- Weighted majority algorithm its variant for Bandit Problems.
We consider the problem of learning the ‘best’ action amongst a fixed reference set. Although our modelling assumptions will be quite different, we follow notation is somewhat similar to Section [DP]. We consider the following setting:
Consider actions 
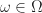

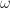
![r(a;\omega)\in [0,1]](https://s0.wp.com/latex.php?latex=r%28a%3B%5Comega%29%5Cin+%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

Def [Policy] Over time outcomes 

At each time 
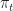

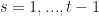

In other words at each time the past states and rewards are known the policy. The policy then must do the best it can to accumulate rewards.
Def [Rewards/Regret] The total reward by time 
:=\sum_{t=1}^T r(\pi_t,\omega_t).")
The regret of policy
 := \max_{a\in {\mathcal A} } R_T(a) - \bE [R_T(\Pi)].")
- It is good to think of outcome
- It is good to think of rewards
in the same way as we consider rewards for an MDP
(Though since there is no state we do not require notation for
).
- The regret compare how well our policy compares with the best fixed reward. I.e. retrospectively, we “regret” not making the best fixed choice.
- A regret of zero as
means we do as well as the best fixed choice. This is sometimes called Hannan consistency.
We are interested in how a policy 
Ex 1. [A Regret Lower-Bound] Consider that there are two outcomes 

![[r(A,A),r(A,B)] = [1,0]](https://s0.wp.com/latex.php?latex=%5Br%28A%2CA%29%2Cr%28A%2CB%29%5D+%3D+%5B1%2C0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![[r(A,B),r(B,B)] = [0,1]](https://s0.wp.com/latex.php?latex=%5Br%28A%2CB%29%2Cr%28B%2CB%29%5D+%3D+%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)




Suppose that each 
 \right]\geq C \sqrt{T}")
for some constant 
Ans 1. Note that, since rewards are IID with probability 
 ] = \frac{1}{2} T")
Further note that 
 = \frac{T}{2} + \epsilon_T, \qquad R_T(B) = \frac{T}{2} - \epsilon_T")
We know that 
")
and
 := \max_{a\in {\mathcal A} } R_T(a) - \bE [R_T(\Pi)] = | \epsilon_T | .")
These last to observations give the result.
The Weighted Majority Algorithm
We now consider a policy, that can achieve the lower bound suggested by [[OL:Ran]].
We prove the following result for the Weighted Majority Algorithm.
Thrm 1
 \right] \leq \eta^{-1} \log(N) + \frac{\eta T}{2},")
and, 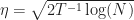
 \right] \leq 2\sqrt{2T \log(N)}.")
Other related results are also possible. We also require the following probability bound:
Lemma [Hoeffding’s Inequality] For a Random variable bounded on

Ex 2 Prove that
 = N \prod_{t=1}^T {\mathbb E} e^{\eta r(\pi_t,y_T)}.")
Ans 2  } }{W_t} & = N \prod_{t=1}^T \sum_i e^{\eta r_t(i)} \underbrace{ \frac{e^{\eta R_{t-1}(i)}}{W_t} }_{ = P_t(i) }\\ & = N \prod_{t=1}^T \mathbb E\left[ e^{\eta r(\pi_t,\omega_t)} \right] \end{aligned}")
Ex 3 [Continued] Show that
+ \eta^2 T}")
Ans 3 Apply Hoeffding’s Inequality.
}] \leq \exp\Big\{ \eta {\mathbb E} r_t(\pi_t) + \frac{\eta^2}{2}\Big\}.")
Ex 4 [Continued]
 } \leq W_{T+1}")
Ans 4 Trivial from definitions.
Ex 5 [Continued]
] \leq \eta^{-1} \log(N) + \frac{\eta T}{2}.")
Ans 5 Combine [3] and [4], take logs and rearrange.
Ex 6 [Continued] Finally show that
 ] \leq 2\sqrt{2T \log(N)}.")
Ans 6 Minimize [5] over 
Multi-armed Bandits: Non-Stochastic
We consider a multi-armed bandit setting for online learning.
Def [Bandit Policy] A bandit policy is a policy, cf. [[OL:Policy]], where 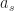
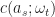
We consider a version of the weighted majority algorithm for this multi-armed bandit problem.
Note here that, since the policy choice 
 \leq \frac{1}{\eta} \log N + \frac{\eta}{2} T N.")
and for appropriate
 \leq 2\sqrt{2TN \log N}")
First we collect together a few facts then the proof proceeds very similar to the weight majority algorithm proof.
Ex 7 Show that for


(We do the result for losses rather than rewards because of this bound.1)
Ans 7 Follows as 4th term in the Taylor expansion is positive.
Ex 8 Show that
] = c(a;\omega_t)")
Ans 8
] = P_t({a}) \frac{c(a;\omega)}{P_t(a)} = c(a;\omega)")
Ex 9 Show that
{\mathbb E}[\hat{c}_t(a,\omega_t)^2] \leq 1")
Ans 9 Similar to [8],
{\mathbb E}[\hat{c}_t(a,\omega_t)^2] = P_t(a)\cdot P_t({a}) \frac{c(a;\omega)^2}{P_t(a)^2} = c(a;\omega)^2 \leq 1 \, .")
Ex 10 Show that
 \hat{c}_t ( a ; \omega ) = c(\pi_t ; \omega )")
(Note: here we are not taking an expectation with respect to 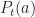
Ans 10
 \hat{c}_t(a;\omega_{t}) = \sum_a P_t(a) \frac{c(a;\omega_{t})}{P_t(a)} {\mathbb I}[\pi_{t}=a] = c(\pi_t;\omega_{t})")
Ex 11 Show that
 + \eta^2 \sum_{a\in \mathcal A} P_t(a) \hat{c}_t(a, \omega_t)^2 \right)")
Ans 11 This is the same as [2-3] but use [7] at the last step instead of Hoeffding’s Inequality. Specifically,
}{W_t} = \sum_{a\in\mathcal A} \frac{w_{t}(a)}{W_t} e^{-\eta \hat{c}_t(a;\omega_t)} & \leq \sum_{a\in\mathcal A} P_{t}(a) \left( 1- \eta \hat{c}_t(a ; \omega_t) + \frac{\eta^2}{2} \hat{c}_t(a ; \omega_t )^2 \right) \\ & \overset{[\ref{OL:EEE3.5}]}{=} 1 - \eta c(\pi_t,\omega_t) + \frac{\eta^2}{2} \sum_{a\in\mathcal A} P_{t}(a) \hat{c}_t(a;\omega_t )^2.\end{aligned}") Now multiply for
Now multiply for
Ex 12 Show that for all
 \leq \log {W_{T+1}}.")
Ans 12 Similar to [4] ,
 \geq w_{T+1}(a) = e^{-\sum_{t=1}^T \eta \hat{c}_{t}(a ; \omega_t) }")
Now take logs.
Ex 13 Show that
- \sum_{t=1}^T \hat{c}_t(a;\omega_t) \leq \frac{1}{\eta}\log N + \eta \sum_{t=1}^T \sum_{a\in{\mathcal A}} P_{t}(a)\hat{c}_t(a; \omega_t)^2")
Ans 13 Combine inequalities [11] and [12] and taking logs gives
 \leq +\log N -\eta C_T(Exp^3) + \eta^2 \sum_{t=1}^T \sum_{a\in{\mathcal A}} P_{t}(a)\hat{c}_t(a; \omega_t)^2") and rearrange. (Note: you need to use that
and rearrange. (Note: you need to use that 
Ex 14 Show that
 \leq \frac{1}{\eta} \log N + \frac{\eta}{2} T N.")
Ans 14 Take expectations on both sides of [13]
 \right] - \underbrace{ \mathbb E \left[ \sum_{t=1}^T \hat{c}_t(a;\omega_t) \right] }_{ \overset{[\ref{OL:EEE2}]}{=} C_T(a) } \leq \frac{1}{\eta}\log N + \eta \sum_{t=1}^T \sum_{a\in{\mathcal A}} \underbrace{ \mathbb E \left[ P_{t}(a)\hat{c}_t(a; \omega_t)^2 \right] }_{ \overset{[\ref{OL:EEE3}]}{\leq} 1 }") (Here the first “[??]” is Ex 8 the second is Ex 9) Now minimize the lefthand-side to give the regret.
(Here the first “[??]” is Ex 8 the second is Ex 9) Now minimize the lefthand-side to give the regret.
Ex 15. Show that, for an appropriate choice of
Ans 15. Now minimize over
- We could modify the policy for rewards by un-elegantly subtracting from the max reward.↩
