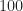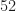Markov chains are the primary stochastic process used in queueing theory. The main elements of a Markov chain are its state and the independent randomness used to generate future states. This creates a very clean and natural form of dependence for which many properties are known. We will cover a few important properties of Markov chains, including recurrence, transience, and the existence of stationary distributions.
Continue reading “Discrete-time Markov chains — A Quick Look”Author: appliedprobability
Zero-Order Stochastic Optimization: Keifer-Wolfowitz
We want to optimize the expected value of some random function. This is the problem we solved with Stochastic Gradient Descent. However, we assume that we no longer have access to unbiased estimate of the gradient. We only can obtain estimates of the function itself. In this case we can apply the Kiefer-Wolfowitz procedure.
The idea here is to replace the random gradient estimate used in stochastic gradient descent with a finite difference. If the increments used for these finite differences are sufficiently small, then over time convergence can be achieved. The approximation error for the finite difference has some impact on the rate of convergence.
Continue reading “Zero-Order Stochastic Optimization: Keifer-Wolfowitz”
The Law of Large Numbers and Central Limit Theorem
Let’s explain why the normal distribution is so important.
(This is a section in the notes here.)
Continue reading “The Law of Large Numbers and Central Limit Theorem”
Continuous Probability Distributions
We consider distributions that have a continuous range of values. Discrete probability distributions where defined by a probability mass function. Analogously continuous probability distributions are defined by a probability density function.
(This is a section in the notes here.)
Discrete Probability Distributions
There are some probability distributions that occur frequently. This is because they either have a particularly natural or simple construction. Or they arise as the limit of some simpler distribution. Here we cover
- Bernoulli random variables
- Binomial distribution
- Geometric distribution
- Poisson distribution.
(This is a section in the notes here.)
Random Variables and Expectation
Often we are interested in the magnitude of an outcome as well as its probability. E.g. in a gambling game amount you win or loss is as important as the probability each outcome.
(This is a section in the notes here.)
Conditional Probability
(This is a section in the notes here.)
Conditional probabilities are probabilities where we have assumed that another event has occurred.
Counting Principles
(This is a section in the notes here.)
Counting in Probability. If each outcome is equally likely, i.e. 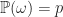
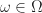
 = \sum_{\omega \in \Omega } p= |\Omega | p") (where
(where 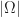
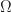
 = \frac{1}{| \Omega |} \,\qquad \text{ for all } \omega \in \Omega .\end{aligned}")
Probability and Set Operations
(This is a section in the notes here.)
We want to calculate probabilities for different events. Events are sets of outcomes, and we recall that there are various ways of combining sets. The current section is a bit abstract but will become more useful for concrete calculations later.
What is Probability?
(This is a section in the notes here.)
I throw a coin