This is the appendix in the notes here.
Category: Probability
Exponential Families
The exponential family of distributions are a particularly tractable, yet broad, class of probability distributions. They are tractable because of a particularly nice [Fenchel] duality relationship between natural parameters and moment parameters. Moment parameters can be estimated by taking the empirical mean of sufficient statistics and the duality relationship can then recover an estimate of the distributions natural parameters.
Continue reading “Exponential Families”Kalman Filter
Kalman filtering (and filtering in general) considers the following setting: we have a sequence of states 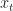
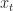
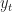

Mixing Times
In loose terms, the mixing time is the amount of time to wait before you can expect a Markov chain to be close to its stationary distribution. We give an upper bound for this.
Bayesian Online Learning
We briefly describe an Online Bayesian Framework which is sometimes referred to as Assumed Density Filer (ADF). And we review a heuristic proof of its convergence in the Gaussian case.
Stochastic Linear Regression
We consider the following formulation of Lai, Robbins and Wei (1979), and Lai and Wei (1982). Consider the following regression problem,

for 
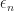

Typically for a regression problem, it is assumed that inputs 




Markov’s Inequality, Chebychev’s Inequality and the Weak Law of Large Numbers
Robbins-Munro
We review the proof by Robbins and Munro for finding fixed points. Stochastic gradient descent, Q-learning and a bunch of other stochastic algorithms can be seen as variants of this basic algorithm. We review the basic ingredients of the original proof.
