The Cross Entropy Method (CEM) is a generic optimization technique. It is a zero-th order method, i.e. you don’t gradients.1 So, for instance, it works well on combinatorial optimization problems, as well as reinforcement learning.
The Basic Idea. You want to maximize a function 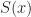

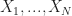
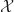
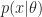
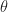

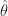
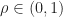
- Sample
and evaluate
.
- Order the sample
so
.
- Fit
samples,
and set
.
The above three steps are repeated until convergence. The fit step of the cross entropy method uses a specific optimization to find 
The update for
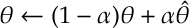
for some ![\alpha \in (0,1]](https://s0.wp.com/latex.php?latex=%5Calpha+%5Cin+%280%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The Cross Entropy Method is a heuristic algorithm. There is some very limited results on its convergence. That said empirically it has enjoyed a lot a success and is well worth considering as a straight-forward method for a variety optimization problems.
Cross Entropy and Maximum Likelihood Estimation
The CEM recommends the update, 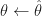

If a closed form solutions cannot be found with numerical techniques, then methods, such as Newton methods or stochastic gradient descent, “could” be used. However, in RL, often this is the point where people start to use other gradient based methods directly on the MDP objective (e.g. TD, Q-learning or actor-critic algorithms) rather than expend computation on a secondary MLE parameter optimization. CEM is meant to be a quick easy to implement method to get things working before going the whole-hog into some more complex method [e.g. Deep RL].
Def [Relative Entropy and Entropy] For two probability distributions 
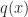



Here 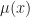
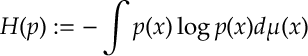
Relative entropy is a very common measure for the distance between two distributions. It arrises in Sanov’s Theorem. The relative entropy is positive; is convex in 


Def [Cross Entropy] For two probability distributions

Here
Cross Entropy and MLEs. Notice if ![p(x) =\frac{1}{M} \sum_{i=1}^M \mathbb I [X^{(i)}=x]](https://s0.wp.com/latex.php?latex=p%28x%29+%3D%5Cfrac%7B1%7D%7BM%7D+%5Csum_%7Bi%3D1%7D%5EM+%5Cmathbb+I+%5BX%5E%7B%28i%29%7D%3Dx%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
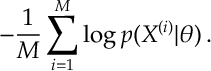
When we apply the Cross Entropy Method, we set
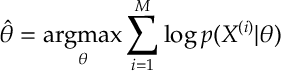
Notice here we minimize the cross entropy . Notice here we have maximized the log-likelihood function of our data. So we could interpret this as finding the maximum likelihood estimator (MLE) of our the data 
Catagorial. Let 



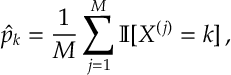
Multivariate Gaussian. If 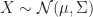

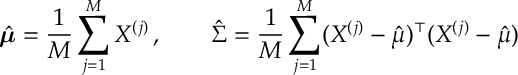
These are the two most important examples, as they deal with continuous and discrete data. We leave the proof of these examples as an exercise. However, we can go maximize MLEs for more general distributions.
Cross Entropy, MLEs and Exponential Families. We cover exponential families in more detail in this post. However, the main points are that
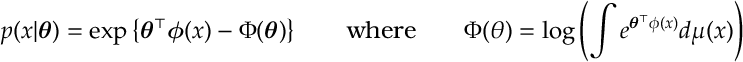
for natural parameters 

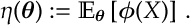 We let
We let 

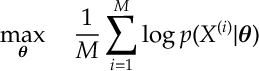
by calculating

- Caveat: though you may [or may not] need gradient methods in the sub-routine that maximizes the cross entropy.↩
- Note the one could instead [and indeed people do] use other alternatives to the cross entropy.↩
- Think of
and differentiating. See Section [ExpFamilies].↩
