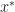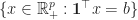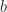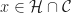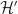The Simplex Theorem suggests a method for solving linear programs . It is called the Simplex Algorithm.

- The tableau in Step 2 is called the Simplex Tableau. It stores all the information required in the Simplex Theorem: matrix
expressed in terms of basis
,
; the basic feasible solution excluding non-zero entries
; the reduced cost vector
, and the cost of the current solution
.
- The bottom row of the simplex tableau is called the objective row.
- Observe that the columns of the matrix
in this identity matrix to an entry of the column vector
.
- The Simplex Algorithm also works for inequality constraints. For an optimization with inequality constraints
, when we add slack variables
, we have equality constraints
. Observe for new matrix
,
is a basic solution. Thus, provided
,
- In Step 3, we call
the pivot row,
the pivot column, and
the pivot.
If Step 2 follows Step 3, we need to calculate 



- In other words, The matrix
is exactly the vector formed by multiplying and adding rows of
In addition, Step 3 can be expressed in terms of the Simplex Tableau in the following way.

- In Step 3a, we do not include the final entry of the objective row in our calculations.
- In Step 3b, we do not include the entry
, corresponding to the objective row, in our calculations.
Let’s now go through a simple example in detail.
Example 1.

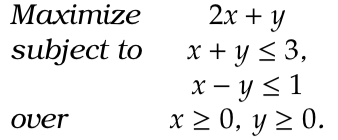
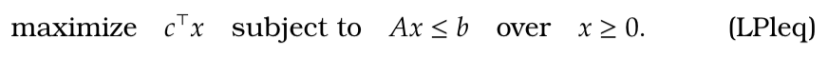
Answer 1. This is the same as
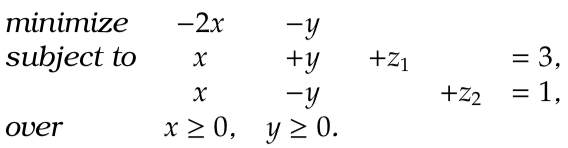
Let’s go through the steps of the algorithm.
Step 1: we find a basis. As we noted inequality constraints mean we can start with all slack variables in the basis.
Step 2: write out the simplex tableau:

The basis variables, 
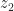

Step 3: the reduced cost for both variables 
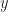
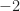
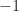

The 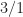
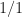
Step 2: For the matrix to be in the correct form, we must multiply and subtract the pivot row from all other rows so that the only non-zero entry in the pivot row is a
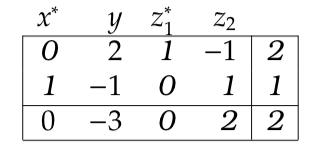
Step 3: The only negative reduced cost is for

Step 2: dividing the pivot row by 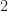
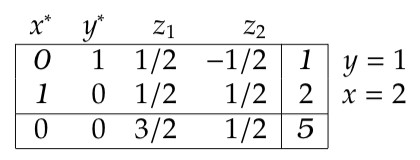
The reduced costs in the objective row are all positive. Thus, the current solution is optimal. Once again we read this solution from the simplex tableau by associating basis variables with the final column through the 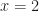

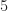

We can make more general observations from our example, for the following optimization:
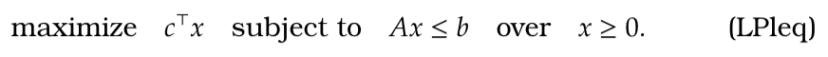
- Once slack variables are added to , these slack variables can form a basis with
.
- If
,
forms a basic feasible solution, and since our objective does not constrain slack variables, the following tableau forms a correctly initialized simplex tableau
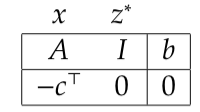
- Now considering this tableau again with respect to another basis,
and
, we get
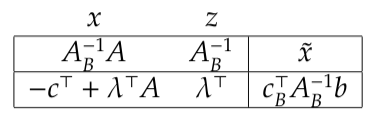
- From the tableau above, once again
gives the values of basic variables; we can also find our current inverse matrix
; we can find our dual variables
.
- The Simplex Algorithm maintains primal feasibility
; as any variable in the basis has a zero in the objective row, the Simplex Algorithm maintains complementary slackness
and
; when the Simplex Algorithm is complete the objective row is positive, so we have dual feasibility
and
.
- In other words, whilst maintaining primal feasibility and complementary slackness, we search for dual feasibility. Once this is found by Linear Programming Lemma 2, our solution is optimal both for the primal and dual problem.
Two Phase Simplex
We consider the method of two stage simplex with the following example.  which, adding slack variables, is equivalent to this first problem
which, adding slack variables, is equivalent to this first problem

Observe that, unlike before, setting 
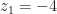

For example, we consider the second problem
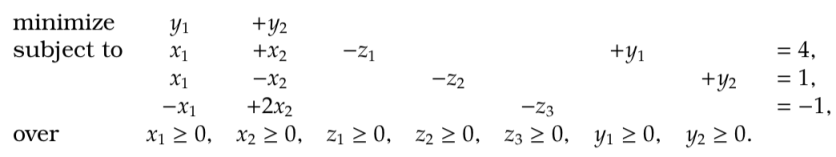
- We added an extra variable
tracts the amount we have violated any of our constraints.
- We then chose to minimize
which we interpret as the total amount that we have violated our constraints.
- Note by adding these extra variables there is a bfs with
. So, we can solve the second problem using the Simplex Algorithm.
Both problems have the same number of non-zero entries in a bfs, namely, 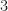

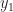
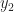
Phase I: Solve the second problem, where we added additional variables for violated constraints.
Phase II: Removing the additional variables we have a bfs for the first problem. We then solve the second problem.
So now we can solve this problem using the Simplex algorithm in two phases:
Phase I:
We have written down the simplex tableau for the second problem and added an additional objective row for the objective of the first problem. Notice the simplex tableau is not in the correct form. First, we want 

We now proceed to optimize the this tableau whilst treating the additional objective row as though it was just an additional constraint.

We are now at an optimal solution for the the first phase. In particular, we are at a basic feasible solution where 

Phase II:


So we have now solved our original optimization problem. The optimal solution is 

Dual Simplex
Dual simplex is another method for finding a basic feasible solution from a non-feasible basic solution. The Simplex Algorithm maintains feasibility of the primal problem; this is why we minimize ). The Simplex Algorithm searches for a solution that is dual feasible. The dual simplex takes a solution that is dual feasible and searches for a primal feasible solution.
We continue our example from the last section. Here we solved, . We now notice we forgot a constraints 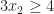
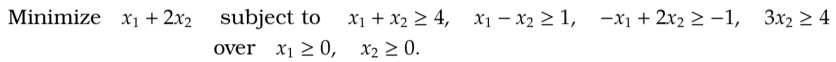
Our previous optimal simplex tableau was

But now notice, our current solution 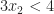

Multiplying the 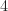

Our current basic solution has 
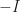


We select a pivot on rows that maintains dual feasibility and increases our objective to a primal feasible solution i.e. 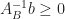

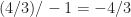

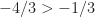

Our current solution is feasible and, as our pivot kept our objective row positive, our solution is now optimal. In particular, 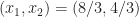
Linear programming and simplex results
Theorem 1. The extreme points of 
Proof. Recall that we assume each 




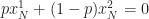




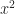


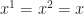
Conversely, take any feasible 

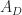


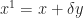

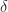

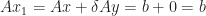

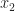
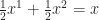

Theorem 2. Any linear program with a finite optimum has at least one optimum at an extreme point.
Lemma 1. For a closed convex set 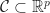




Proof. Assume 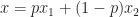
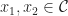

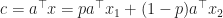
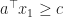


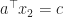

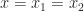
Theorem 3 [Carathéodory’s Theorem] Every closed bounded convex set 

Proof. We prove the result by induction on 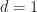

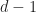
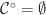
Take 
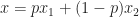





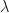
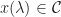


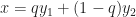
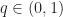

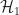

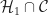
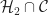
Now, we reduce the number of extreme points required to express 

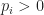

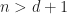
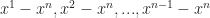


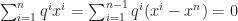
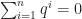

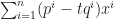
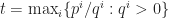

Proof of Theorem 2. Let