A linear program is a constrained optimization problem with a linear objective, 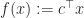
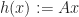
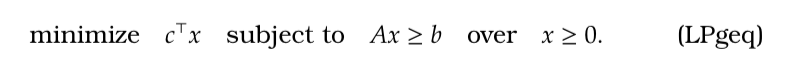
- Here
is a vector,
is an
matrix with row vectors
and, as before,
and
and
.
- A linear program could have some equality constraints
or could optimize some variables over
over
. Even so, with the addition of extra variables, constraints and suitable choice of
,
, the above optimization can express any linear program.
- There are various ways to interpret . To start with, we could interpret
as the running cost of
different machines types. The vector
could represent the required rate of production of
different goods. If a matching
makes good
at rate
, the
component of
must be met and the optimization asks to minimize the cost of production subject to the production constraints.
- Because our objective and constraints are convex, we can apply the Lagrangian approach.
Lemma 1. The dual of is the optimization

Proof. Including slack variables 

 & = \min_{x\geq 0, z\geq 0} y^\top b +y^\top z+ (c^\top-y^\top A)x \\ & = \begin{cases} y^\top b & \text{if } c^\top \geq y^\top A\text{ and } y\geq 0\\ -\infty & \text{otherwise}. \end{cases} \end{aligned}")
So by maximizing, the dual of is as required: 

Lemma 2. If 
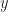

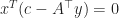
Proof. By Weak Duality, for all primal feasible 


The set 
- An extreme point point of a convex polytope
(or indeed any convex set) is a point
such that if
for some
then
.
- For a polytope we think of an extreme point as a point on the corner of the shape.
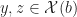
Theorem 1. Any linear program with a finite optimum has at least one optimum at an extreme point.
So, we just need to check extreme points to find an optimum. Let’s consider the optimization
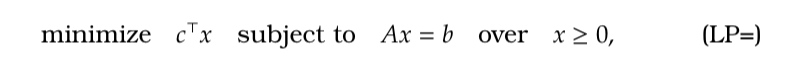 which, as we know, can be made equivalent to .
which, as we know, can be made equivalent to .
Consider 







where here elements are understood to be ordered relative to 


Henceforth, we make the following assumptions on the matrix
Assumption 1. The rows of
Assumption 2. Every basic solution 
Assumption 3. Every
- Assumption 1 removes redundant constraints from optimization .
- Assumption 3 implies that the rows of basis
.
- Assumptions 2 and 3 can be made to hold by an infinitesimally small perturbation of the entries of
- Assumptions 2 and 3 imply that each basis
.
The extreme points for the feasible set of 
Theorem 2. The extreme points of 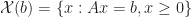
- Finding a extreme point is now characterized and computable, namely, we find
where
.
Theorem 3. [Simplex Theorem] Given Assumptions 1–3, for , a basic feasible solution

Moreover, if 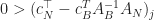

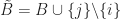

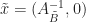

- This theorem gives both a method to verify optimality of a bfs and a mechanism to move to a better bfs from a non-optimal bfs. As we will discuss, this method is called the Simplex Algorithm.
- For a maximization, the inequality in is reversed.
- Since
, optimality condition can be expressed as

- The vector
, defined above, is called the reduced cost vector and its entries are reduced costs.
- We can interpret
as variables of the dual of . So once
, we have a dual feasible solution
and a primal feasible solution
. Thus, by essentially the same argument we used in Lemma [LP:primaldualcomp], both
Proof of the Simplex Theorem. Let’s compare bfs 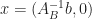
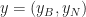

 So
So
 + c_N^\top y_N \:\: \\ & \iff \:\: 0\leq (c_N^\top - c^\top_B A_B^{-1}A_N )y_N. \end{aligned}")
Thus, if holds then the bfs 


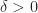


 \\ \implies & 0 \leq (c_N^\top - c^\top_BA_B^{-1}A_N )y_N,\quad \forall y_N\geq 0\:\; s.t. \;\; |y_N|\leq \delta \\ \implies & 0\leq c_N^\top -c^\top_BA_B^{-1}A_N. \end{aligned}")
This verifies that is necessary and sufficient for optimality.
Now suppose that bfs 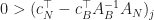



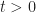
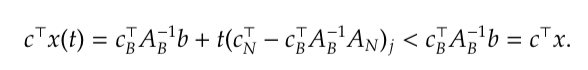
So the larger 



_i}{(A_B^{-1}A_N)_{ij}} : (A_B^{-1}A_N)_{ij}>0\bigg\}")
Observe, if no such 
- When

Thanks! Could you give me a good link that introduces this business of this ‘dual’ concept in optimization? I often see it but I don’t understand how it comes about or what it is.
LikeLike
Hi Naren,
I’ve updated the post on Lagrangian Optimization. If you read everything up to Theorem 2 on that post. You should have everything you need.
LikeLike
Thank you!
LikeLike