In the Cross Entropy Method, we wish to estimate the likelihood
 \geq \gamma ).")
Here  is a random variable whose distribution is known and belongs to a parametrized family of densities
is a random variable whose distribution is known and belongs to a parametrized family of densities  . Further
. Further 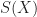 is often a solution to an optimization problem.
is often a solution to an optimization problem.
It is assumed that 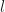 is a relatively rare event, say of order
is a relatively rare event, say of order  . One way to estimate is to take
. One way to estimate is to take  IID samples
IID samples 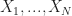 and then average
and then average
 \geq \gamma ].")
This gives us an unbiased estimate. However, because the event is rare, we may require a large number of samples in order to provide a good estimate of . Importance sampling is a straightforward method that can mitigate these effects. Here sample each 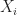 from a different density
from a different density 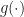 and perform the estimate
and perform the estimate
 \geq \gamma ] W(x)")
where W(x) = f(x)/g(x). Such a change can improve the estimation of . For instance, the choice ![g^*(x)= {\mathbb I} [ S(x) \geq \gamma ] f(x)/l](https://s0.wp.com/latex.php?latex=g%5E%2A%28x%29%3D+%7B%5Cmathbb+I%7D+%5B+S%28x%29+%5Cgeq+%5Cgamma+%5D+f%28x%29%2Fl+&bg=ffffff&fg=1a1a1a&s=0&c=20201002) gives the correct estimate of with certainty. Clearly
gives the correct estimate of with certainty. Clearly 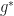 cannot work in practice; it requires knowledge of , the parameter which we are estimating. Nonetheless a good estimate of may be possible. The point of the cross entropy method is to find a reasonable choice for
cannot work in practice; it requires knowledge of , the parameter which we are estimating. Nonetheless a good estimate of may be possible. The point of the cross entropy method is to find a reasonable choice for  so that importance sampling can be applied.
so that importance sampling can be applied.
In particular, the cross-entropy method advocates estimating 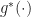 by
by  according to a parameter choice that minimizes the relative entropy between and
according to a parameter choice that minimizes the relative entropy between and 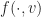 . Namely,
. Namely,
 || g(\cdot) ) := - \int g(x) \log \frac{f(x; v)}{g(x)} dx.")
With a little rearrangement, we see that this is equivalent to the optimization
 \geq \gamma ] f(x;u) \log f(x; v) dx.")
With importance sampling in mind, we apply a change of measure to the above integral to get
 \geq \gamma ] f(x;w) W(x;u,v) \log f(x; v) dx")
where  . The above optimization may not be explicitly solvable so we replace it with the (importance sampled) optimization
. The above optimization may not be explicitly solvable so we replace it with the (importance sampled) optimization
 \geq \gamma ] W(X_i ; u,w) \log f(x;v) dx")
where are IID samples from density  .
.
In many examples the above optimization in concave and solvable either by descent methods or by differentiating and solving for the condition
 \geq \gamma ] W(X_i ; u,w) \nabla \log f(x;v) = 0.")
The reason for incorporating importance sampling into the estimate is because the event  could be too unlikely to form an accurate estimate under the choice
could be too unlikely to form an accurate estimate under the choice  . The idea behind the cross entropy method is to apply a multi-level approach where we sequentially increase
. The idea behind the cross entropy method is to apply a multi-level approach where we sequentially increase 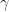 and
and 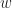 as follows
as follows
- We estimate the
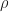 -th percentile of by taking by ordering the samples
-th percentile of by taking by ordering the samples  and calculating the empirical -th percentile, which gives the update
and calculating the empirical -th percentile, which gives the update
 N \rceil}")
The event is chosen to be reasonably likely, e.g.  . Note that since, in principle, the parameter
. Note that since, in principle, the parameter 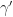 is such that less likely
is such that less likely  under
under  when compared with the previous choice of .
when compared with the previous choice of .
- Given this , we find
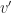 as the best estimate according to our cross-entropy rule . This, in principle, should increase the likelihood of the event when compared with prior choice of .
as the best estimate according to our cross-entropy rule . This, in principle, should increase the likelihood of the event when compared with prior choice of .
- When passes the required target level then the have found a parameter choice that gives reasonable importance to the event
 and we can calculate with importance sampling rule .
and we can calculate with importance sampling rule .
