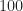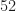Probabilities for a Markov chain can be expressed in terms of the probability vector 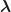
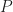
For example, for 


![\displaystyle \mathbb{P}(X_t = x) = [\lambda P^t]_x](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BP%7D%28X_t+%3D+x%29+%3D+%5B%5Clambda+P%5Et%5D_x&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\displaystyle \mathbb{E}_x[r(X_t)] = (P^t r)_x](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D_x%5Br%28X_t%29%5D+%3D+%28P%5Et+r%29_x&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
So essentially, multiplication to the left gives probabilities and multiplication to the right gives expectations.
Notation explanation. If the above is unclear, some notation may need explaining. For 


![[\boldsymbol{\lambda} P^t]_x](https://s0.wp.com/latex.php?latex=%5B%5Cboldsymbol%7B%5Clambda%7D+P%5Et%5D_x&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

Similarly, we can think of the function 


Throughout these notes, 
![\mathbb{E}_x[\cdot] = \mathbb{E}[\cdot \mid X_0 = x]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_x%5B%5Ccdot%5D+%3D+%5Cmathbb%7BE%7D%5B%5Ccdot+%5Cmid+X_0+%3D+x%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
1 We use 
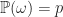
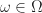
 = \sum_{\omega \in \Omega } p= |\Omega | p") (where
(where 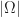
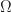
 = \frac{1}{| \Omega |} \,\qquad \text{ for all } \omega \in \Omega .\end{aligned}")