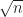Often we are interested in the magnitude of an outcome as well as its probability. E.g. in a gambling game amount you win or loss is as important as the probability each outcome.
(This is a section in the notes here.)
Definition [Random Variable] A random variable is a function 
For example, if we roll two dice then 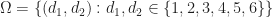
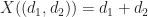
Random variables (RVs) can be discrete, e.g. taking values 

Typically we use capital letters to denote random variables 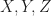
 = \frac{1}{36} \, ,
%\end{aligned}")
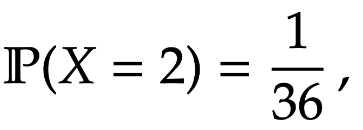
where here by 

Discrete Probability Distributions. A key way to characterize a random variable is with its distribution.
Definition [Probability Mass Function]The probability distribution of a discrete random variable 

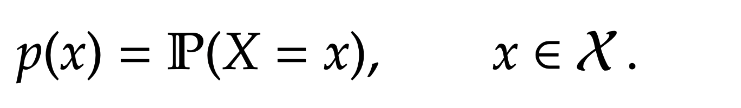
 = \mathbb P(X=x), \qquad x \in \mathcal X\, .
%\end{aligned}") This is some times called the probability mass function (PMF). Notice it satisfies the properties
This is some times called the probability mass function (PMF). Notice it satisfies the properties
- (Positive) For all
,
 \geq 0")
- (Sums to one)
 = 1\, .")
Another way to characterize the distribution of the a random variable is through its cumulative distribution function, which is simply gives the probability that the random variable is below a given value.
Definition [Cumulative Distribution Function] The cumulative distribution function (CDF) of a random variable
 := \mathbb P( X \leq x)\, , \end{aligned}")

We can define more than one random variable on the same probability space. E.g. from our two dice throws, 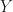
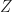
Definition [Joint Probability Distribution] Suppose there are two random variables defined on the same probability space, 

:= \mathbb P ( X = x, Y= y),
%\end{aligned}")
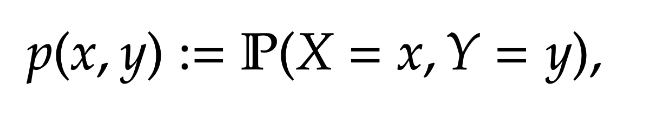
for 
Definition [Independent Random Variables] We say that  = \mathbb P(X=x) \cdot\mathbb P(Y=y)
%\end{aligned}")
![]()
for all 
We can extend the about definition to any number of random variables. E.g. a set of random variable 
 =
\prod_{i=1}^n \mathbb P(X_i = x_i) \, .
%\end{aligned}")
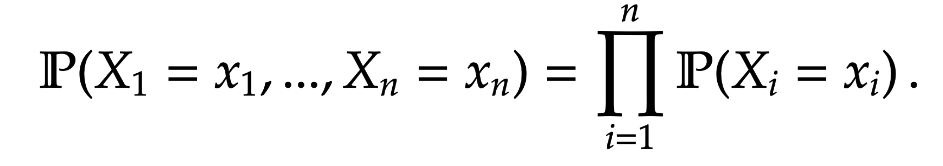
A common situtation that we are interested in is where 

Expectation and Variance
Definition. The expectation of a discrete random variable  \, .
%\end{aligned}")
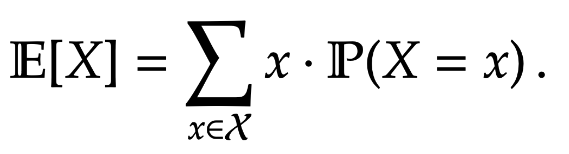
The expectation gives an average value of the random variable. We could think of placing one unit of mass along the number line, where at point 

![\mathbb E[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Example. Calculate the expectation for the following random variable 

Answer.

Properties of the expectation
Here are various properties of the expectation. Proofs are included and are good to know but are not essential reading for exams. (For the most part the following lemmas are really properties of summation.)
Lemma 1. For a function 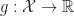
 ] = \sum_{x \in \mathcal X} g(x) \mathbb P(X=x) \, .
%\end{aligned}")
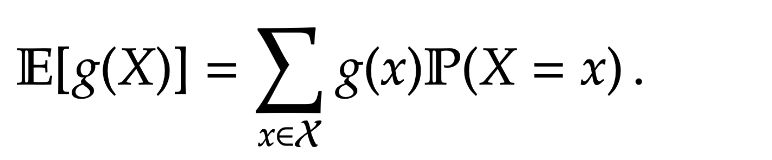
 ]
=&
\sum_y y\mathbb P(g(X) = y)
\notag
\\
=
&
\sum_y y \sum_{x : g(x) =y } \mathbb P(X=x)
\notag
\\
=
&
\sum_y \sum_{x : g(x) = y} g(x) \mathbb P (X =x)
\notag
\\
=
&
\sum_x g(x) \mathbb P(X=x) \, .
%\end{aligned}")
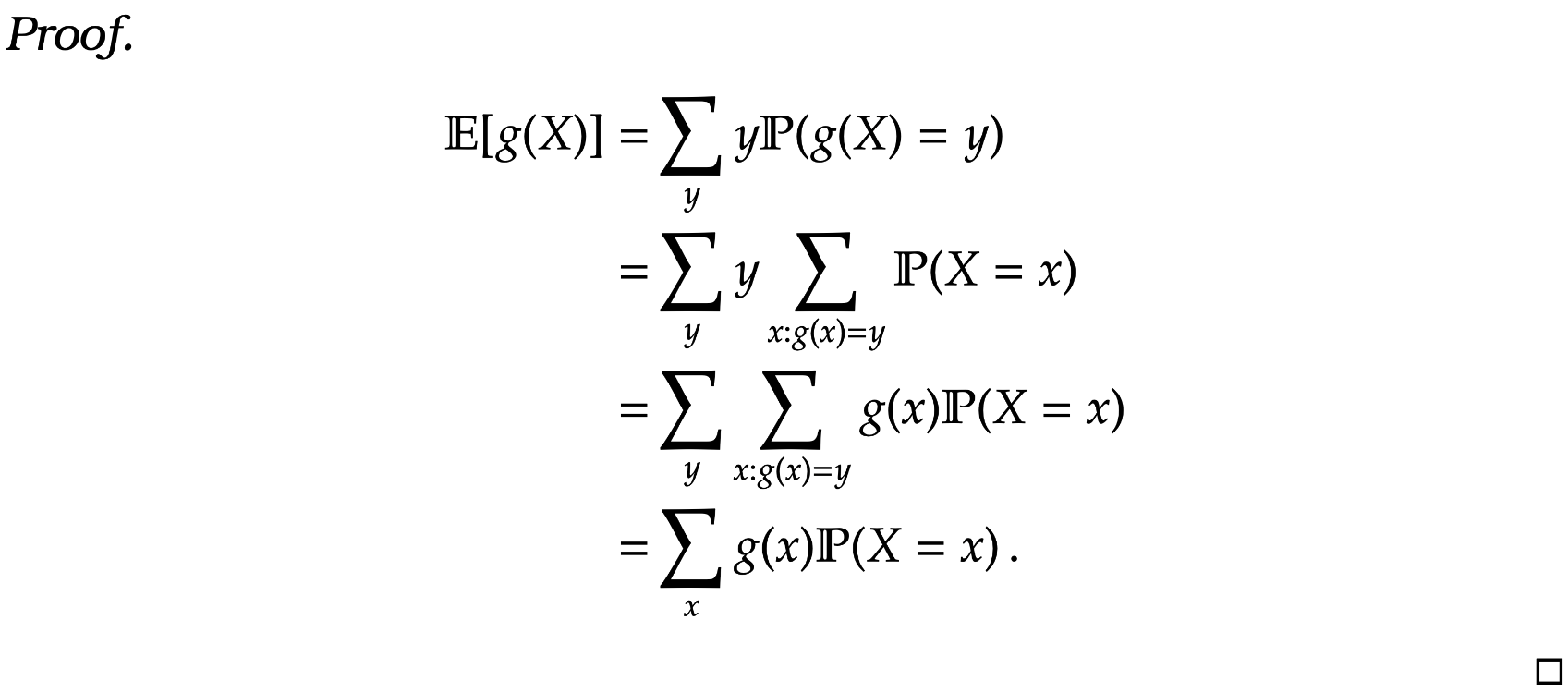
Lemma 2. For constants 

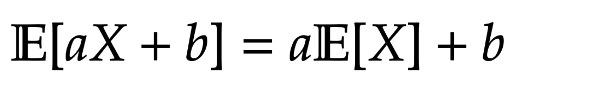
Proof. Applying Lemma 1.
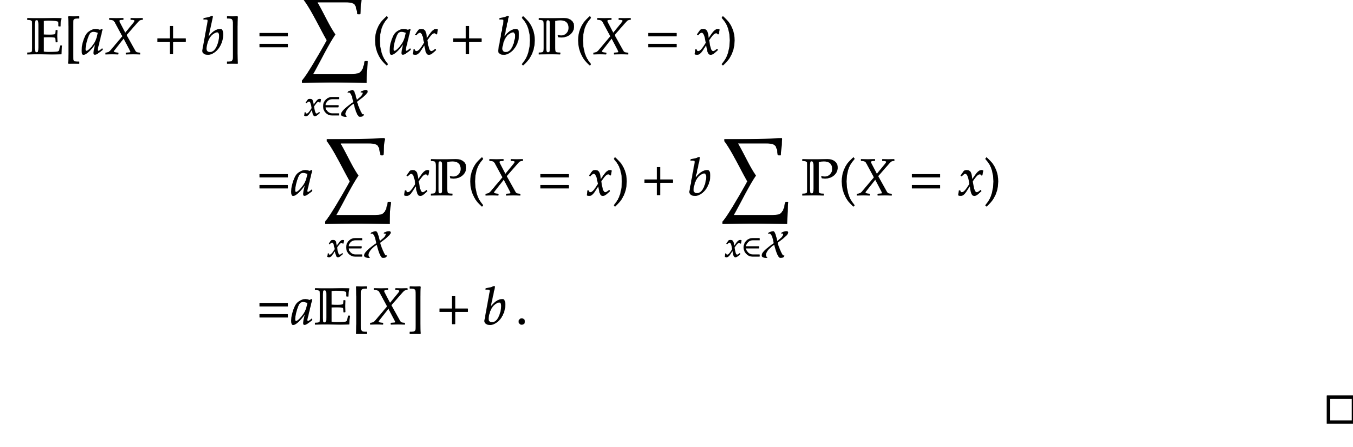
Lemma 3. For two random variables 
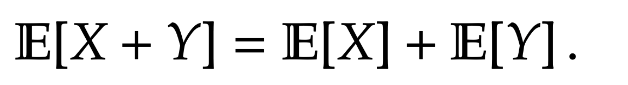
 \mathbb P(X=x, Y=y)
\notag
\\
=
&
\sum_{x \in \mathcal X} \sum_{y \in \mathcal Y} x \mathbb P(X=x, Y=y)
+
\sum_{x \in \mathcal X} \sum_{y \in \mathcal Y} y \mathbb P(X=x, Y=y)
\notag
\\
=
&
\sum_{x \in \mathcal X} x \mathbb P(X=x)
+
\sum_{y \in \mathcal Y} y \mathbb P(Y=y)
\notag
\\
=
&
\mathbb E[X] + \mathbb E[Y]\, .
%\end{aligned}")
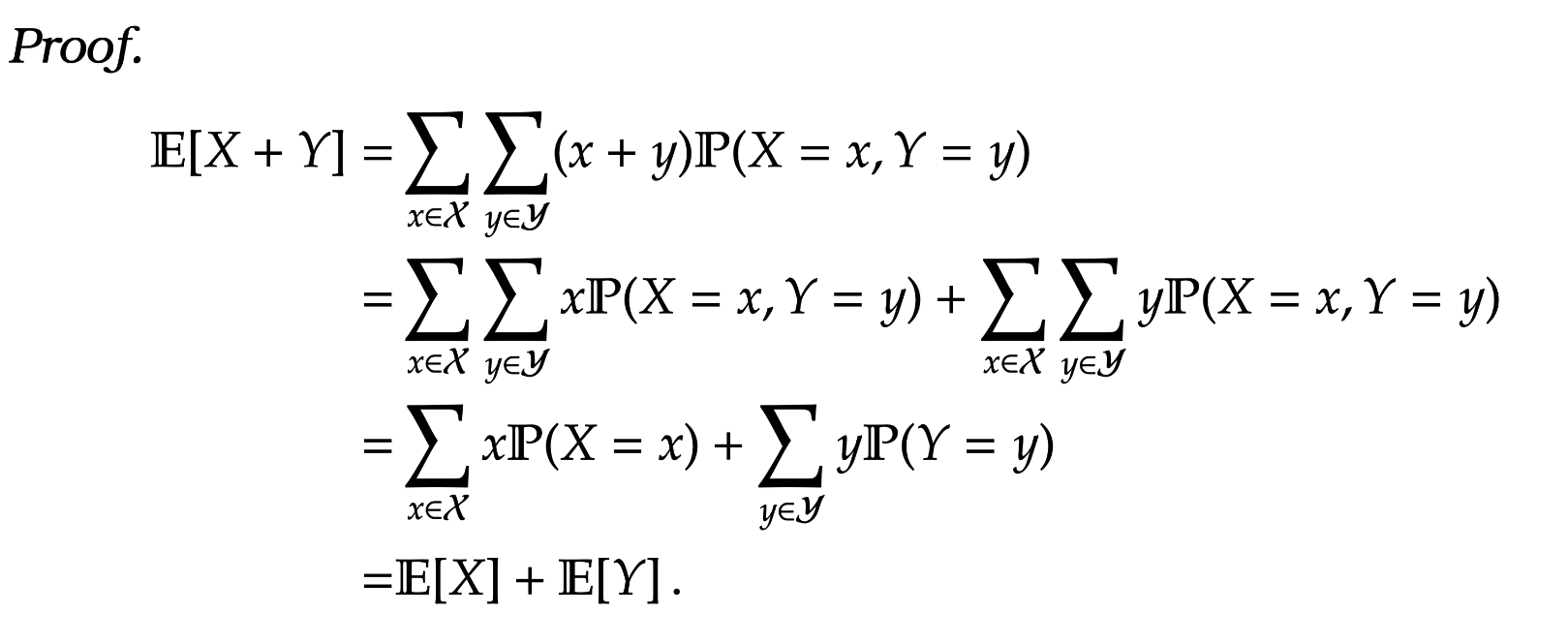
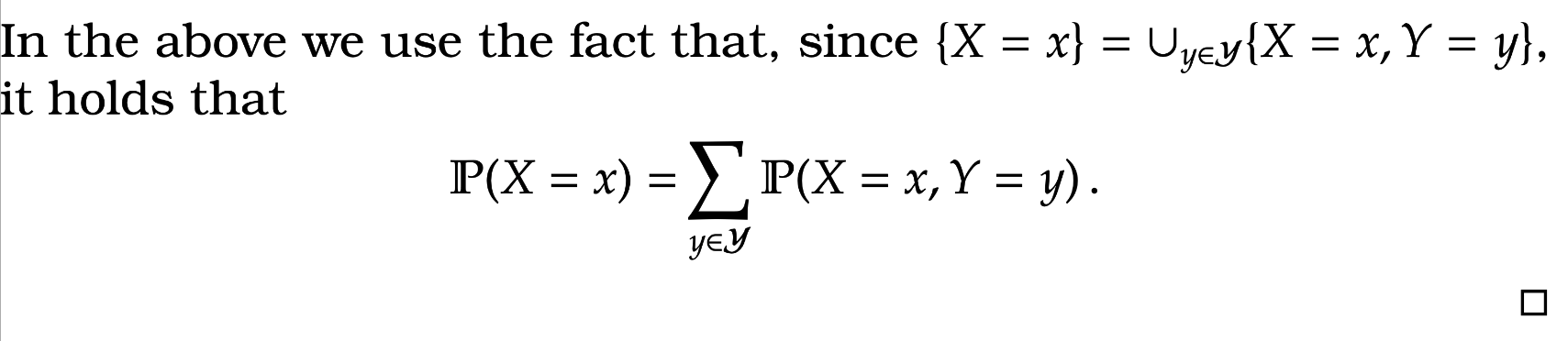
Lemma 4. For two independent random variables 
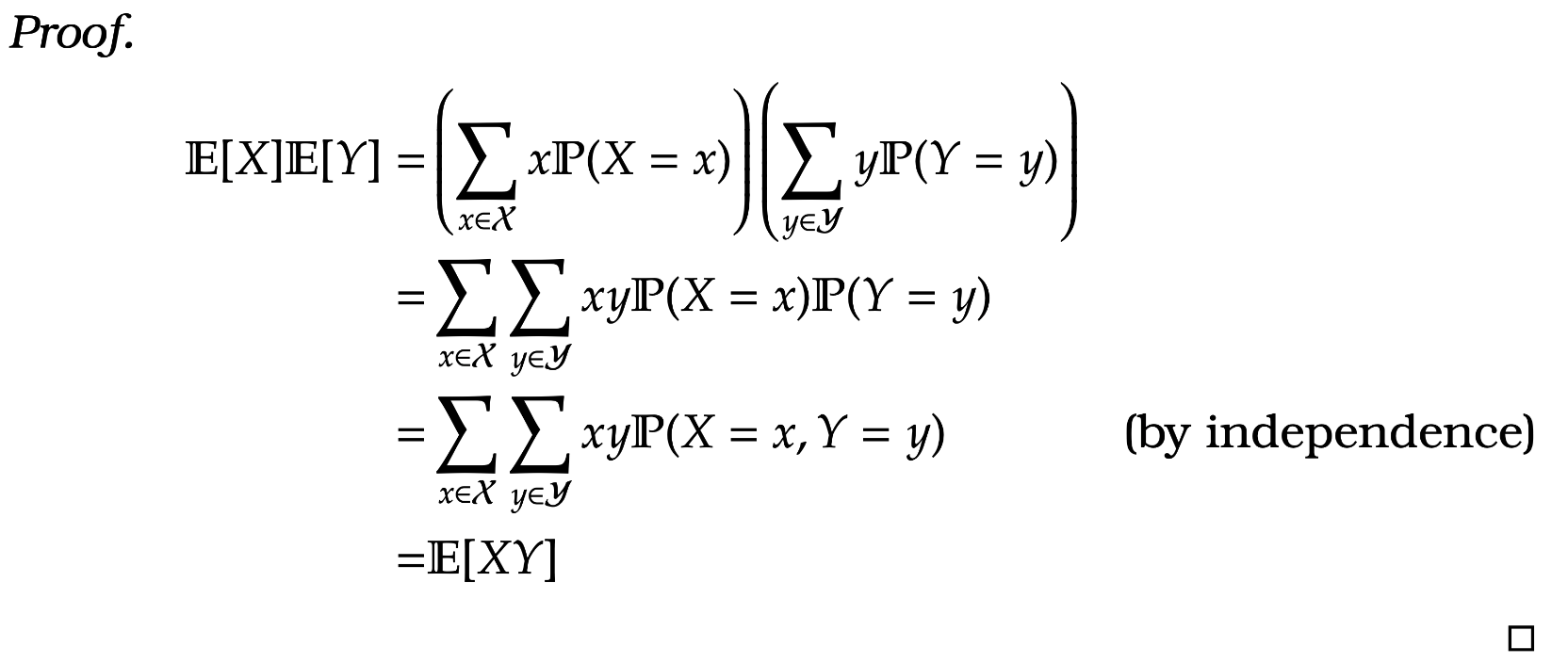
Warning! In general, we cannot multiply expectations in this way. We need independence to hold. For instance if 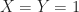
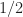

![1/2 = \mathbb E [ X Y] \neq \mathbb E[X] \mathbb E[Y] = 1/4](https://s0.wp.com/latex.php?latex=1%2F2+%3D+%5Cmathbb+E+%5B+X+Y%5D+%5Cneq+%5Cmathbb+E%5BX%5D+%5Cmathbb+E%5BY%5D+%3D+1%2F4&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Example. Let 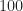
![\mathbb E [Y] = 50](https://s0.wp.com/latex.php?latex=%5Cmathbb+E+%5BY%5D+%3D+50&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Answer. The exact distribution of
Note that 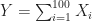

It is easy to see that ![\mathbb E[X_i ] = 1 \mathbb P(X_i =1 ) + 0 \mathbb P(X_i = 0) = 1/2](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX_i+%5D+%3D+1+%5Cmathbb+P%28X_i+%3D1+%29+%2B+0+%5Cmathbb+P%28X_i+%3D+0%29+%3D+1%2F2&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
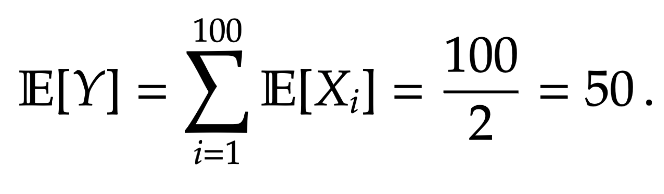
Variance
While the expectation gives an average value for a random variable. The variance determines how spread out a probability distribution is.
Definition [Variance / Standard Deviation] The variance of a random variable  := \mathbb E[ (X- \mathbb E[X])^2]
%\end{aligned}")
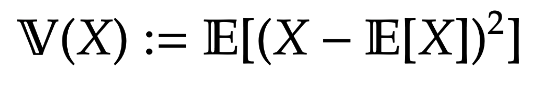
Further the standard deviation is the square-root of the variance. That is  := \sqrt{ \mathbb V(X)}
%\end{aligned}")
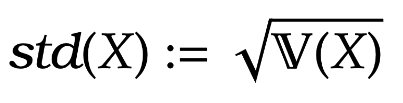
It is common to use 
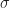
^2 ] \, .
%\end{aligned}")
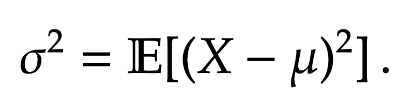
Here we use 

Lemma 5.
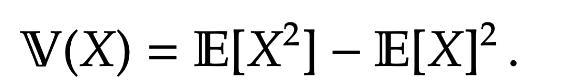
So the variance is the mean square minus the square of the mean.
Proof.

=
& \mathbb E [ (X- \mathbb E[X])^2 ]
\notag
\\
=
&
\mathbb E [ X^2 - 2 X \mathbb E[X] + \mathbb E[X]^2 ]
\notag
\\
=
&
\mathbb E[X^2 ]
-
2 \mathbb E[X] \mathbb E[X]
+
\mathbb E[X]^2
\notag
\\
=
&
\mathbb E[ X^2] - \mathbb E[X]^2 \, .\end{aligned}")

Lemma 6. For
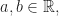
 = a^2 \mathbb V(X) \, .\end{aligned}")

=
&
\mathbb E[ ( a X + b - \mathbb E[ a X +b ])^2
\notag
\\
=
&
\mathbb E[ (a X - a \mathbb E[X])^2 ]
\notag
\\
=
&
a^2 \mathbb E[ (X- \mathbb E[X])^2 ]
\notag
\\
=
&
a^2 \mathbb V(X) \, .
%\end{aligned}")
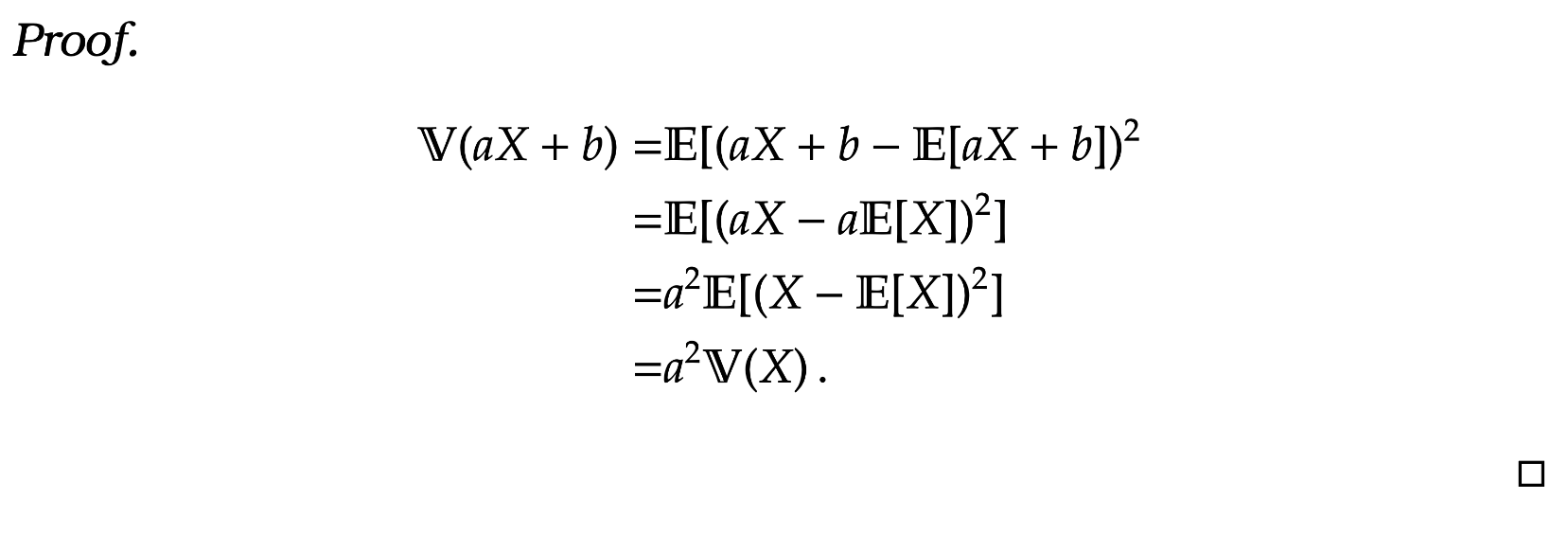
Lemma 7. If  = \mathbb V(X) + \mathbb V(Y)\, .
%\end{aligned}")

=
&
\mathbb E[ (X+Y)^2 ] - \mathbb E [X+Y]^2
\notag
\\
=
&
\mathbb E[ X^2 + 2XY + Y^2 ]
-
( \mathbb E[X]^2 + 2 \mathbb E[X] \mathbb E[Y] + \mathbb E[Y]^2 )
\notag
\\
=
&
\mathbb E[ X^2] - \mathbb E[X]^2 + \mathbb E[Y^2] - \mathbb E[Y]^2 + \underbrace{2 \mathbb E[ XY] - 2 \mathbb E[X] \mathbb E[Y]}_{=0, \text{ by independence.}}
\notag
\\
=
&
\mathbb V(X) + \mathbb V(Y) \,.
%\end{aligned}")
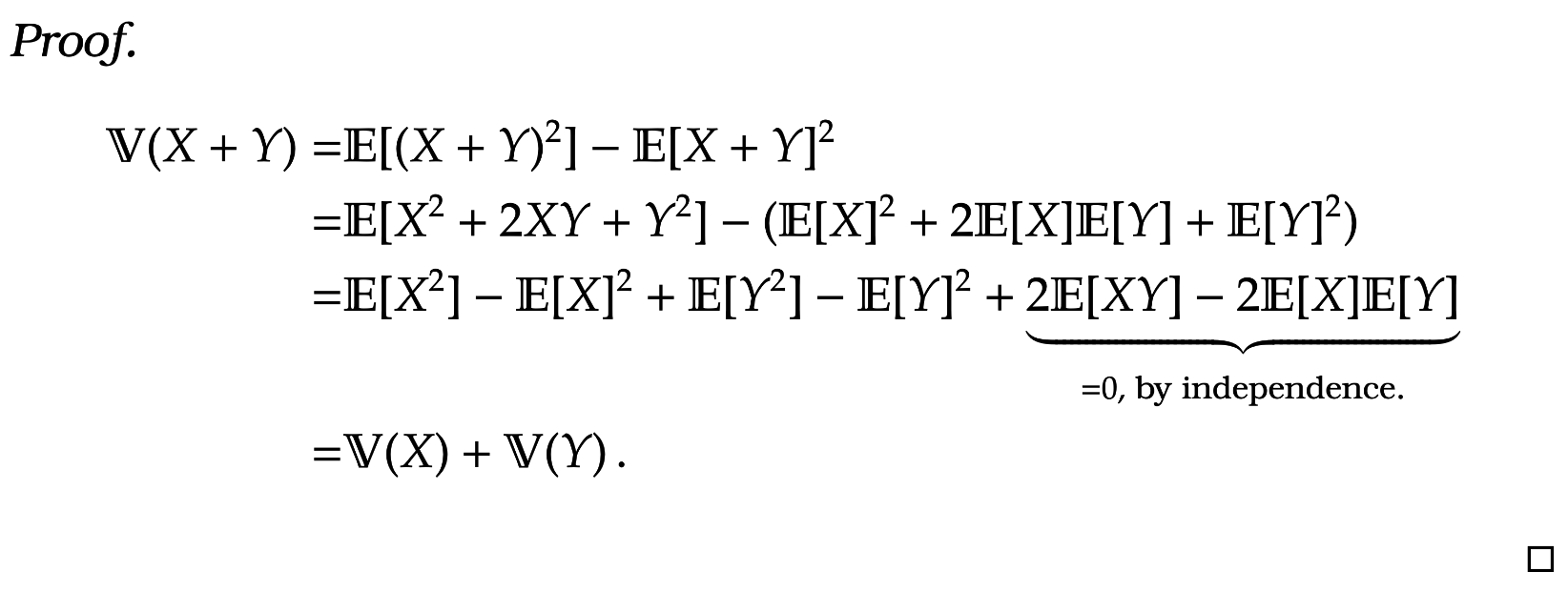
Notice if we have a sequence of independent identically distributed random variables (IIDRVs) 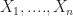


=
\sqrt{
\mathbb V\bigg( \sum_{i=1}^n X_i \bigg)
}
= \sqrt{\sum_{i=1}^n \mathbb V\big( X_i \big) }
=
\sigma\sqrt{n} \,.
%\end{aligned}")
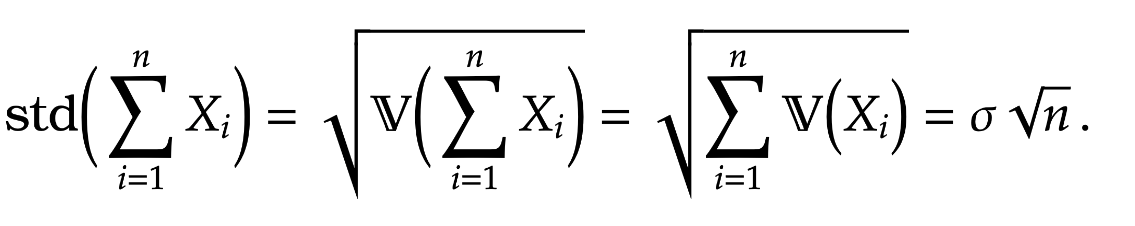
So we see that as we add up more and more IIDRVs the distance from the mean is about