- Continuous-time dynamic programs
- The HJB equation; a heuristic derivation; and proof of optimality.
Category: Control
Algorithms for MDPs
- High level idea: Policy Improvement and Policy Evaluation.
- Value Iteration; Policy Iteration.
- Temporal Differences; Q-factors.
Infinite Time Horizon, MDP
- Positive Programming, Negative Programming & Discounted Programming.
- Optimality Conditions.
Markov Decision Processes
- Markov Decisions Problems; Bellman’s Equation; Two examples
Dynamic Programming
Lyapunov functions
Lyapunov functions are an extremely convenient device for proving that a dynamical system converges.
Blackwell Approachability
Sequentially a player decides to play 




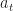

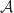
Weighted Majority Algorithm
The Weighted Majority Algorithm is a randomized rule used to learn the best action amongst a fixed reference set.
Diffusion Control Problems
- The Hamilton-Jacobi-Bellman Equation.
- Heuristic derivation of the HJB equation.
Continuous Time Dynamic Programs
- Continuous-time dynamic programs
- The HJB equation; a heuristic derivation; and proof of optimality.
