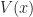An Optimal Stopping Problem is an Markov Decision Process where there are two actions: meaning to stop, and meaning to continue. Here there are two types of costs
This defines a stopping problem.
Assuming that time is finite, the Bellman equation is
for and .
Def 1. [OLSA rule] In the one step lookahead (OSLA) rule we stop when ever where
We call the stopping set. In words, you stop whenever it is better stop now rather than continue one step further and then stop.
Def 2. [Closed Stopping Set] We say the set is closed, it once inside that said you cannot leave, i.e.
Ex 1. Given the set is closed, argue that if for then .
Ans 1. If then since is closed . In otherwords . Therefore, in this case, Bellman’s equation becomes
The last inequality above follows by the definition of .
Ex 2. [OS:Finite] If, for the finite time stopping problem, the set given by the one step lookahead rule is closed then the one step lookahead rule is an optimal policy. (Hint: Induction on .)
Ans 2. The OSLA rule is optimal for steps, since OSLA is exactly the optimal policy for one step.
Suppose that the result is try for upto steps. Now consider the Optimal Stopping Problem with steps.
If , then clearly it’s better to continue.
Ex 3. [The Secretary Problem] There are candidates for a secretary job. You interview candidates sequentially. After each interview, you must either accept or reject the candidate. We assume each candidate has the rank: And arrive for interview uniformly at random. Find the policy that maximises the probability that you hire the best candidate.
Ans 3. All that matters at each time is if the current candidate is the best so far. At time let
Since is uniform random where the best candidate is
Under the chosen policy, we let
be our reward function. Now
Thus the Bellman equation for the above problem is
Notice that . Let be the smallest such that . Starting from note that so long as holds in second case in the above expression, we have that
Thus
Thus our condition for the optimal is to take the smallest such that
In other words, the optimal policy is to interview the first candidates and then accept the next best candidate.
Ex 4. [The Secretary Problem, continued] Argue that as , the optimal policy is to interview of the candidates and then to accept the next best candidate.
Ans 4. From [3], the optimal condition is
We know that as
Thus for .
Ex 5. You look for a parking space on street, each space is free with probability . You can’t tell if space is free until you reach it. Once at space you must decide to stop or continue. From position ( spaces from your destination), the cost of stopping is . The cost of passing your destination without parking is .
Ans 5. Let
Here stopping means take the next free parking space. The Bellman equation is
Consider the stopping set
where is the cost of taking the next available space. Note that
Recursion of this form have solution
Therefore
Since is decreasing, this set if clearly closed. Therefore the optimal policy is to take the next available space once holds.
Ex 6. In a game show a contestant is asked a series of 10 questions. For each question there is a reward for answering the question correctly. With probability the contestant answers the question correctly. After correctly answering a question, the contestant can choose to stop and take their total winnings home or they can continue to the next question . However, if the contestant answers a question incorrectly then the contestant looses all of their winnings. The probability of winning each round is decreasing and is such that the expected reward from each round, , is constant.
i) Write down the Bellman equation for this problem.
ii) Using the One-Step-Look-Ahead rule, or otherwise, find the optimal policy of the contestant.
Ans 6. The Bellman equation for this problem is
The stopping set for this problem is
Since by assumption and (therefore is decreasing) and the set S is closed. Thus the OSLA rule is optimal for this problem.
Ex 7. [Whittle’s Burglar] A burglar robs houses over nights. At any night the burglar may choose to retire and thus take home his total earnings. On the th night house he robs has a reward where is an iidrv with mean . Each night the probability that he is caught is and if caught he looses all his money. Find the optimal policy for the burglar’s retirement. (Hint: OLSA)
Ex 7. [Bruss’ Odds Algorithm] You sequentially treat patients with a new trail treatment. The probability of success is . We must minimize the number of unsuccessful treatments while treating all patients for which the trail is will be successful. (i.e. if we label for success and for failure, we want to stop on the last ). Argue, using the One-Step-Look-Ahead rule that the optimal policy is the stop treating at the largest integer such that
This procedure is called Bruss’ Odds Algorithm.
Optimal stopping in infinite time
We now give conditions for the one step look ahead rule to be optimal for infinite time stopping problems.
Ex 8. [OS:Converge] If the following two conditions hold
then
Ans 8. An optimal policy exists by Thrm [IDP:NegBellman]. Suppose that the optimal policy stops at time then
Therefore if we follow optimal policy but for the time horizon problem and stop at if then
Thus as required.
Ex 9. [continued] Suppose that from the one step lookahead that
Then it is optimal to stop if and only if .
Ans 9. As before (for the finite time problem), it is no optimal to stop if and for the finite time problem for all . Therefore by [[OS:Converge]] , since we have that for all and there for it is optimal to stop for .
Ex 10. You own a “toxic” asset its value, at time , belongs to . The daily cost of holding the asset is . Every day the value moves up to with probability or otherwise remains the same at . Further the cost of terminating the asset after holding it for days is . Find the optimal policy for terminating the asset.
The one step lookahead rule is not always the correct solution to an optimal stopping problem.
Def 3. [Concave Majorant] For a function a concave majorant is a function such that
.
Ex 11. [Stopping a Random Walk] Let be a symmetric random walk on where the process is automatically stopped at and . For each , there is a positive reward of for stopping. We are asked to maximize
where is our chosen stopping time. Show that the optimal value function is a concave majorant.
Ans 11. The Bellman equation is
with and . Thus the optimal value function is a concave majorant.
Ex 12. Show that is is the optimal reward starting from and stopping before steps (here ). Then for any concave majorant.
Ans 12. We will show that the optimal policy is the minimal concave majorant of . We do so by, essentially applying induction on value iteration.
First for any concave majorant of . Now suppose that , the function reached after value iterations, satisfies for all , then
Ex 13. Show that the optimal value function is the minimal concave majorant, and that it is optimal to stop whenever .
Ans 13. Since value iteration converges , where satisfies , as required. Finally observe that the optimal stopping rule is to stop whenever for the minimal concave majorant.
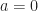
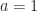
=\begin{cases} \kappa(x),& \text{for }a=0\quad\textit{ (the stopping cost)}\\ c(x),& \text{for }a=1\quad\textit{ (the continuation cost)}, \end{cases}")
 = \min \left\{ k(x) , c(x) + \mathbb{E}_x [C_{s-1}(\hat{X})] \right\}")


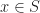
\leq c(x) + \mathbb{E}_x[k(\hat{X})]\}.")



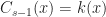


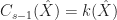
 = \min \{ k(x), c(x) + \mathbb E_x [ C_{s-1}(\Hat{X})] \} = \min \{ k(x) , c(x) + \mathbb E_x \big[ k(\hat{X} ) \big] \} = k(x).")








 = \frac{{1}/{N}}{{1}/{t}} = \frac{t}{N}.")
")

 \underbrace{ \max \left\{ 0, R_{t+1} \right\} }_{ R_{t+1} } \\ & = \max \left\{ \frac{1-t}{t} R_{t+1} + \frac{1}{N} R_{t+1} \right\} \\ & = \begin{cases} R_{t+1}, & \text{ if } R_{t+1} \geq \frac{t}{N}, \\ \frac{t-1}{t} R_{t+1} + \frac{1}{N}, & \text{ if } R_{t+1} < \frac{t}{N}. \end{cases}\end{aligned}")









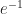

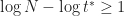


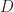

 & = p C_{s-1}(1) + q C_{s-1}(0) \\ C_s(1) & = \min \left\{ s , pC_{s-1}(1)+qC_{s-1}(0) \right\}\end{aligned}")
\}")

 = ps + q k(s-1) \quad \text{and} \quad k(0) =qD.")
 = -\frac{q}{p} + s + (D+\frac{1}{p} ) q^{s+1}")
 q^s \geq 1 \}.")

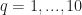
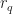
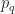

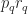
 = \max\{ x, p_t R_{t+1}(x+r_t)\}")
 : x \geq p_t ( x+ r_t)\} = \{ (x,t) : x \geq r_t p_t / (1-p_t) \}")

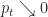
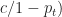









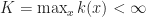

 \xrightarrow[s\rightarrow \infty]{} L(x)")
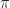

 C \mathbb P ( \tau > s) \leq \mathbb E \left[ \left\{ \sum_{t=0}^{\tau-1} c(x_{t}) + k(x_{\tau}) \right\} \mathbb I [\tau > s] \right] \leq k(x_0) \leq K.\end{aligned}")

 \leq L_s(x) \leq L(x) + K \mathbb P (\tau > s) \leq L(x) + \frac{K^2}{C(s+1)} \xrightarrow[s\rightarrow\infty]{} L(x)")

 \leq c(x) + \mathbb{E}_x[k(\hat{X})]\}")
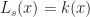

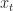


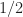


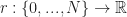

.

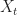
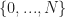

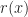
]")

 = \max\left\{ r(x), \frac{1}{2} R(x-1) + \frac{1}{2} R(x+1) \right\}")








 & = \max\left\{ r(x) , \frac{1}{2} R_{s-1}(x-1) + \frac{1}{2} R_{s-1}(x+1) \right\} \\ & \leq \max\left\{ r(x) , \frac{1}{2} G(x-1) + \frac{1}{2} G(x+1) \right\} \\ & \leq \max\left\{ r(x), G(x) \right\} = G(x).\end{aligned}")