(This is a section in the notes here.)
Conditional probabilities are probabilities where we have assumed that another event has occurred.
An example: Two aces. Suppose we have a deck of cards and we consider the probability of getting an ace. If we take one card out, then the probability of an ace is 
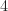
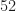
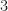
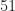


Motivating a definition of conditional probability. Recall that we thought of probability as \, .
\label{probconv2}
%\end{aligned}")
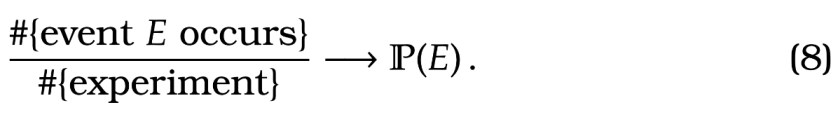
Similarly, as we think of conditional probability as the proportion of time that an event occurs knowing that an other event has occurred. In this case, an analogous statement would be that \, .
%\end{aligned}")
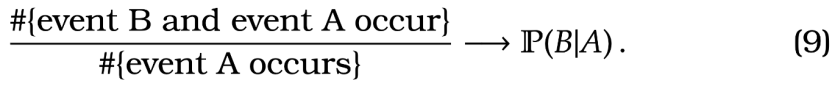
where here we use 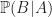


Observe, that we can express (9) in terms of (8). In particular, }{\mathbb P( A)}
%\end{aligned}")
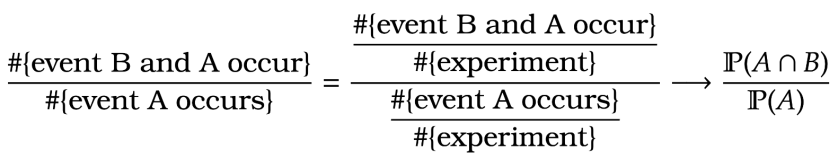
Here we divide the denominator and numerator from the left hand side of by the number of experiments and then we apply to both expressions.
This motivates the following

Definition of conditional probability. Given the above we have:
Definition [Conditional Probability] For events  :=
\frac{
\mathbb P ( A \cap B)
}{
\mathbb P(A)
}
%\end{aligned}")
when 


A couple of examples.
Example. The results of a survey of 250 different 75 year-olds is given in the following Venn diagram.
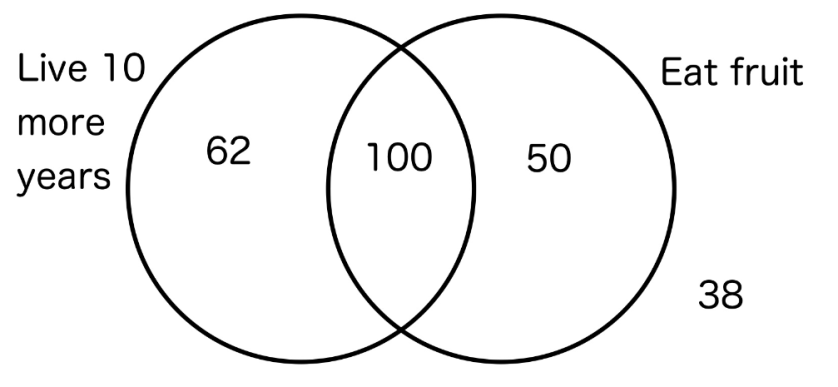
For a randomly selected participant in the survey:
1) Calculate the probability living 10 more years given that they eat fruit.
2) Calculate the probability living 10 more years given that they don’t eat fruit.
Answer. 1) = \frac{100}{100 +50} = 0.667
%\end{aligned}")

2) = \frac{62}{62+38} = 0.62
%\end{aligned}") So you should eat fruit…
So you should eat fruit…

Example. I have two siblings, given I have a brother, what is the probability that I also have a sister.
Answer. Note that our sample space is 


 = \frac{ \mathbb P (BS) + \mathbb P(SB) }{\mathbb P(BB)+\mathbb P (BS) + \mathbb P(SB)} = \frac{2/4}{3/4} = \frac{2}{3}
%\end{aligned}")
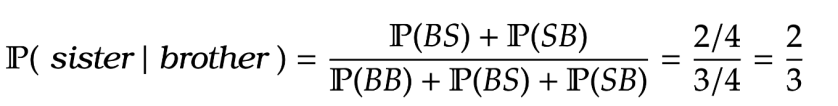
For some this is an example of conditional probability being a bit counter-intuitive, as ones gut reaction is that the answer is a half. Notice if I specified that my eldest sibling was a brother then the answer would indeed be a half. This is just one small example of the subtle art of manipulating conditional probabilities.
Independence
We are interested in the setting where knowing that an event has occurred does not affect another event. E.g. if I roll a dice twice, in principle the outcome of the first roll should not influence the second roll. If event  = \mathbb P(B)
%\end{aligned}")

I.e. conditioning on 
 = \mathbb P (A) \times \mathbb P(B)\, .
%\end{aligned}")

This is what we call independence of two events.
Definition [Independence] We say that events  = \mathbb P(A) \mathbb P(B) \,.
%\end{aligned}")
So if knowing that
Warning! The following is sometimes confused by students. We say that two events are “mutually exclusive” if 
As discussed, independence says that knowing an outcome is in
Example. What is the probability of getting 
Answer. Since with multiple probabilities together  &=
\mathbb P(H)
\mathbb P(H)
\mathbb P(H)
\mathbb P(H)
\mathbb P(H)
\mathbb P(H)
\mathbb P(H)
\mathbb P(H)
\mathbb P(H)
\mathbb P(H)
\\
&
= \bigg(\frac{1}{2}\bigg)^{10}
= \frac{1}{1024} \,.
%\end{aligned}")
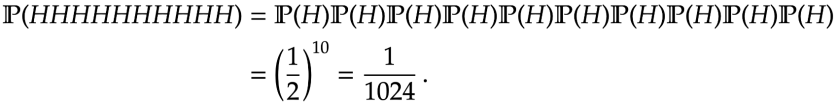
This is actually a “magic trick”. Notice there are 

Rules for Conditional Probabilities
Here are few useful formulas for Conditional Probabilities. (Like with operations on sets the proofs are not entirely necessary to know for exams.)
Lemma 1.
 = \mathbb P ( B | A ) \mathbb P(A)")
Proof. Follows immediately from the definition of 
This is useful as it can be easier to find
Lemma 2.
 = \mathbb P(B | A ) \mathbb P(A)+ \mathbb P (B | A^c) \mathbb P(A^c)")
Proof. Since 


=
\mathbb P(B \cap A )
+
\mathbb P(B \cap A^c)
%\end{aligned}") and then applying Lemma 1
and then applying Lemma 1
gives
=
\mathbb P(B | A ) \mathbb P(A)
+
\mathbb P(B | A^c) \mathbb P(A^c)
%\end{aligned}") as required.
as required.
Note that the above result can be applied to any number of sets 



 = \sum_{i=1}^n \mathbb P( B | A_i) \mathbb P(A_i)\, .
%\end{aligned}")

Lemma 3 [Bayes’ Rule] 
=
\frac{\mathbb P(A | B ) \mathbb P(B) }{\mathbb P(A)}
%\end{aligned}")

The result is sometimes called Bayes’ Theorem, as well.
 = \frac{\mathbb P(A \cap B)}{\mathbb P(A) }
=
\frac{\mathbb P ( A \cap B) }{ \mathbb P(B)}
\frac{ \mathbb P (B) }{ \mathbb P (A) }
= \frac{\mathbb P (A | B ) \mathbb P(B)}{\mathbb P(A)} \, .
%\end{aligned}")
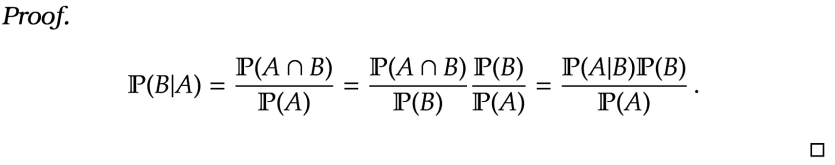
Bayes’ Rule reverses the order of the conditional probability. There is a whole branch of statistics developed to this which we will very briefly touch upon shortly.
Example [Two aces] Taking out two cards from a well-shuffled deck. What is the probability that both cards are aces? What is the probability that the 2nd card is an ace?
Answer. We know that 
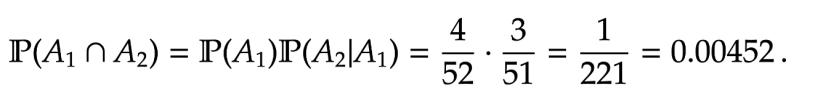

=
\mathbb P(A_1) \mathbb P( A_2 |A_1)
=
\frac{4}{52} \cdot \frac{3}{51} = \frac{1}{221} = 0.00452 \, .
%\end{aligned}") For the 2nd part, we can apply Lemma 7. Here
For the 2nd part, we can apply Lemma 7. Here 
&
=
\mathbb P ( A_2 | A_1 )
\mathbb P(A_1)
+
\mathbb P(A_2 | A_1^c)
\mathbb P(A_2^c)
\\
&
=
\frac{4}{52} \cdot \frac{3}{51}
+
\frac{48}{52}
\cdot
\frac{4}{51}
=
\frac{1}{13} .
%\end{aligned}")
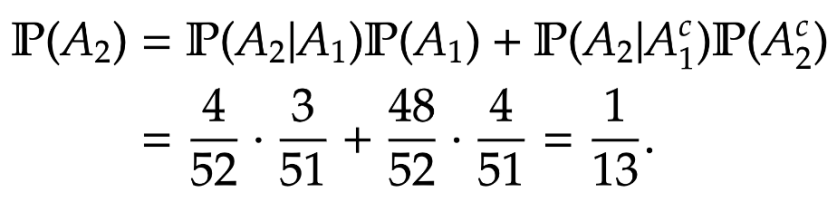
This should come as no surprise, as the probability that the 2nd card is an ace should be the same as the probability that the 1st card is an ace. (Imagine taking the first card out the pack and putting it to the back, and then taking the 2nd card out and looking at it.)
Example [Frequentist vs Bayesian Statistics] I have a biased coin, it is biased so the probability of heads, 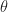
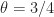

Answer. This is clearly not a well-defined question, because we cannot determine with certainty the value of
The Frequentist Answer. The likelihood of three heads for both choices of
 = \left(
\frac{1}{4}
\right)^3
\quad
\text{and}
\quad %
\mathbb P ( HHH | \theta = {3}/{4} ) = \left(
\frac{3}{4}
\right)^3\, .\end{aligned}") The parameter that gives the highest probability is
The parameter that gives the highest probability is 

The Bayesian Answer. Since we don’t know in prior to throwing the coin, which of the two possibilities hold. We could give each possibility equal likelihood that is  = \mathbb P ( \theta = 3/4) = \frac{1}{2}
%\end{aligned}")

This is called the prior distribution. After throwing the coin and getting three heads then we want to update our estimate to find  \quad \text{and} \quad \mathbb P ( \theta = 3/4 | HHH) %\end{aligned}")

This called the posterior distribution. We can use Bayes’ Rule to calculate the posterior: 
&
= \mathbb P ( HHH | \theta = 3/4) \frac{\mathbb P ( \theta = 3/4) }{ \mathbb P (HHH) }
\notag \\
&
=
\left(
\frac{3}{4}
\right)^3 \frac{\frac{1}{2} }{ \mathbb P (HHH)} \label{Bayes1}
%\end{aligned}")

To calculate 
 =& \mathbb P ( HHH | \theta = 3/4) \mathbb P (\theta = 3/4) +
\mathbb P ( HHH | \theta = 1/4) \mathbb P (\theta = 1/4)
\notag
\\
=
&
\left(
\frac{3}{4}
\right)^3 {\frac{1}{2} }
+
\left(
\frac{1}{4}
\right)^3 {\frac{1}{2} }
=\frac{28}{128}\end{aligned}") which then gives with (10) that
which then gives with (10) that

and thus 
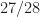
Under reasonable assumptions and enough data both the Bayesian and Frequentist approaches will converge on the correct parameter. The choice of the prior in the Bayesian approach is quite subjective. When the range of parameters gets large (or continuous) then we need to solve an optimization problem in the frequentist approach, while in the Bayesian approach we need to sum over a large number of terms to find the normalizing constant, which was the 
