We consider one of the simplest iterative procedures for solving the (unconstrainted) optimization
 \qquad\text{over}\qquad x\in{\mathbb R}^p")
where 
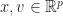
 = f(x) + \eta v \nabla f(x) +o(\eta)")
If 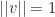

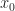
 , \qquad t\in{\mathbb N}.")
- We assume
the Hessian matrix of
satisfies
, for some
.So, by a Taylor expansion
 -f(x_t) \leq - \eta ||\nabla f(x_t)||^2 + B\eta^2 ||\nabla f(x_t)||^2,")
- We assume
. So the right-hand inequality above guarantees that
for all
.
- We assume there is a unique finite solution to our optimization.1

We now see our algorithm converges exponentially fast to its solution, so-called linear convergence.
Given the assumptions above there exists 

 - f(x^*) \leq \kappa^t \left( f(x_{0}) - f(x^*) \right),")

Rewriting , we have  - f(x^*) \leq f(x_t) - f(x^*) - \eta (1- B\eta) ||\nabla f(x_t)||^2")
Using lower bound on the Hessian, we bound 
-f(x_t) &\geq & (x^*-x_t) \cdot \nabla f(x_t) + b || x^*-x_t||^2 \\ &\geq & \min_{x'}\left\{ x'\cdot \nabla f(x_t) + b || x'||^2\right\}=-\frac{1}{4b}|| \nabla f(x_t)||^2 \end{aligned}") C
C
ombining the last two inequalities, we have as required,
 - f(x^*) \leq \underbrace{(1- 4b\eta (1-B \eta))}_{=\kappa} \Big[ f(x_{t}) - f(x^*) \Big].")
Finally for , we reapply our Hessian lower-bound assumption and use the above bound for 
 \nabla f(x^*) + b|| x_t-x^* ||^2 \\ & \leq & f(x_t)-f(x^*) \\ &\leq &\kappa_1^t (f(x_0)-f(x^*)). \end{aligned}")
Projected Gradient Descent
We consider a simple iterative procedure for solving a constrained optimization
 \qquad\text{over}\qquad x\in {\mathcal X}")
where 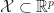
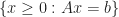

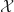

= \argmin_{y\in {\mathcal X}} || x - y ||^2")
and then, from
 ), \qquad t\in{\mathbb N}")
- After projecting it need not be true that
and our proof will study the distance between
and the optimal solution
rather than the gap
.
• The key observation is that making a projection cannot increase distances
[PGD:proj] -P_{\mathcal X}(y)|| \leq ||x-y||")
For all 
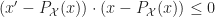

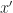
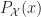
- P_{\mathcal X}(x))\cdot (x-P_{\mathcal X}(x)) \leq 0\quad")
- P_{\mathcal X}(y))\cdot (y-P_{\mathcal X}(y)) \leq 0.")
Adding together and then applying Cauchy-Schwartz implies
- P_{\mathcal X}(x))||^2 \\ &\leq & (y-x)\cdot (P_{\mathcal X}(y)-P_{\mathcal X}(x)) \\ &\leq & ||y- x|| \; ||P_{\mathcal X}(y)- P_{\mathcal X}(x))||,\end{aligned}")
as required.
If the gradient of iterates are bounded, 
 -f(x^*) \leq \frac{\sum_{t=0}^T \eta^2_t}{\sum_{t=0}^T \eta_t} \max_{0\leq t \leq T} ||\nabla f(x_t)||^2+ \frac{||x^*-x_0||^2}{ \sum_{t=0}^T \eta_t} .")
Hence if 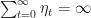
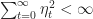
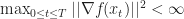

 ) -x^* ||^2 \\ &\underbrace{\leq}_{\text{by Lemma }\ref{PGD:proj}} & || x_t-x^*-\eta_t \nabla f(x_t ) ||^2 \\ &= & || x_t-x^*||^2 + \eta_t \underbrace { \nabla f(x_t) \left(x^*-x_t\right)}_{\substack{\leq f(x^*)-f(x_t),\\\text{ by convexity}}} + \eta_t^2 || \nabla f(x_t)||^2\\ & \leq & || x_t-x^*||^2 + \eta_t\left( f(x^*)-f(x_t)\right) + \eta_t^2 || \nabla f(x_t) ||^2\end{aligned}")
Recurring the above expression yields -f(x_t)\right) + \sum_{t=0}^T \eta_t^2 || \nabla f(x_t) ||^2\\ & \leq & || x_0-x^*||^2 + \left( f(x^*)-\min_{0\leq t\leq T} f(x_t)\right) \sum_{t=0}^T \eta_t +\max_{0\leq t \leq T} || \nabla f(x_t) ||^2 \sum_{t=0}^T \eta_t^2 . \end{aligned}") Rearranging the above gives the required result.
Rearranging the above gives the required result.
- This assumption is not really needed, but it saves space.↩
