For a Markov chain  , consider the reward function
, consider the reward function
 := \mathbb E_{x} \left[ \sum_{t=0}^\infty r(\hat x_t) \right]")
associated with rewards given by 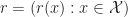 . We approximate the reward function
. We approximate the reward function  with a linear approximation,
with a linear approximation,
 = \bm w^\top \bm \phi (x) = \sum_{j\in \mathcal J} w_j \phi_j(x) .")
Here we have taken our state  and extracted features,
and extracted features, 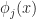 for
for 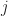 in finite set
in finite set 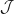 , that we believe to be important to determining the overall reward function . We then apply a vector of weights
, that we believe to be important to determining the overall reward function . We then apply a vector of weights  to each of these features. Our job is to find weights that give a good approximation to .
to each of these features. Our job is to find weights that give a good approximation to .
We know for instance that is a solution to the fixed point equation
 = \mathbb E_x [ \underbrace{ r(x) + \beta R(\hat{x}) }_{ =:\text{Target}(x) }],\qquad x\in \mathcal X. \label{TD:REqn}")
The target, 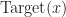 , is an estimate of the true value of
, is an estimate of the true value of  Here the target random variable considered is the TD(0) target. Other targets can be used, e.g. the term in the sum, , would be the Monte-carlo target, and there are various options in between, c.f. TD(
Here the target random variable considered is the TD(0) target. Other targets can be used, e.g. the term in the sum, , would be the Monte-carlo target, and there are various options in between, c.f. TD(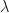 ). In function approximation, we cannot get the expected reward to equal its target. So we attempt to minimize the objective
). In function approximation, we cannot get the expected reward to equal its target. So we attempt to minimize the objective
 - R(x;\bm w) \right)^2 \right]\, .")
Here the expectation is over  , the stationary distribution of our Markov process. We can’t minimize this since we do not know the stationary distribution
, the stationary distribution of our Markov process. We can’t minimize this since we do not know the stationary distribution  . We can only get samples and so we can instead apply Robbin’s-Munro/Stochastic Gradient Descent update to
. We can only get samples and so we can instead apply Robbin’s-Munro/Stochastic Gradient Descent update to 
 - R(x; \bm w) \big) \nabla_{\bm w} R(x;\bm w)\, .")
Like with tabular methods these updates can be applied online, offline, first-visit, every-visit.
Quick Analysis of TD(0).
Let’s do an informal analysis of TD(0). For TD(0) our target is  , where
, where 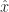 is the next state after . Under a linear function approximation this gives an update
is the next state after . Under a linear function approximation this gives an update
 + \beta \bm w^\top \bm \phi (\hat x) - \bm w^\top \bm \phi(x) \big) \bm \phi (x) \, .")
Suppose that our Markov chain for 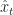 is stationary with stationary distribution
is stationary with stationary distribution 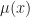 . If we look at the expected change in our update term we get
. If we look at the expected change in our update term we get
 r(x) \bm\phi(x) + \sum _x \sum_y \mu(x) ( \beta \bm \phi(x) P_{xy} \bm \phi(y)^\top -\bm \phi(x) \bm \phi(x)^\top )\bm w \\ = & \underbrace{\Phi^\top M \bm r }_{=: \bm b} - \underbrace{ \Phi^\top M [I-\beta P] \Phi }_{=: A}\bm w\, .\end{aligned}")
Above 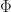 is the
is the  matrix with entries
matrix with entries  and
and  is the
is the  diagonal matrix with diagonal entries given by . We use these to define the length vector
diagonal matrix with diagonal entries given by . We use these to define the length vector 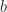 and the
and the 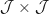 matrix
matrix  , as defined above.
, as defined above.
So, roughly, moves according to the differential equation

Now 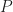 is the transition matrix of a Markov chain. Since its rows sum to
is the transition matrix of a Markov chain. Since its rows sum to  , its biggest eigenvalue is . So we can expect that
, its biggest eigenvalue is . So we can expect that 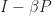 is in some sense “negative”, specifically it can be shown that
is in some sense “negative”, specifically it can be shown that  , where
, where 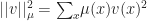 . This then implies that
. This then implies that
 || \bm v||_\mu^2.")
This is sufficient to give convergence of the above differential equation: take  such that
such that  and take
and take  then
then
 \cdot \frac{d \bm w}{dt} = - (\bm w-\bm w^*)^\top A (\bm w-\bm w^*) \leq -(1-\beta) || \bm w-\bm w^*||_\mu^2.")
Thus we see that  .
.
Convergence is great and everything, but we must verify that the solution obtained, , is a “good” solution. First, notice that the reward function  satisfies
satisfies
,\qquad \text{where}\qquad T_0(\bm R) := \bm r +\beta P \bm R\, .")
This is just with  interpreted as a vector and the expectation as a matrix operation with respect to transition matrix .
interpreted as a vector and the expectation as a matrix operation with respect to transition matrix .
Second, notice the approximation 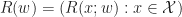 that is closest to the rewards , is given by a projection, specifically
that is closest to the rewards , is given by a projection, specifically
 := \Phi ( \Phi^\top M \Phi )^{-1} \Phi^\top M \bm R\, = \argmin_{\bm R(\bm w)} || \bm R - \bm R(\bm w) ||_\mu^2\, .")
Third, we see the equations satisfied by can be expressed in a form somewhat similar to above expression 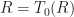 . Specifically, we rearrange the expression
. Specifically, we rearrange the expression 
 } = \underbrace{ \Phi [\Phi^\top M \Phi ]^{-1} {\Phi^\top M } }_{ \Pi } \underbrace{ (\bm r + \beta P \Phi \bm w^*) }_{ T_0(\bm R^*(\bm w)) }\, .\end{aligned}")
So, while satisfies  , we see that
, we see that  satisfies
satisfies
 = \Pi( T_0(\bm R(\bm w^*))\, .")
We can use these identities satisfied by and  to show that approximation is comparable to the best approximation of . Since
to show that approximation is comparable to the best approximation of . Since 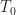 is a
is a 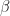 -contraction and that projections always move distances closer (both properties are relatively easy to verify):
-contraction and that projections always move distances closer (both properties are relatively easy to verify):
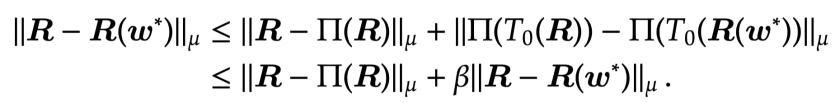
So
 ||_\mu \leq \frac{1}{1-\beta} || \bm R - \Pi( \bm R ) ||_\mu\, .")
Thus we see we reach an approximation that is a constant away from the “best” linear approximation.
References.
The exposition here is due to Van Roy and Tsitsiklis.
Tsitsiklis, John N., and Benjamin Van Roy. “Analysis of temporal-diffference learning with function approximation.” Advances in neural information processing systems. 1997.
