There are some probability distributions that occur frequently. This is because they either have a particularly natural or simple construction. Or they arise as the limit of some simpler distribution. Here we cover
- Bernoulli random variables
- Binomial distribution
- Geometric distribution
- Poisson distribution.
(This is a section in the notes here.)
Of course there are many other important distributions. Like with counting, it is often easy when first learning about probability to think of different probability distributions as being a main destination for probability. However, it is perhaps better to think of the probability distributions that we cover now as simple building blocks that we can then be later used to construct more expressive probabilistic and statistical models.
Again we focus on probability distributions that take discrete values though shortly we will begin to discuss their continuous counterpart.
Notation. There are many different distributions which often have different parameters. For instance, shortly we will define the Binomial Distribution, which has two parameters 






 \, .
%\end{aligned}")

Bernoulli Distribution.
We start with the simplest discrete probability distribution.
Definition [Bernoulli Distribution] A random variable that is either zero or one is a Bernoulli random variable. That is we we write 
 = p \qquad \text{and} \qquad \mathbb P(X=0) =1-p \,.\end{aligned}")
It is a straight-forward calculation to show that

for  = p(1-p) \,.
%\end{aligned}")
Binomial Distribution.
If we take 


then we get a Binomial distribution with parameters
So if we consider an experiment with probability of success
Let’s briefly consider the probability that 




\\
&=
\mathbb P (X_1=1) ... \mathbb P( X_k=1) \mathbb P( X_{k+1} = 0 ) ... \mathbb P( X_n = 0 )
\notag
\\
&
=
p^k (1-p)^{n-k}
%\end{aligned}")

Indeed the probability of any individual sequence 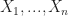


 = { n \choose k} p^k (1-p)^{n-k} \, .
%\end{aligned}")

This motivates the following definition.
Definition [Binomial Distribution] A random variable  = { n \choose k} p^k (1-p)^{n-k} \, ,
%\end{aligned}")

for 

Here are some results on Binomial distributions that might be handy.
Lemma 1. If  = n p (1-p) \, .
%\end{aligned}")
![]()

Lemma 2. If 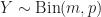
 \, .
%\end{aligned}")
![]()
Proof. 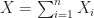
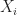
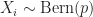
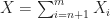
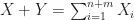
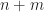
Lemma 3. If 
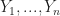

 \, .
%\end{aligned}")

Proof. Since we can write  Since
Since 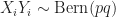


Geometric Distribution
Suppose we throw a biased coin until the first time that it lands on heads. The distribution of the number of throws is a geometric distribution. For instance, the probability that it takes 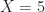
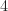
 = \mathbb P( TTTTH) = (1-p)^4 p
%\end{aligned}")

where  = (1-p)^k p \, .
%\end{aligned}")

This gives the geometric distribution.
Definition [Geometric distribution] The geometric distribution with success probability  = (1-p)^{k-1} p
%\end{aligned}")

for 

The following lemma is useful for geometrics distributions but also various forms of compound interest and other applications.
Lemma 4. [Geometric Series]For 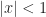
^2}
\quad \text{and} \quad \sum_{n=0}^\infty n(n-1) x^{n-2} =\frac{2}{(1-x)^3}\end{aligned}")
Proof.

Now subtracting gives \sum_{n=0}^\infty x^n = 1
%\end{aligned}")

Thus
} \,.\end{aligned}")
Differentiating the above with respect to 
} = \frac{1}{(1-x)^2} \,.\end{aligned}")
Differentiating again gives
 x^{n-2} =\frac{2}{(1-x)^3} \, .\end{aligned}")
Lemma 4. If  = (1-p)^k, \quad \mathbb E[ X] = \frac{1}{p} ,\quad \text{and} \quad \mathbb V(X) = \frac{1-p}{p^2} \, .<br />
%\end{aligned}")
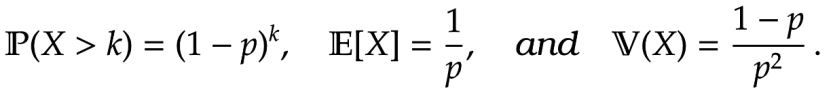
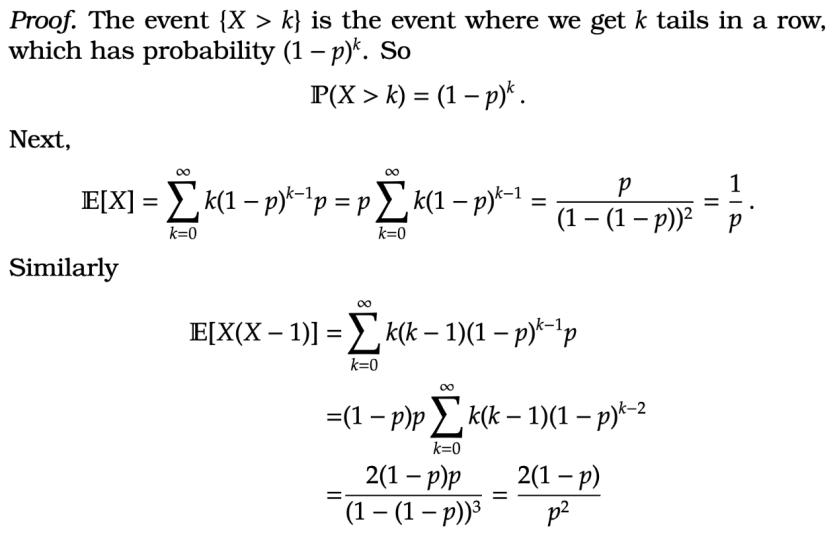

If we throw a coin and get 
Lemma 5. [Memoryless Property] If 

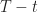

Proof.
<br />
=<br />
&<br />
\frac{\mathbb P(T > t+k , T> t) }{\mathbb P(T >t)}<br />
\notag<br />
\\<br />
=<br />
&<br />
\frac{\mathbb P(T > t+k)}{\mathbb P(T>t)}<br />
\notag<br />
\\<br />
=<br />
&<br />
\frac{(1-p)^{t+k}}{(1-p)^t}<br />
=<br />
(1-p)^k\end{aligned}")
Example [Waiting for a bus] At a bus stop, the probability that a bus arrives at any given minute is
- What is the expect gap in the time between any two busses?
- You arrive at the bus stop and there is no bus there. What is the expected gap between the last time a bus arrived and the next bus to arrive?
Answer. 1. The time from one bus to the next is geometric 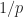
2. Given you at a time with no bus the time until the last bus too arrive is geometrically distributed with parameter 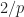
This is sometimes called the waiting time paradox. Here we see that when we turn up at the bus station the gap between the buses is twice as long as the mean time between the buses. This is because when we turn up and there is no bus there then we are more likely to have chosen a time with a bigger gap between the buses.
Poisson Distribution.
The Poisson distribution arises when we count the number of successes of an unlikely event over a large population. This occurs in all manner of settings from nuclear decay, to insurance, to call over a telephone line.
We present a definition first and then we will motivate the Poisson distribution.
Definition [Poisson distribution] For a parameter 
 = \frac{\lambda^k}{k!} e^{\lambda}
%\end{aligned}")

for 
Motivation for Poisson Distribution. If we take a Binomial distribution where the number of trails 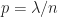
This is the reason the Poisson distribution is a reasonable distribution to represent pheonomena like nuclear decay. In nuclear decay, there are a large number of atoms in a radio-active substance, and, in any given time interval, there is a very small probability of one of these atom undergoing nuclear decay and the emitting a particle (e.g. a gamma-ray). For this reason the distribution of the number of observed gamma-rays over a time interval is well approximated by a Poisson distribution.
The following lemma sets out how the Poisson distribution approximates the Binomial distribution (again students primarily interested in assessment can skip with argument).
Theorem 1 [Binomial to Poisson Limit] Consider a sequence of Binomial random variables 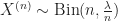
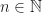

} = k ) \xrightarrow[n \rightarrow \infty]{} \mathbb P(X =k)
%\end{aligned}")

That is as 
} = k ) =&
{ n \choose k} \left(
\frac{\lambda}{n}
\right)^k
\left(
1- \frac{\lambda}{n}
\right)^{n-k}
\notag
\\
=
&
\frac{n}{n} \cdot \frac{n-1}{n} \cdot... \cdot\frac{n-k+1}{n} \cdot \frac{\lambda^k}{k!}
\cdot \left(
1- \frac{\lambda}{n}
\right)^{-k}
\cdot
\left(
1- \frac{\lambda}{n}
\right)^n
\label{PoLongEquation}
\\
\rightarrow
&
\frac{\lambda^k}{k!} e^{-\lambda} = \mathbb P(X=k) \,. \notag
%\end{aligned}")
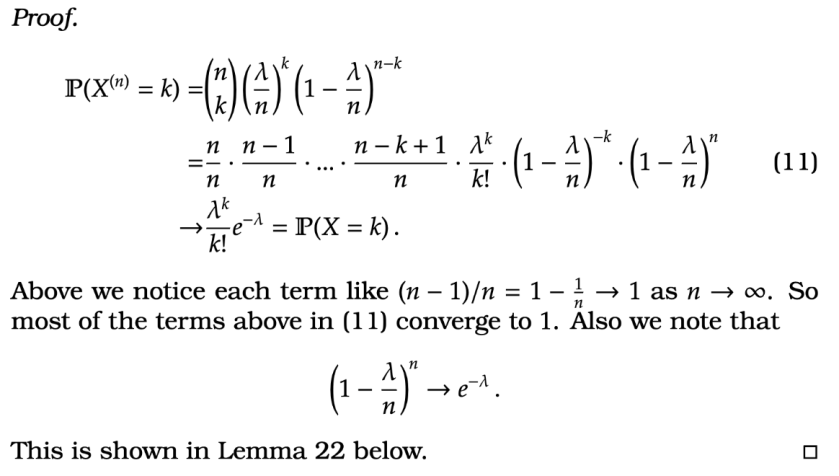

Now for some more standard facts about the Poisson distribution.

Lemma 6 [Poisson Summation Property] If 
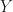
.")
Lemma 7 [Poisson Thinning Property] If 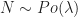


\, .
%\end{aligned}")
In Lemma 6, we can begin to see how we can think of a Poisson distribution as part of a process that evolves in time. For instance we might say that the number of calls on a set of telephone lines in each minute is Poisson distributed with mean 
In Lemma 7, we can see that if we exclude points according to an independent random variable then the resulting random variable is still Poisson. This is useful for instance in insurance. Here the number of claims an insurance company receives in a given day might be Poisson with mean 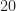
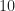
Both lemmas can be proved directly by summing things but is a bit of a messy calculation. Intuitively the above lemmas holds because an equivalent results, Lemma 2 and Lemma 3, hold for Binomial random variables. So the both properties persists when we take the limit to a Poisson random variable (like in Theorem 1). The cleanest proof (using moment generating functions) is beyond the scope of this course, so we omit the proof for now.

wow!! 103Zero-Order Stochastic Optimization: Keifer-Wolfowitz
LikeLike