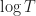Next semester, I will teach a short course on Probability for university students who have not taken probability before, who know some basic mathematics, but who are not necessarily going to be studying mathematic.
The notes for this are here:
Next semester, I will teach a short course on Probability for university students who have not taken probability before, who know some basic mathematics, but who are not necessarily going to be studying mathematic.
The notes for this are here:
Sequential Monte-Carlo is a general method of sampling from a sequence of probability distributions 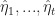
Multi-Level Monte-Carlo is an Monte-carlo method for calculating numerically accurate estimates when fine grained estimates are expensive, but cheap coarse-grained estimates can be used to supplement this. We considered the simulation of stochastic differential equations, which is the application first proposed, but we note that the approach applies in a variety of other settings.
Continue reading “Multi-Level Monte Carlo (MLMC)”Markov chain Monte Carlo is a variant of the Monte Carlo, where samples are no longer independent but instead are sampled from a Markov chain. This can be useful in Bayesian statistics, or when we sequentially adjust a small number of parameters for a more complex combined distribution.
We cover MCMC, its use in Bayesian statistics, Metropolis-Hastings, Gibbs Sampling, and Simulated Annealing.
Continue reading “Markov Chain Monte Carlo (MCMC)”Due to some projects, I’ve decided to start a set of posts on Monte-Carlo and its variants. These include Monte-Carlo (MC), Markov chain Monte-Carlo (MCMC), Sequential Monte-Carlo (SMC) and Multi-Level Monte-Carlo (MLMC). I’ll probably expand these posts further at a later point.
Here we cover “vanilla” Monte-Carlo, importance sampling and self-normalized importance sampling:
Continue reading “Monte-Carlo (MC)”Here are slides from this year’s stochastic control course:
The Neural Tangent Kernel is a way of understanding the training performance of Neural Networks by relating them to Kernel methods. Here we overview the results of the paper [Jacot et al. here]. The paper considers a deep neural network with a fixed amount of data and a fixed depth. The weights applied to neurons are initially independent and normally distributed. We take a limit where the width of each layer tends to infinity.
I’ve updated the notes for this year’s stochastic control course, here:
Asside from general tidying. New material includes:
Like last year, I will likely update the notes further (and correct typos) towards the end of the course.
We consider the problem where there is an amount of stock 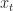

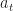


We continue the earlier post on finite-arm stochastic multi-arm bandits. The results so far have suggest that, for independent identically distributed arms, the correct size of the regret is of the order