We consider the setting of sequentially optimizing the average of a sequence of functions, so called online convex optimization.
For 

- An unknown convex loss function
is set.
- the algorithm picks a point
and incurs a loss
.
- The gradient
is revealed.
The quantity that we are interested in minimizing is the regret of the aggregate loss between a sequence of choices 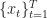

:= \sum_{t=1}^T l_t(x_t) - \sum_{t=1}^T l_t(x)")
We now define a specific selection rule for 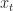

Mirror Descent
Initialize by setting by setting 
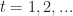
- set
 \}.")
- As described above the algorithm the incurs loss
and observes
.
- The algorithm then selects
.")
- Notice by Fenchel-Duality, here that
where
is the Legendre-Fenchel Transform of
. In other words, we don’t need to solve the optimization of
from an appropriate convex function - We will say that
-strongly convex if
-F(x) \geq (y-x)^\top \nabla F(x) -\frac{\beta}{2} || y- x||^2")
- We will say that
is
-smooth if it is differentiable and its derivative is Lipschitz continuous with constant
 - \nabla G(x)|| \leq \gamma || y- x ||.")
- It is left as an exercise, to show that if
– smooth.

Thrm: If
 \leq F(x) + F(x_1) + \frac{1}{2\beta} \sum_{t=1}^T || \nabla l_t(x_t) ||^2")
Proof: Notice by the convexity of 
 - \sum_{t=1}^T l_t(x)")
 \nabla l_t (x_t)")

Where in the equality, we just introduced the notation 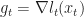
Now notice that given our definition of 
 \right\}.")
In some sense our choice of 
Now since  - F^*(\theta_t) \leq -g_t^\top \nabla F^*(\theta_t) + \frac{1}{2\beta} || g_t||^2 = g_t^\top x_t + \frac{1}{2\beta} || g_t||^2.")
Where we note that, by definition,
 - F^*(\theta_1) \geq x^\top \theta_{T+1} - F(x) - F^*(\theta_1)")
 - F^*(\theta_1)")
where in the last inequality we note the definition of 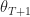


 - F^*(\theta_t)")
 - F^*(\theta_1)")
 - F(x_1)")
In the last equality, we apply the Fenchel-Young Inequality to 
 = \sum_{t=1}^T l_t(x_t) - \sum_{t=1}^T l_t(x)")

 + F(x_1) + \sum_{t=1}^T \frac{1}{2\beta}|| g_t||^2")
as required.
