We briefly describe an Online Bayesian Framework which is sometimes referred to as Assumed Density Filer (ADF). And we review a heuristic proof of its convergence in the Gaussian case.
Bayes Rule gives
 = \frac{ P(y_{t+1} |\theta) p(\theta |D_t) }{ \int P(y_{t+1} |\theta) p(\theta |D_t) d \theta }")
For data 
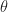

ADF suggests projecting data at time 

Update:
 ) = \frac{ P(y_{t+1} |\theta) p(\theta | par(t) ) }{ \int P(y_{t+1} |\theta) p(\theta |D_t) d \theta }")
Project:
 ) || p(\cdot | par) )")
Here 


Remark. Note that for exponential families of distributions:
 \propto \exp \left\{ - \sum_k \alpha_k f_k(\theta) \right\}")
then matching moments of 
Let’s assumes that 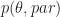
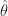

Under this one can argue that
(1)
 - \hat \theta_i (t) = \sum_j C_{ij}(t) \partial_j \log \mathbb E_u [ P(y_{t+1} | \hat \theta (t) + u ) ]")
and 
(2)
 = C_{ij}(t) + \sum_{kl} C_{ik}(t) C_{lj}(t) \partial_k \partial_l \log \mathbb E_u [P(y_{t+1} | \hat \theta (t) + u) ]\, .")
Here 

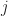

Quick Justification of (1) and (2)
Note that
^2 }{2c} \Big\} d\theta \\ = & \frac{ \int \frac{1}{\sqrt{2\pi c}} \frac{(\theta - \hat \theta^0 )}{c} \exp \{ - \frac{(\theta - \hat \theta^0 )^2}{2c} \} d\theta }{ \int \frac{1}{\sqrt{2\pi c}} \exp \{ - \frac{(\theta - \hat \theta^0 )^2}{2c} \} d\theta } \\ = & \hat \theta^1 - \hat \theta^0\end{aligned}")
A similar calculation gives the other expression on
For
 + u) ]")
This gives the differential equation

This implies

because
![]()
We assumes 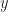

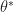
(3)
 \partial_i \log P(y|\theta^*) dy = 0")
So
}{t} & = \lim_{t\rightarrow\infty} \frac{1}{t} \int^t_0 V(s) ds \\ &= \mathbb E_Q [ \partial_k \partial_l \log \mathbb E_u [P(y_{t+1} | \theta^* + u) ] ] \\ &\approx \mathbb E_Q [ \partial_k \partial_l \log \mathbb E_u [P(y_{t+1} | \theta^* ) ] ] = J(\theta^*)\end{aligned}")
The last approximation that removes the normal distribution error needs justifying. The inequality with 


In principle 
}{t} = const \quad\text{and}\quad \lim_{t\rightarrow\infty} \left( t C(t) \frac{C^{-1}(t)}{t} \right) = I")
imply that
 = const^{-1} \cdot I")
so 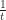
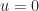

 \sim \frac{A^{-1}}{t} = \frac{J(\theta^*)^{-1}}{t}")
Next we start to analyse the error:
 = \theta^*_i + \epsilon_i(t)")
He notes that by and then a Taylor expansion that

Next we see that using

The sum on the right-hand side goes to zero because of . So we get
.")
It is also possible to analyze
![E_{ij} = \mathbb E_{Q} [ \epsilon_i(t) \epsilon_j(t) ]](https://s0.wp.com/latex.php?latex=E_%7Bij%7D+%3D+%5Cmathbb+E_%7BQ%7D+%5B+%5Cepsilon_i%28t%29+%5Cepsilon_j%28t%29+%5D+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

(again using ) which is solved by
^{-1}\, .")
This is actually the same convergence as expected by MLE estimates.
Literature
This is based on reading Opper and Winther:
Opper, Manfred, and Ole Winther. “A Bayesian approach to on-line learning.” On-line learning in neural networks (1998): 363-378.
