- Positive Programming, Negative Programming & Discounted Programming.
- Optimality Conditions.
Thus far we have considered finite time Markov decision processes. We now want to solve MDPs of the form
 = \maxi_{\Pi \in {\mathcal P} } \quad R(x,\Pi) := \mathbb{E}_{x_0} \left[ \sum_{t=0}^{\infty} \beta^{t} r(X_t,\pi_t) \right]")
(Notice rewards no longer depend on time.)
Def 1. [Positive, Negative, and Bounded programming] [IDP:PosNegDis]

Maximizing positive rewards, 
Minimizing positive losses, 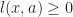
Maximizing bounded discounted rewards, 
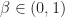
Def 2. [Minimizing Losses]So far we have considered the maximization of rewards; however often we want to minimize losses or costs. When we do so we will use the following notation:
 = \mini_{\Pi \in {\mathcal P} } \quad C(x,\Pi) := \mathbb{E} \left[ \sum_{t=0}^{\infty} \beta^t l(X_t, \pi_t) \right]")
Ex 1. Show that, for positive programming,
 := \mathbb{E} \Big[ \sum_{t=0}^{T -1} \beta^{t} r(X_t,\pi_t) \Big] \nearrow R(x,\Pi) \leq V(x).")
Ex 2. [Continued] Show that, for discounted programming,
 := \mathbb{E} \Big[ \sum_{t=0}^{T -1} \beta^{t} r(X_t,\pi_t) \Big] \rightarrow R(x,\Pi) \leq V(x).")
Ex 3. [Continued] Show that
 := \mathbb{E} \Big[ \sum_{t=0}^{T -1} \beta^{t} l(X_t,\pi_t) \Big] \nearrow C(x,\Pi) \geq L(x).")
for a negative program.
Note that negative programming is not simply multiplying positive programming by minus one, because from [3] we see that the terms 
Bellman’s Equation for positive programming
We now discuss Bellman’s equation in the infinite time horizon setting. Previously we solved Markov Decisions Processes inductively with Bellman’s equation. In infinite time, we can not directly apply induction; however, we see that Bellman’s equation still holds and we can use this to solve our MDP.
Thrm 1. Consider a positive program or a discounted program. Given the limit 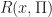
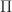
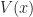
 = \max_{a\in {\mathcal A}} \Big\{ r(x,a) + \beta {\mathbb E}_{x,a} \left[ V(\hat{X}) \right] \Big\}.")
Moreover, if we find a function 
 = \max_{a\in {\mathcal A} } \left\{ r(x,a) + \beta \mathbb{E}_{x,a} \left[ R(\hat{X}) \right] \right\}")
and we find a function 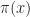
 \in \argmax_{a\in \mathcal A} \left\{ r(x,a) + \beta \mathbb E_{x,a} \left[ R(\hat{X} \right] \right\}")
Then 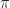

The above theorem covers the cases of positive and discounted programming. The case of negative programming is a little more subtle. We, now, prove Thrm 1. On first reading, you may wish to take this theorem as a given and skip to [15].
Ex 4. [Proof of Thrm 1] Show that
 = r(x,\pi_0) + \beta \mathbb E_{x,\pi_0} \left[ R(\hat{X},\hat{\Pi}) \right]")
where 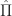
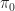

Ex 5. [Continued] Show that
 \leq \sup_{\pi_0 \in {\mathcal A}} \left\{ r(x,\pi_0) + \beta \mathbb{E}_{x,\pi_0} \left[ V(\hat{X}) \right] \right\}.")
In the following exercise, we let 

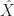
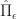
 \geq V(\hat{\Pi}) - \epsilon.") Ex 6. [Continued] Show that
Ex 6. [Continued] Show that
 \geq r(x,a) + \beta \mathbb E_{x,a} [V(\hat{X})] - \epsilon \beta .")
Ex 7. [Continued]
At this point we have shown the first part of Thrm 1. Now we need to show that a policy that satisfies the Bellman Equation is also optimal.
Ex 8. [Thrm 1, 2nd part] Show that if if we find a function
 = \max_{a\in {\mathcal A} } \left\{ r(x,a) + \beta \mathbb{E}_{x,a} \left[ R(\hat{X}) \right] \right\}, \quad \pi(x) \in \argmax_{a\in \mathcal A} \left\{ r(x,a) + \beta \mathbb E_{x,a} \left[ R(\hat{X} \right] \right\}")
then 
Ex 9. For positive and discounted programming, suppose that
 \geq \max_{a\in {\mathcal A} } \left\{ r(x,a) + \beta \mathbb{E}_{x,a} \left[ R(\hat{X},\pi) \right] \right\}")
show that
 \geq R_t(x,\tilde \Pi ) + \beta^t \mathbb E [ R(\tilde{X}_t,\Pi ) ],")
where here 


Ex 10. [Continued] Now show that
 \geq R(x,\tilde{\Pi})")
and thus show that the policy
Negative Programming
The analogous result to Thrm [IDP:Bellman] for Negative programming is much weaker. This can be see from [IDP:CostLimit] when compared with [[IDP:RewardLimit]]. Essentially interations of negative programming over shoot the optimal value function.
Def 3. A policy
Ex 11. Consider a MDP with a finite number of actions and assume the Bellman equation has a solution. Show that there is a stationary policy solving the Bellman equation.
Thrm 2. Consider a negative program. Given the limit 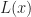
 = \min_{a\in {\mathcal A}} \Big\{ l(x,a) + \beta {\mathbb E}_{x,a} \left[ L(\hat{X}) \right] \Big\}.")
Moreover, any stationary policy
 \in \argmin_{a\in {\mathcal A} } \left\{ c(x,a) + \beta \mathbb{E}_{x,a} \left[ L(\hat{X}) \right] \right\}")
is optimal.
So the Bellman equation is still correct, but as the above result suggests, simply finding a solution to the Bellman equation is not sufficient. We need to find the optimal solution first and then we need to solve with a stationary policy.
Ex 12. Show that the optimal value function satisfies
Ex 13. Argue that the stationary policy
= C_T(x,\pi) +\beta^T \mathbb E_{x,\pi} [L(X_{T+1})]") Ex 14. [Continued] Show that
Ex 14. [Continued] Show that
= C_T(x,\pi)")
Ex 15. A gambler has 
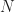
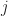





Ex 16. [Geometric stopping or discount factor] Consider a positive program and suppose that after an independent geometrically distributed parameter 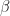
 = \mathbb E_{x} \bigg[ \sum_{t=0}^{\tau_\beta } r(X_t,\pi_t)\bigg]\, .") Argue that this has the same rewards as a discounted program with discount factor
Argue that this has the same rewards as a discounted program with discount factor
Answers
Ans 1. Apply the Monotone Convergence Theorem.
Ans 2. Apply the Bounded Convergence Theorem.
Ans 3. Again apply Monotone Convergence Theorem.
Ans 4. We know that
 = r(x,\pi_0) + \beta \mathbb E [ R_{t-1}(\hat{X},\hat{ \Pi} ) ]")
Applying limits as 
Ans 5. By [4] and the optimality of
 & = r(x,\pi_0) + \beta \mathbb E_{x,\pi_0} \left[ R(\hat{X},\hat{\Pi}) \right] \\ & \leq r(x,\pi_0) + \beta \mathbb E_{x,\pi_0} \left[ V(\hat{X}) \right]\, .\end{aligned}")
Now maximize the left hand side of the above inequality.
Ans 6. We have that
 & \geq R(x,\pi_\epsilon) = r(x,a) + \beta \mathbb{E}_{x,a} \left[ R(\hat{X},\hat{\Pi}_\epsilon) \right] \\ & \geq r(x,a) + \beta \mathbb{E}_{x,a} \left[ V(\hat{X}) \right] - \epsilon \beta\end{aligned}")
The first inequality holds by the sub-optimality of 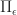
Ans 7. Take the inequality in [6], maximize over 
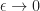
 \geq \max_{a\in {\mathcal A}} \Big\{ r(x,a) + \beta {\mathbb E}_{x,a} \left[ V(\hat{X}) \right] \Big\}.")
The above inequality and [5] give the result.
Ans 8. It is clear that
 = r(x,\pi(x)) + \beta \mathbb E_{x,\pi(x)} [R(\hat{X})].")
Thus by Ex 8 in Markov chains, we have that 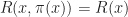
Ans 9. Suppose that policy 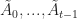

 & \geq r(\tilde{X}_0,\tilde A_0) + \beta \mathbb E_{\tilde{X}_0,\tilde A_0} \left[ R(\tilde X_1 , \Pi ) \right] \\ & \geq r(\tilde X_0,\tilde A_0) + \beta \mathbb E_{\tilde X_0,\tilde A_0} \left[ r(\tilde{X}_1,\tilde{A}_1) + \mathbb E_{\tilde X_1,\tilde A_1} [ R(\tilde{X}_2,,\Pi) ] \right] \\ &\; \vdots \\ &\geq \mathbb E \underbrace { \left[ \sum_{\tau=0}^{t-1} \beta^{\tau} r(\tilde{X}_{\tau},\tilde{A}_{\tau}) \right] }_{ = R_t(x,\tilde \Pi ) } + \beta^t \mathbb E \left[ R(\tilde{X}_t,\Pi) \right]\end{aligned}")
In the second inequality we again apply our initial inequality (this time to the term 

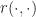
Ans 10. By [9] we have that
 \geq R_t(x,\tilde \Pi ) + \beta^t \mathbb E [ R(\tilde{X}_t,\Pi ) ] \geq R_t(x,\tilde{\Pi}) \xrightarrow[t\rightarrow \infty]{} R(x,\tilde \Pi ).")
Since 
Ans 11. As actions are finite, for each
Ans 12. Convince yourself that [4-7] apply in this case.
Ans 13.
 & = \min_{a\in \mathcal A} \left\{ c(x,a) + \beta \mathbb E_{x,a} [ L(X_1) ] \right\} \\ & = c(x,\pi(x)) + \beta \mathbb E_{x,\pi(x)} \left[ L(X_1) \right]\\ & = c(X_0,\pi(X_0)) + \beta \mathbb E_{X_0,\pi(X_0)} \left[ c(X_1,\pi(X_1)) + \beta \mathbb E_{X_1,\pi(X_1)} \left[ L(X_2) \right] \right]\\ & =C_1(x,\pi) +\beta^2 \mathbb E_{x,\pi} [L(X_2)] \\ & \;\;\vdots \\ & = C_T(x,\pi) +\beta^T \mathbb E_{x,\pi} [L(X_{T+1})] \end{aligned}")
Ans 14.
 = C_T(x,\pi) + \beta^{T} \mathbb E_{x,\pi} [L(x_{T+1})] \\ \geq C_T(x,\pi) \xrightarrow[T\rightarrow \infty]{} C(x,\pi)") So the policy has lower cost, thus is optimal.
So the policy has lower cost, thus is optimal.
Ans 15. The Bellman equation for this problem is
 = \max_{j\in\{1,...,i\}} \left\{ pV(i+j) + qV(i-j) \right\}")
Let 

 = p R(i+1) + q R(i-1) \quad \implies \quad R(i) = \frac{ 1-\Big(\frac{q}{p}\Big)^i }{ 1-\Big(\frac{q}{p}\Big)^N }")
You can check that
^i = \max_{j=1,...,N } \left\{ p \Big( 1-\Big(\frac{q}{p}\Big)^{i+j} \Big) + q \Big( 1-\Big(\frac{q}{p}\Big)^{i-j} \Big) \right\}")
where the maximum above is maximized at 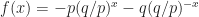
The
Ans 16.
\bigg] = \mathbb E_{x} \bigg[ \sum_{t=0}^{\infty } \mathbb I [\tau_\beta \geq t] r(X_t,\pi_t)\bigg] = \mathbb E_{x} \bigg[ \sum_{t=0}^\infty \beta^t r(X_t,\pi_t) \bigg].")
