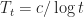Markov chain Monte Carlo is a variant of the Monte Carlo, where samples are no longer independent but instead are sampled from a Markov chain. This can be useful in Bayesian statistics, or when we sequentially adjust a small number of parameters for a more complex combined distribution.
We cover MCMC, its use in Bayesian statistics, Metropolis-Hastings, Gibbs Sampling, and Simulated Annealing.
Sometimes the underlying distribution that we wish to sample from can be complex. However, even though it may not be possible to obtain I.I.D. samples from , it may be possible to construct a Markov chain whose stationary distribution is . Again if we wish to estimate
then we can use the estimator
This procedure of estimating in this way is called Markov Chain Monte-Carlo (MCMC).
As before, under mild conditions1 the Markov chain is ergodic, meaning with probability ,
(where the above limit denotes convergence in distribution). Assuming second moments remain bounded for all , this then implies
Again errors go down like .
MCMC in Bayesian Statistics.
Perhaps the most important example where MCMC is used is time implement Bayes rule in Bayesian statistics. Recall that in Bayesian statistics we start with a prior distribution ; We receive data here is the probability of data under parameter , and we use Bayes’ rule to update to the posterior distribution
Above, we know and (because these are usually chosen in advance) but it is rare to have a closed form expression for the integral
This is where MCMC comes in. We can sample from with Markov chain Monte Carlo. This is because we can calculate the ratio
Note each term on the right hand side is assumed known. Given one easy way to sample from is with the Metropolis-Hastings Algorithm.
Metropolis-Hastings.
Metropolis Hastings is the simplest and most popular MCMC algorithm. Suppose we want to sample from a probability distribution
Here is known but the integral in is not. (Note in the Bayesian stats example above .)
The Metropolis-Hastings Markov chain is determined by the function given above and a “proposal” probability distribution for each . The state of the Markov chain at time is
Propose. Now propose a new value with probability .
Select. Set
A few remarks. 1. Note the probability above could be negative in which case the probability of staying at is set to be zero. 2. Noticed we have not really specified . This is because it is a design choice. So long as there is a non-zero chance of visiting each then the algorithm will work. 3. A choice for would be to uniformly sample from . Another choice would be to uniformly sample from the neighborhood of . In both cases it would hold that
and thus the function will not feature in the selection step.
We now verified that the Markov chain constructed is such that if is sampled with probability .
Proposition. The Metropolis-Hastings Markov chain is reversible and has a stationary distribution given by .
Proof. Recall that a Markov chain with transition matrix is reversible with stationary distribution if
for all . Notice for as given in . The probability of being in and going to is
while going from to it is
Notice that above both sides are equal to
Thus, as required, the Metropolis-Hastings sampler is reversible Markov chain with stationary distribution
Gibbs Sampler
The Gibbs sampler is a special case of Metropolis Hastings. It applies when we can sample marginal distributions. I.e. Here is a vector and we can sample from the distribution of (Here and here is the conditional distribution of given . )
When there is independence or conditional independence between a limited set of parameters (like in a Bayesian network and/or an Ising model), then it often turns our that has a simple form.
The Gibbs sampler does the following, at time in state :
Chose an index
Sample $latex
\theta’_i \sim \mu(\cdot | \theta_{-i} ) $
Set and keep all other components the same, .
We have not been too specific about how is sampled. The easiest method is to one-by-one go through each index. Also random sampling will work. (Anything works really as long as the over all policy is Markov and we sample each index a positive proportion of the time.)
Gibbs is Metropolis-Hastings.
It is worth noting that Gibbs sampling is really just a special case of the Metropolis-Hastings algorithm.
To see this, notice that if is our target distribution and is our proposal distribution then assuming index is chosen for transferring between and and then the Metropolis Hastings condition is such that
Thus we see that the Metropolis-Hastings rule with this choice of and is exactly the Gibbs sampler.
Simulated Annealing
Simulated Annealing is a further variant of Metropolis Hastings. It acts as a first order optimization algorithm. (Similar to the Cross-Entropy method it is somewhat heuristic.) Here we suppose that we want to solve an optimization problem
The following probability distribution, which is parameterized by , concentrates on the solution of the above optimization
Here is the set of solutions to the above optimization. The above distribution is often interpreted in terms of physics applications, specifically, is know as Boltzmann’s distribution, is the energy associated with state and is the temperature of that state.
We can easily simulated the distribution with Metropolis-Hastings. To do this, we slowly decrease and then the solution should concentrate on the set of optimal parameters. Specifically, given the current state and the temperature , we do the following
We can then let while running our chain. We will never exactly sample from the distribution but given decreases sufficiently slowly then we should get an close approximation. There are conditions that guarentee convergence to optimality, specifically that . However, these rates are considered to be too slow for practical use and so in practice much quick rates of convergence to zero are used. For this reason, despite some supporting theory, the algorithm remains somewhat of a heuristic.
References
Again the text of Kroese et al. and Assmussen and Glynn provide good text book accounts. Also the Markov chains book of Bremaud. The convergence of simulated annealing is given by Hajek.
Kroese, Dirk P., Thomas Taimre, and Zdravko I. Botev. Handbook of monte carlo methods. Vol. 706. John Wiley & Sons, 2013.
Asmussen, Søren, and Peter W. Glynn. Stochastic simulation: algorithms and analysis. Vol. 57. Springer Science & Business Media, 2007.
Brémaud, Pierre. Markov chains: Gibbs fields, Monte Carlo simulation, and queues. Vol. 31. Springer Science & Business Media, 2013.
Hajek, Bruce. “Cooling schedules for optimal annealing.” Mathematics of operations research 13.2 (1988): 311-329.
Being fully formal here, we need some extra property that the Markov chain is irreducible.↩

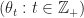
] , \end{aligned}")
]
=
\frac{1}{N}
\sum_{i=1}^N f(\theta_i) \, .\end{aligned}")

]
:=
\frac{1}{N}
\sum_{i=1}^N f(\theta_i)
\xrightarrow[N\rightarrow\infty]{ } \mathbb E_{\theta \sim \mu} [ f(\theta)]\,.\end{aligned}")
 \right]
-
{ \mathbb E}_\mu \left[ f(\theta) \right]
\right\}
\xrightarrow[N\rightarrow \infty ]{\mathcal D} \mathcal N (0,\sigma^2) \end{aligned}")

]
-
\mathbb E_{\mu} [f(\theta)]
\right)^2
\right]^{\frac{1}{2}}
\sim
\frac{\sigma^2}{\sqrt{N}}\, .\end{aligned}")
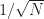

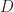

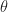

=
\frac{
p(D|\theta) p(\theta)
}{
\int p(D|\phi) p(\phi) d\phi
}\, .\end{aligned}")
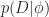

 p(\phi) d \phi \, .\end{aligned}")

}{p(\phi| D)}
=
\frac{
p(D|\theta) p(\theta)
}{
p(D|\phi) p(\phi)
} \, .\end{aligned}")

 =
\frac{
c(\theta)
}{
\int c(\phi) d \phi
}\, .\end{aligned}")




with probability
.
 q(\theta' | \theta_t)
}{
c(\theta_t) q(\theta_t | \theta')
} ,
\\
\theta' & \text{otherwise.}
\end{cases}\end{aligned}")

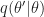
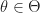
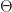
 = q(\theta' | \theta) \end{aligned}")




 P(\phi | \theta) = \mu (\theta) P(\theta | \phi) \end{aligned}")
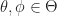


q(\theta' | \theta) \left(
1 \wedge \frac{c(\theta')q(\theta'|\theta)}{c(\theta) q(\theta|\theta')}
\right)\end{aligned}")

q(\theta | \theta') \left(
1 \wedge \frac{c(\theta)q(\theta|\theta')}{c(\theta') q(\theta'|\theta)}
\right)\end{aligned}")

 q(\theta | \theta' ) \wedge c(\theta') q(\theta' | \theta)\end{aligned}")
 =
\frac{
c(\theta)
}{
\int c(\phi) d \phi
}\, .\end{aligned}")


\end{aligned}") (Here
(Here 
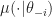

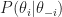

 = \theta'_i\end{aligned}") and keep all other components the same,
and keep all other components the same, .



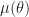


 q(\theta'| \theta) }{c(\theta') q(\theta| \theta')}
& =
\frac{\mu(\theta) \mu (\theta_i'| \theta_{-i})}{\mu(\theta') \mu (\theta_i| \theta'_{-i})}
\\
& =
\frac{\mu(\theta) \mu (\theta_i'| \theta_{-i})}{\mu(\theta') \mu (\theta_i| \theta_{-i})}
\\
& =
\frac{\mu(\theta) \mu (\theta_i')}{\mu(\theta') \mu (\theta_i)}
=1\end{aligned}")
 \end{aligned}")

 =
\frac{e^{-E(\theta)/T}}{\sum_{\phi\in\Theta} e^{-E(\phi)/T}}
\xrightarrow[T\rightarrow 0 ]{}
\frac{\mathbb I [ \theta \in \Theta^\star]}{|\Theta^\star|}\, .\end{aligned}")


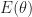


in some neighbourhood of