We consider the following formulation of Lai, Robbins and Wei (1979), and Lai and Wei (1982). Consider the following regression problem,

for 
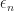

Typically for a regression problem, it is assumed that inputs 



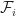

We let 
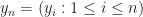

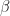
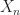

The following result gives a condition on the eigenvalues of the design matrix 
If 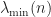

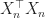
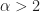
![\mathbb E [ \epsilon_n^{\alpha} | \mathcal F_{n-1} ] < \infty](https://s0.wp.com/latex.php?latex=%5Cmathbb+E+%5B+%5Cepsilon_n%5E%7B%5Calpha%7D+%7C+%5Cmathcal+F_%7Bn-1%7D+%5D+%3C+%5Cinfty+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 \xrightarrow[n\rightarrow \infty ]{} \infty \quad \text{and} \quad \frac{\log ( \lambda_{\max}(n) ) }{\lambda_{\min} (n) } \xrightarrow[n\rightarrow \infty ]{} 0")
then
 ) }{ \lambda_{\min}(n) } \right\}^{\frac{1}{2}} \right)\, .")
In what follows, 



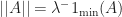
Outline of proof. The least squares estimate to the above regression problem is given by
^{-1} X^{\top}_n y_n \quad \text{and} \quad \beta := ( X^\top_n X_n)^{-1} X^{\top}_n ( y_n - \epsilon_n)\, .")
So 
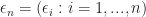
^{-1} \sum_{i=1}^n x_i \epsilon_i \Big|\Big|^2 \\ & \leq || (X^\top_n X_n)^{-1/2}||^2 \Big|\Big| (X^\top_n X_n)^{-1/2} \sum_{i=1}^n x_i \epsilon_i \Big|\Big|^2 \\ & = \lambda_{\min}(n)^{-1} \times \underbrace{ \epsilon_n^\top X_n (X^\top_n X_n) X_n^\top \epsilon_n }_{ =: Q_n }\end{aligned}")
The inequality above we apply the Cauchey-Schwartz inequality. We bound 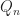
 + \sum_{k=0}^N \epsilon_n^2 x_n^\top V_n x_n")
where 

convergence is determine by the rate of convergence of the sequence

which, with some linear algebra, can be bounded by 
)}{\lambda_{\min}(n)} \Bigg)\, .")
In what follows we must study the asumptotic behaviour of
Proposition. Almost surely
)")
Proof. To prove this proposition we will require some lemmas, such as the Sherman-Morris formula. These are stated and proven after the proof of this result.
The Sherman-Morrison Formula states that:
^{-1} = A^{-1} - \frac{A^{-1} u v^\top A^{-1} }{1 + v^\top A^{-1} u }\, .")
Note that
^{-1} = ( X_{n-1}^\top X_{n-1} + x_n x_n^\top )^{-1} = V_{n-1} - \frac{ V_{n-1} x_n x^\top_n V_{n-1} }{ 1+ x_n^\top V_{n-1} x_n }\, .") Thus
Thus
 X^\top_n \epsilon_{n-1} \\ & + 2 \epsilon_{n} x^\top_n \Big( V_{n-1} - \frac{ V_{n-1} x_n x^\top_n V_{n-1} }{ 1+ x_n^\top V_{n-1} x_n } \Big) X^\top_n \epsilon_{n-1} \\ & + \epsilon_{n}^2 x_n^\top V_n x_n \\ = & Q_{n-1} - \frac{ ( x^\top_n V_{n-1} X^\top_n \epsilon_{n-1} )^2 }{ 1+ x_n^\top V_{n-1} x_n } \\ & + 2 \epsilon_{n}^\top x_n V_{n-1} X^\top_n \epsilon_{n-1} \Big( \frac{1}{1+ x_n^\top V_{n-1} x_n} \Big) \\ & + \epsilon_{n}^2 x^\top_n V_n x_n\end{aligned}")
Thus summing and rearranging a little
^2 }{ 1+ x_n^\top V_{n-1} x_n } }_{ =: a_N } \\ & = 2 \sum_{n=p+1}^N x_n V_{n-1} X^\top_n \epsilon_{n-1} \Big( \frac{1}{1+ x_n^\top V_{n-1} x_n} \Big) \epsilon_{n} + { \sum_{n=p+1}^N \epsilon_{n}^2 x^\top_n V_n x_n }\end{aligned}")
Notice in the above, the first summation (before the equals sign) only acts to decrease 
Now because the above Martingale difference sequence is a martingale we have that
 \epsilon_{n} & = o\left( \sum_{n=p+1}^N \frac{(x_n V_{n-1} X^\top_n \epsilon_{n-1})^2}{(1+ x_n^\top V_{n-1} x_n)^2} \right) + \mathcal O(1) \\ & = o(a_N) + \mathcal O(1) \end{aligned}")
In the second equality above, we use that 
 +\mathcal O (1) + \sum_{n=p+1}^N \epsilon_{n}^2 x^\top_n V_n x_n \, .")
By Lemma 2 (below) we have that
)")
Thus we have that
 )")

Lemma 1 [Sherman-Morrison Formula] For an invertible Matrix 
^{-1} = A^{-1} - \frac{A^{-1} u v^\top A^{-1} }{1 + v^\top A^{-1} u } \tag{Sherman-Morrison}")
Proof. Recalling that the outer-product of two vectors 
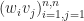
 ( w v^{\top} ) = (w^\top v) (w v^\top )")
(Nb. This is matrix multiplication: each column is a constant times 
Using this identity note that
 \bigg( 1 + w v^\top \bigg) & = I + wv^\top - \frac{wv^\top }{1+v^\top w} + \frac{1}{1+v^\top w} (wv^\top) ( wv^\top ) \\ & = I + wv^\top - \frac{wv^\top}{1+ v^\top w} \left[ 1 + w^\top v\right] \\ & = I\, . \end{aligned}") So
So 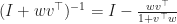
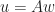
^{-1} = (I + wv^\top )^{-1} A^{-1} = \Big( I - \frac{wv^\top }{ 1 + v^\top w} \Big) A^{-1} = A^{-1} + \frac{ A^{-1} u v^\top A^{-1} }{ 1 + v^\top A^{-1} u }\, .")
as required.

The following in some sense repeatedly analyses to the determinant under the Sherman-Morrison formula.
Lemma 2. If 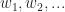
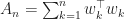
)\,.")
Proof. First note that if 
")
Thus

which should remind you of the derivative of the logarithm. (Also note that this tells us that determinant is increasing and that 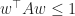

Since 

)\, .")
References
This is based on reading:
T.L Lai, Herbert Robbins, C.Z Wei, “Strong consistency of least squares estimates in multiple regression II”, Journal of Multivariate Analysis, Volume 9, Issue 3, 1979, Pages 343-361.
Lai, Tze Leung; Wei, Ching Zong. Least Squares Estimates in Stochastic Regression Models with Applications to Identification and Control of Dynamic Systems. Ann. Statist. 10 (1982), no. 1, 154–166. doi:10.1214/aos/1176345697.
