- Optimal Stopping Problems; One-Step-Look-Ahead Rule
- The Secretary Problem.
- Infinite Time Stopping
Category: Optimization
Algorithms for MDPs
- High level idea: Policy Improvement and Policy Evaluation.
- Value Iteration; Policy Iteration.
- Temporal Differences; Q-factors.
Infinite Time Horizon, MDP
- Positive Programming, Negative Programming & Discounted Programming.
- Optimality Conditions.
Lagrangian Optimization
We are interested in solving the constrained optimization problem
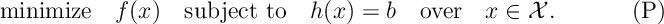
Talagrand’s Concentration Inequality
We prove a powerful inequality which provides very tight gaussian tail bounds “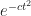

Spitzer’s Lyapunov Ergodicity
We show that relative entropy decreases for continuous time Markov chains.
Cross Entropy Method
In the Cross Entropy Method, we wish to estimate the likelihood
 \geq \gamma ).")
Here 

Online Convex Optimization
We consider the setting of sequentially optimizing the average of a sequence of functions, so called online convex optimization.
Gradient Descent
We consider one of the simplest iterative procedures for solving the (unconstrainted) optimization
A Network Decomposition
We consider a decomposition of the following network utility optimization problem
SYS:
 \\ &\text{subject to} &\quad \sum_{r: j\in r} \Lambda_r \leq C_j, \quad j\in{\mathcal J}, \\ &\text{over} &\quad \Lambda_r\geq 0,\quad r\in{\mathcal R}.%\tag{{SYS}{\mathcal R}} \end{aligned}")
