Due to some projects, I’ve decided to start a set of posts on Monte-Carlo and its variants. These include Monte-Carlo (MC), Markov chain Monte-Carlo (MCMC), Sequential Monte-Carlo (SMC) and Multi-Level Monte-Carlo (MLMC). I’ll probably expand these posts further at a later point.
Here we cover “vanilla” Monte-Carlo, importance sampling and self-normalized importance sampling:
The idea of Monte-Carlo simulation is quite simple. You want to evaluate the expectation of 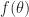
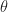


] = \int f(\theta) d \mu(\theta)\,.\end{aligned}")
So we can think of Monte-carlo as evaluating an integral.
Given you can sample 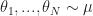
![\mathbb{E} [f(\theta)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D+%5Bf%28%5Ctheta%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 \right] := \frac{1}{N} \sum_{i=1}^N f(\theta_i) \, .\end{aligned}")
In particular, if the samples are i.i.d. the strong law of large numbers gives that, with probability 
 \xrightarrow[N\rightarrow \infty]{} \mathbb E_{\theta \sim \mu} [ f(\theta)] \, .\end{aligned}")
Also it holds that
] - \mathbb E_{\theta \sim \mu} [f(\theta)]
\right)^2
\right]^{\frac{1}{2}}
\leq
\frac{
\mathbb V(f(\theta))^{\frac{1}{2}}
}{
\sqrt{N}
}\end{aligned}")
(since the variance satisfies 

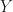
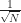
A Classical Example. Let 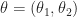
![\theta_1, \theta_2 \sim U[0,1]](https://s0.wp.com/latex.php?latex=%5Ctheta_1%2C+%5Ctheta_2+%5Csim+U%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 = \mathbb I [ \theta_1^2 + \theta_2^2 \leq 1]\end{aligned}") Note that the area of the quarter circle
Note that the area of the quarter circle ![\{\theta \in [0,1]^2 : \theta_1^2 + \theta_2^2 \leq 1 \}](https://s0.wp.com/latex.php?latex=%5C%7B%5Ctheta+%5Cin+%5B0%2C1%5D%5E2+%3A+%5Ctheta_1%5E2+%2B+%5Ctheta_2%5E2+%5Cleq+1+%5C%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
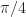

The rate of convergence in this example is pretty atrocious when compared with numerical methods. 1 However the example gets the main idea across: there is some difficult to calculate quantity (namely 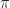
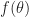
Importance Sampling.
If we want to calculate
\end{aligned}")
we don’t need to sample from 
 d \mu (\theta)
\notag
\\
& = \int f(\theta) \frac{d \mu}{d \nu} (\theta) d\nu (\theta)
\notag
\\
&= \mathbb E_{\theta\sim \nu} [\tilde Z]
\label{MC:EZ}\end{aligned}")
where
 \frac{d \mu}{d \nu}(\theta)\end{aligned}")
(Above 
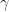
Thus when applying important sampling, we sample 
 \frac{d \mu}{d \nu}(\theta_i)\end{aligned}")
The following lemma, although not entirely practical, gives good insights as to why importance sampling can help
Lemma [the Perfect Importance Sampler] If 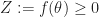

then the estimator 
 = 0\end{aligned}")
Proof.

where the last inequality follows by . Therefore 

The above suggest that we should choose 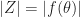
Self-Normalized Importance Sampling.
In importance sampling, we apply a weight 
![\mathbb E_{\theta \sim \nu} [ w(\theta)]=1](https://s0.wp.com/latex.php?latex=%5Cmathbb+E_%7B%5Ctheta+%5Csim+%5Cnu%7D+%5B+w%28%5Ctheta%29%5D%3D1&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 ]
\approx \hat{\mathbb E}[f(\theta) ] = \frac{\sum_{i=1}^N f(\theta_i ) w(\theta_i) }{\sum_{i=1}^N w(\theta_i) } \, .\end{aligned}")
So long as the weights remain bounded, the rate of convergence is comparable to that of MCMC.
Proposition. If the weights 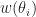
 ] - \mathbb E_\mu [ f(\theta)]||_{L_2}
\leq
2 \frac{f_{\max} w_{\max}}{\sqrt{N}}\, .\end{aligned}")
Proof. Note that for
![\bar w (\theta_i) := w(\theta_i) / \mathbb E[w(\theta_i)]](https://s0.wp.com/latex.php?latex=%5Cbar+w+%28%5Ctheta_i%29+%3A%3D+w%28%5Ctheta_i%29+%2F+%5Cmathbb+E%5Bw%28%5Ctheta_i%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 w(\theta_i) }{\sum_{i=1}^N w(\theta_i) } - \frac{\sum_{i=1}^N f(\theta_i ) \bar w(\theta_i) }{ N }
=
\left[ \frac{\sum_{i=1}^N f(\theta_i ) \bar w(\theta_i) }{\sum_{i=1}^N \bar w(\theta_i) } \right]
\left\{
1 - \frac{\sum_i \bar w(\theta_i)}{N}
\right\}\end{aligned}")
Note that the term in square brackets is bounded by 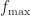
 ] - \mathbb E_\mu [ f(\theta)]||_{L_2}
\notag
\\
\leq &
f_{\max}
\left\|
1 - \frac{\sum_i \bar w(\theta_i)}{N}
\right\|_{L_2}
+
\left\|
\frac{\sum_i \bar w(\theta_i) f(\theta_i)}{N}
-
\mathbb E [f(\theta) ]
\right\|_{L_2}
\label{MCMC:Ieq}\end{aligned}")
Now notice that, since ![\mathbb E_\nu [ \bar w(\theta)f(\theta) ] = \mathbb E_\mu[f(\theta)]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E_%5Cnu+%5B+%5Cbar+w%28%5Ctheta%29f%28%5Ctheta%29+%5D+%3D+%5Cmathbb+E_%5Cmu%5Bf%28%5Ctheta%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 f(\theta_i)}{N}
-
\mathbb E [f(\theta) ]
\right\|_{L_2}
= \sqrt{ \frac{\mathbb V_{\nu}(\bar w(\theta)f(\theta))}{N} } \leq \frac{w_{\max} f_{\max} }{\sqrt{N}}\,.\end{aligned}")
The above inequality applies to both terms in (by taking 
References
Monte-Carlo is by now a very standard method. Buffon’s Needle and the calculation of
Metropolis, N. “The Beginning of the Monto-Carlo Method.” Los Alamos Science 15 (1987): 125-130.
Asmussen, Søren, and Peter W. Glynn. Stochastic simulation: algorithms and analysis. Vol. 57. Springer Science & Business Media, 2007.
Kroese, Dirk P., Thomas Taimre, and Zdravko I. Botev. Handbook of monte carlo methods. Vol. 706. John Wiley & Sons, 2013.
