Let’s explain why the normal distribution is so important.
(This is a section in the notes here.)
Suppose that I throw a coin 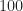 times and count the number of heads
times and count the number of heads 
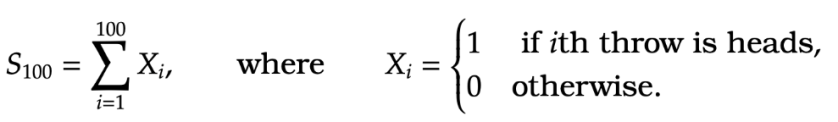
The proportion of heads should be close to its mean  and for
and for  it should be even closer. This can be shown mathematically (not just for coin throws but for quite general random variables)
it should be even closer. This can be shown mathematically (not just for coin throws but for quite general random variables)
Theorem [Weak Law of Large Numbers] For independent random variables 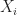 ,
, 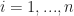 , with mean
, with mean  and variance bounded above by
and variance bounded above by 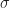 , if we define
, if we define

then for all 

\xrightarrow[n\rightarrow \infty ]{} 1 \, .\end{aligned}")
We will prove this result a little later. But, continuing the discussion, suppose 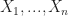 are independent identically distributed random variables with mean and variance
are independent identically distributed random variables with mean and variance 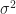 . We see from the above result that
. We see from the above result that  is getting close to . Nonetheless, in general, there is going to be some error. So let’s define
is getting close to . Nonetheless, in general, there is going to be some error. So let’s define
 So what does
So what does 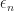 look like? We know that, in some sense,
look like? We know that, in some sense, 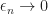 as
as  but how fast?
but how fast?
For this we can analyze the variance of the random variable :  = \mathbb V \left(
\frac{S_n-n \mu}{n}
\right)
=&
\frac{1}{n^2} \mathbb V \left(
S_n - n \mu
\right)
\notag
\\
=
&
\frac{1}{n^2} \mathbb V \left(
\sum_{i=1}^n (X_i - \mu)
\right)
\notag
\\
=
&
\frac{1}{n^2} \sum_{i=1}^n \underbrace{ \mathbb V( X_i - \mu)}_{= \sigma^2}
=
\frac{\sigma^2}{n}
%\end{aligned}")

Thus the standard deviation of decreases as  . Given this we can define
. Given this we can define 

Notice that ![\mathbb E [Z_n]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E+%5BZ_n%5D%3D0&bg=ffffff&fg=1a1a1a&s=0&c=20201002) and
and  = \frac{n}{\sigma} \mathbb V(\epsilon_n) = 1.
%\end{aligned}")

So 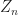 has mean zero and its variance is fixed. I.e. the error as measured by is not vanishing, but is staying roughly constant. So it seems like there is sometime happening for this random variable , a question is what happens to . The answer is that converges to a normal distribution.
has mean zero and its variance is fixed. I.e. the error as measured by is not vanishing, but is staying roughly constant. So it seems like there is sometime happening for this random variable , a question is what happens to . The answer is that converges to a normal distribution.
This is a famous and fundamental result in probability and statistics called the central limit theorem.
Theorem [Central Limit Theorem] For independent random variables with mean and variance , for  and
and
 then
then  \xrightarrow[n \rightarrow \infty ]{} \mathbb P ( Z \leq z)
%\end{aligned}")
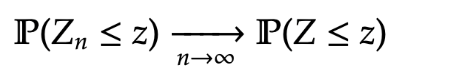
where 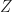 is a standard normal random variable.
is a standard normal random variable.
Given the discussion above the Central Limit Theorem, roughly says that 
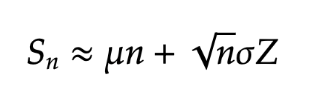
where is a standard normal random variable. So whenever we measure errors about some expected value we should start to consider normal random variables.
