + \Lambda(t) B R^{-1} B^{\top} \Lambda(t)\quad and\quad \Lambda(T)=Q_T.") is called the Riccarti equation.
is called the Riccarti equation.
Thrm 2. For each time
 x_t \, ,")
where 
Proof. The HJB equation for an LQ problem is
 + (Ax + Ra)^\top \partial_x L_t(x) \right\}")
We now “guess” that the solution to above HJB equation is of the form 
 = 2 \Lambda(t) x \quad \text{and} \quad \partial_t L_t(x) = x^\top \dot{\Lambda}(t) x")
Substituting into the Bellman equation gives
 x + 2 x^\top \Lambda(x) ( A x + B a) \right\}\, .")
Differentiating with respect to
 B =0") which implies
which implies
 x\, .")
Finally substituting into the Bellman equation, above, gives the expression
+ \Lambda(t)A + A^\top \Lambda(t) - \Lambda(t) B R^{-1} B^{\top} \Lambda(t) -Q \right]x\,.")
Thus the solution to the Riccarti equation has a cost function that solves the Bellman equation and thus by Theorem 1 the policy is optimal.

One thought on “Continuous Time Dynamic Programming”