We prove a powerful inequality which provides very tight gaussian tail bounds “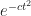 ” for probabilities on product state spaces
” for probabilities on product state spaces  . Talagrand’s Inequality has found lots of applications in probability and combinatorial optimization and, if one can apply it, it generally outperforms inequalities like Azzuma-Hoeffding.
. Talagrand’s Inequality has found lots of applications in probability and combinatorial optimization and, if one can apply it, it generally outperforms inequalities like Azzuma-Hoeffding.
Thrm [Talagrand’ Concentration Inequality] For  a measurable subset of the product space ,
a measurable subset of the product space ,
^2} \bP(dx) \leq \frac{1}{\bP(A)}.")
and, consequently,
 \geq t )\bP(A) \leq e^{-\frac{t^2}{4}}.")
Here,
&= \sup_{\substack{\alpha\in\bR_+^n\\ ||\alpha||_2\leq 1}} \inf_{y\in A} \sum_{k=1}^n \alpha_k \bI[x_k\neq y_k]= \inf_{v\in < V(x,A)>} ||v||_2 \end{aligned}")
where, ![V(x,A)=\{ u: u_k\geq \mathbb I[x_k\neq y_k], \text{ for }k=1,..,n,\text{ for some }y\in A\}](https://s0.wp.com/latex.php?latex=V%28x%2CA%29%3D%5C%7B+u%3A+u_k%5Cgeq+%5Cmathbb+I%5Bx_k%5Cneq+y_k%5D%2C+%5Ctext%7B+for+%7Dk%3D1%2C..%2Cn%2C%5Ctext%7B+for+some+%7Dy%5Cin+A%5C%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
.
Proof. The duality between the two characterizations of 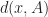 are given in the appendix to this section.
are given in the appendix to this section.
We will prove the inequality holds by induction on  . Note for the case
. Note for the case  ,
, ![d(x,A)=\mathbb I[x\notin A]](https://s0.wp.com/latex.php?latex=d%28x%2CA%29%3D%5Cmathbb+I%5Bx%5Cnotin+A%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) so holds since
so holds since  .
.
Now assuming our induction hypothesis up to , we prove the result for the 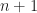 case. We do so by proving the following claim
case. We do so by proving the following claim
Claim: For 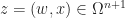 ,
,  and
and  ,
,
^2\leq \lambda d(x,A(w))^2+ (1-\lambda) d(x,\tilde{A})^2 + (1-\lambda)^2, \qquad \forall \Lambda \in (0,1) \label{Tal:dineq}")
where,
=\{x'\in \Omega^{n}: (w,x')\in A\} \qquad\text{and}\qquad \tilde{A}= \{ \tilde{x} \in \Omega^n: (\tilde{w},\tilde{x})\in A \text{ for some } \tilde{w} \}.")
- In equality , we over estimate
 by two distances on : the first, a refined distance using information about
by two distances on : the first, a refined distance using information about 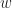 ,
,  ; and the second, a cruder distance using only information about
; and the second, a cruder distance using only information about  and ,
and ,  .
.  for rectangular sets only.
for rectangular sets only.
Proof of claim: We prove the bound by considering the convex combination of points in  and
and  . Note if
. Note if 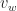 is a point in then there exists a
is a point in then there exists a  such that
such that ![v_k \geq \mathbb I[x_k\neq y_k]](https://s0.wp.com/latex.php?latex=v_k+%5Cgeq+%5Cmathbb+I%5Bx_k%5Cneq+y_k%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) for each
for each  , also
, also ![0\geq \mathbb I[w=w]](https://s0.wp.com/latex.php?latex=0%5Cgeq+%5Cmathbb+I%5Bw%3Dw%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) for the
for the  case. So, if
case. So, if  then
then 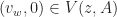 . By a similar easy argument, we see that if
. By a similar easy argument, we see that if  then
then 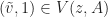 . It is also clear that these inclusions extend on convex combinations
. It is also clear that these inclusions extend on convex combinations  and
and  . Thus we see that if and
. Thus we see that if and  then
then
=\lambda (v_w,0)+ (1-\lambda) (\tilde{v},1) \in <V(z,A)>.")
Also, using convexity of  ,
,
||_2^2= ||\lambda v_w + (1-\lambda) \tilde{v} ||_2^2 + (1-\lambda)^2 \leq \lambda ||v_w||_2^2 + (1-\lambda) ||\tilde{v}||_2^2 + (1-\lambda)^2.")
Optimizing over  and , as required, we get
and , as required, we get
^2\leq \lambda d(x,A(w))^2 + (1-\lambda) d(z,\tilde{A})^2 + (1-\lambda)^2.")
This completes the proof of our claim and we continue with the proof of Talagrand’s Inequality.
Continuing to write 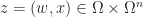 and applying of inequality , we have for the conditional expectation that
and applying of inequality , we have for the conditional expectation that } \bP(dx, w) & \leq \int e^{\frac{1}{4} \lambda d(x,A(w))^2+ \frac{1}{4}(1-\lambda) d(x,\tilde{A})^2 +\frac{1}{4} (1-\lambda)^2} \bP(dx, w) \\ & \leq e^{\frac{1}{4} (1-\lambda)^2}\left( \int e^{\frac{1}{4}d(x,A(w))^2}\bP(dx, w) \right)^{\lambda}\left( \int e^{\frac{1}{4}d(x,\tilde{A})^2}\bP(dx, w) \right)^{(1-\lambda)}\\ & \leq e^{\frac{1}{4}(1-\lambda)^2} \bP(A(w))^{-\lambda} \bP(\tilde{A})^{-(1-\lambda)}\\ &\leq \frac{1}{\bP(\tilde{A})} \left(2 - \frac{\bP(A(w))}{\bP(\tilde{A})} \right).\end{aligned}") For second inequality, above, we apply Holder’s Inequality; in the third inequality, we apply our induction hypothesis; in the fourth inequality, we use the fact that
For second inequality, above, we apply Holder’s Inequality; in the third inequality, we apply our induction hypothesis; in the fourth inequality, we use the fact that  , which we prove in the appendix to this section.
, which we prove in the appendix to this section.
Now taking expectations over , and observing  , we gain the required result:
, we gain the required result:
} \bP(dz) \leq \frac{1}{\bP(A)} \frac{\bP(A)}{\bP(\tilde{A})} \left(2 - \frac{\bP(A)}{\bP(\tilde{A})} \right) \leq \frac{1}{\bP(A)}.")

Applications
Let’s informally discuss the application of Talagrand’s Inequality and then give a few examples of how to apply the result. First we recall that the Hamming distance is ![d_H(x,y) =\sum_{i=1}^n \mathbb I[x_i\neq y_i]](https://s0.wp.com/latex.php?latex=d_H%28x%2Cy%29+%3D%5Csum_%7Bi%3D1%7D%5En+%5Cmathbb+I%5Bx_i%5Cneq+y_i%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) , so Talagrand considers a weighted Hamming distance from the set of
, so Talagrand considers a weighted Hamming distance from the set of 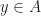 ,
, ![d_{\alpha,H}(x,A):=\inf_{y\in A} \sum_{i=1}^n \alpha_i\mathbb I[x_i \neq y_i]](https://s0.wp.com/latex.php?latex=d_%7B%5Calpha%2CH%7D%28x%2CA%29%3A%3D%5Cinf_%7By%5Cin+A%7D+%5Csum_%7Bi%3D1%7D%5En+%5Calpha_i%5Cmathbb+I%5Bx_i+%5Cneq+y_i%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . A result of a similar form was known to hold previously to Talagrand’s, namely,
. A result of a similar form was known to hold previously to Talagrand’s, namely,
 \bP( d_{\alpha,H}(x,A) \geq t) \leq e^{-\frac{t^2}{2}}")
However the bound is vastly improved by allowing us to optimize over  given : from an event
given : from an event  it is much more possible to deduce that for some
it is much more possible to deduce that for some  ,
,  . In particular, we are in a strong position if we can show a bound of the form
. In particular, we are in a strong position if we can show a bound of the form
 \geq F(y) - \sum_{i=1}^N \alpha_i^x \bI [x_i\neq y_i] \qquad\text{or}\qquad F(x) \leq F(y) + \sum_{i=1}^N \alpha_i^x \bI [x_i\neq y_i].")
Note by multiplying by 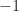 both bounds are equivalent. In both cases, we imagine that, if making a change so some of the compenents of gives
both bounds are equivalent. In both cases, we imagine that, if making a change so some of the compenents of gives 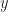 , then we have a way of estimating the change in
, then we have a way of estimating the change in  for each component changed. Note the (left) bound above implies
for each component changed. Note the (left) bound above implies
 \geq \frac{F(y) - F(x)}{||\alpha^x ||_2}, \qquad \forall y\in A")
Thus if we can bound  above by
above by  , (the smaller the better) and we take an event
, (the smaller the better) and we take an event  then
then 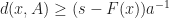 . Thus, for this choice of ,
. Thus, for this choice of ,  implies
implies  . Thus applying Talagrand gives
. Thus applying Talagrand gives
 \geq s) \bP(F(x) \leq s') \leq \bP( F(x) \geq s ) \bP( d(x,\{ F(y) \geq s \}) \geq (s-s')/a ) \leq e^{-\frac{1}{4} \frac{(s-s')^2}{a^2} }")
For median, 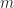 , inspecting the above bound with
, inspecting the above bound with 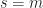 and
and  and then with
and then with  and
and 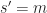 yields a bound
yields a bound
 - m| \geq t) \leq 4 e^{-\frac{1}{4} \frac{t^2}{a^2} }.")
At this point, we have a pretty convincing concentration bound about the median of the distribution of .
One might prefer work with the mean of F(x),  , rather than the median, . Note, a Cantelli’s inequality implies that the the mean is withing one standard deviation (see Lemma [Ineqs:MeanMedian]). We can estimate the variance of from the above concentration inequality: the variance about the mean is always minimal so
, rather than the median, . Note, a Cantelli’s inequality implies that the the mean is withing one standard deviation (see Lemma [Ineqs:MeanMedian]). We can estimate the variance of from the above concentration inequality: the variance about the mean is always minimal so
 -\mu)^2 \leq \bE ( F(X) - m)^2 \leq \int_0^\infty \bP(|F(x) - m|^2 \geq z) dz \leq 4 \int_0^\infty e^{-\frac{1}{4} \frac{z}{a^2} } dz = 16 a^2.")
So, 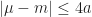 which gives
which gives 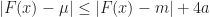 and so
and so
 - \mu| \geq t )\leq 4 e^{-\frac{(t-4a)^2}{a^2}}")
So once again we get a tail-bound with the same concentration behaviour.
Longest Increasing Subsequence
Given independent random variables 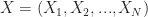 are independent real valued random variables, we consider the problem of finding the following Longest Increasing Subsequence:
are independent real valued random variables, we consider the problem of finding the following Longest Increasing Subsequence:
:=\max \qquad |S| \qquad \text{subject to} \qquad X_i < X_j,\quad i< j,\quad i,j\in S \quad \text{over} \quad S \subset \{1,...,N\}.")
Comparing two (similar) sequences and notice a longest subsequence of , 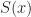 could be used as a (long) subsequence for . That is
could be used as a (long) subsequence for . That is
 \geq | i \in S : x_i = y_i | = I(x) - | i\in S : x_i \neq y_i|.")
We take such that 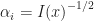 if
if 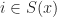 and
and  otherwise. If we consider the distance
otherwise. If we consider the distance 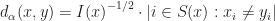 , then we have
, then we have
 \geq I(x) - \sqrt{I(x)} d_\alpha(x,y)")
which, on the event 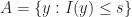 , gives
, gives
=\sup_{y\in A} \sup_{\alpha'} d_{\alpha'} (x,y) \geq \sup_{y\in A} \frac{I(x) - I(y)}{\sqrt{I(x)}} \geq \frac{I(x) -s}{\sqrt{I(x)}}.")
Note given we are working with an event of the form 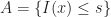 we look for an event
we look for an event  that implies is of a certian size. Since the function
that implies is of a certian size. Since the function  is increasing for
is increasing for  , then
, then 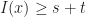 implies
implies 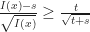 . Applying this then Talagrands inequality gives
. Applying this then Talagrands inequality gives
\leq s) \bP(I(x) \geq s+t) \leq \bP(I(x)\leq s) \bP\Big(d(X,A) \geq \frac{t}{\sqrt{t+s}} \Big) \leq e^{-\frac{1}{4}\frac{t^2}{(s+t)}}")
For the median of this distibution, then setting  and setting gives two tail bounds in the following result.
and setting gives two tail bounds in the following result.
Theorem
 \leq m-t) \leq 2 e^{-\frac{1}{4} \frac{t^2}{m}} ,\qquad \bP(I(x) \geq m+t) \leq 2 e^{-\frac{1}{4}\frac{t^2}{(m+t)}}")
Note the bounds do not look not terribly symmetric but, in order to achieve a guaranteed probability in both bounds, we must choose  of the same order,
of the same order,  , in both bounds.
, in both bounds.
Appendix
We first show the equality of our primal-dual characterization for .
>} ||v||_2 \end{aligned}")
For 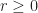
^2} \leq 2-r")
It is that this is equivalent to showing that
^2 -\lambda \log r \leq \log (2-r).")
The left-hand side is minimized by  . Thus, after substituting, we are required to show
. Thus, after substituting, we are required to show
^2 \leq \log (2-r)\quad")
We can equivalently expressed this inequality as an integral
}\left[ 2 \log x - x+1 - x\log x \right]dx.")
The term in the square brackets is negative: 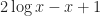 is concave and
is concave and  is convex, both terms are equal when
is convex, both terms are equal when 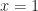 so the rest of the time
so the rest of the time  . This completes the lemma.
. This completes the lemma.


Wow, wonderful weblog layout! How lengthy have you ever been blogging for? you make blogging look easy. The overall look of your site is excellent, as neatly as the content material!
LikeLike