We are interested in solving the constrained optimization problem
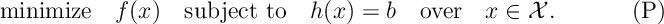
- The variables
must belong to the constraint region
, where
.
- The variables must satisfy the functional constraints
, where $latex h:
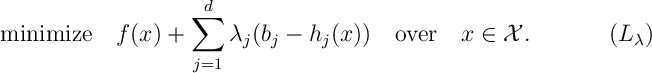 {\mathcal X}\rightarrow{\mathbb R}^d$ and
{\mathcal X}\rightarrow{\mathbb R}^d$ and .
- Variables that belong to the constraint region and satisfy the functional constraints are called feasible and belong to the feasible set
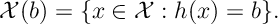
- The variables are judged according to the relative magnitude of the objective function
.
- A feasible solution to the optimization,
, is called optimal when
for all
.
- In general, an optimum
- Inequality constraints
can be rewritten as equality constraints
, where
. Then an optimization of the form can be solved over variables
. The variables
are called slack variables.
, so maximizing is the same as minimizing.
The set 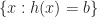

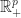
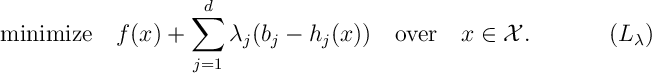
- In the above optimization, the objective function

is called the Lagrangian of the optimization problem .
- We call the components of the vector,
, Lagrange multipliers.
- We use
to notate its optimum of , if it exists.
- For each inequality constraint
is replaced by
. Because we introduced a new term
, for a finite solution to , we require
and thus, after minimizing over
, we have
. This equality is called complementary slackness.
- If
our optimal Lagrangian solution is also feasible then complementary slackness states

The unconstrained optimization is, in principle, much easier to solve and a good choice of 


Lemma [Weak Duality] For all

Proof
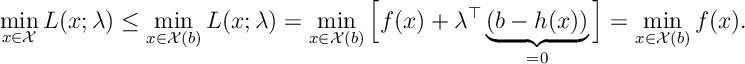

In fact, if we can make the two solutions equal then we have optimality.
Theorem 1 [Lagrangian Sufficiency Theorem] If there exists Lagrange multipliers 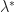


Proof As 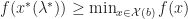
)= f(x^*(\lambda^*)) + \lambda^{*T}(b-h(x^*(\lambda^*)))\tag{as $x^*(\lambda^*)$ is feasible}")
\tag{as $x^*$ is optimal for $(L_{\lambda^*})$}")

So, 

This result gives a simple procedure to solve an optimization:
- Take your optimization and, if necessary, add slack variables to make all inequality constraints equalities.
- Write out the Lagrangian and solve optimization for
- By solving the constraints
over
is feasible.By Lagrangian Sufficiency Theorem,
Duality
Since weak duality holds, we want

- Here
and
.
- We call this optimization problem the dual optimization and, in turn, we call the primal optimization.
- Making dependence on
explicit, use
to denote the optimal value of the primal problem and
to denote the optimal value of the dual. By weak duality
. If
then we say strong duality holds.
- Observe,
, if
, otherwise. So,
and by definition
. So strong duality corresponds exactly to the saddle point condition that
=\max_{\lambda} \min_{x\in\mX} L(x;\lambda)")
Essentially, the Lagrangian approach will only be effective when we can find a 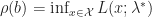
Theorem 2. 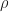
 \geq \rho(b) + \lambda^{*\T}(c-b),\qquad\text{ for all }c\in\bR^d.")
Proof.
 &= \inf_{x\in\mX}\Big\{ f(x) + \lambda^\T(b-h(x))\Big\} \\ & = \inf_{c\in\bR^d} \inf_{x\in\mX(c)} \Big\{ f(x) + \lambda^\T(b-h(x))\Big\} \\ & = \inf_{c\in\bR^d} \big\{ \rho(c) + \lambda^\T (b-c) \big\}.\end{aligned}")
So 


- Informally, states that there exists a tangent to
- The set
defines a hyperplane containing
and
lies in the half-space above
. So we call this “tangent”
- Any function
is convex if
, for
. It can be verified that this is equivalent to the condition . Optimization of convex functions may be possible with Lagrangian methods.
- We discuss the relationship between convexity, hyperplanes, duality and Lagrangian optimization in the supplementary section, Section [DHLO].
Given , for 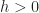
-\rho(b)}{h} \geq \lambda^*_i,\qquad \frac{\rho(b-he_i)-\rho(b)}{h} \leq \lambda_i^*.")
Thus, if
=\lambda^*_i.")
- For a maximization problem, if we interpreted
is interpreted at the price the manufacturer is prepared to pay to secure those extra goods.
- From this interpretation, we call the optimal Lagrange multiplier
a shadow price.
As noted above if
- For a constrained optimization problem we say Slater’s Condition is satisfied if the objective function
is a convex function, if constraint region
is a convex set, if for each equality constraint
the function
is linear, if there exist a feasible solution
such that all inequality constraint are satisfied with strict inequality
.
- To make life easier we assume the functions
.
Theorem 3. If Slater’s Condition holds then
To prove this we will require the following (intuitively true) result.
Theorem 4. [Supporting Hyperplane Theorem] If 

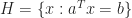
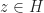

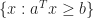
We can prove this result later, we will prove Theorem 3.
Proof of Theorem 3. By Slater’s condition the equality constraints are given by a matrix 
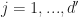
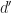

\in \bR^d\times \bR :\text{ there exists $x$ in feasible set $\mX({b}')$ with $f(x)\leq \rho$} \}")
So, roughly speaking, 

We show that 
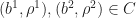




The three statements above show that 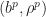
Take 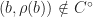
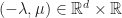
 \mu")
Provided we can choose 
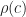
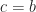
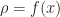


Now we show 

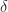

) < b_j - \delta \lambda_j \quad\text{and} \quad (H x(\delta))_j = b_j - \delta \lambda_j.")
By continuity of 


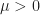

 \geq \rho(b) + \lambda^{*\T}(c-b),\qquad\text{ for all }c\in\bR^d.")
Thus, by Theorem 2
- We can choose not to remove these redundant constraints but then we have to mess arround with relative interiors, see Section [DHLO].↩
