Multi-Level Monte-Carlo is an Monte-carlo method for calculating numerically accurate estimates when fine grained estimates are expensive, but cheap coarse-grained estimates can be used to supplement this. We considered the simulation of stochastic differential equations, which is the application first proposed, but we note that the approach applies in a variety of other settings.
Aim. Suppose 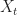
 dt + \sigma(X_t) dB_t \end{aligned}")
and the aim is to estimate
")
at some time 

Monte-Carlo. In a “vanilla” Monte-Carlo approach we would estimate with
}_T) \end{aligned}")
where 




^{\frac{1}{2}} := \mathbb E [ (\tilde f_N- \bar f)^2]^{1/2} = O(\epsilon)\end{aligned}")
we need about 
Numerical and simulation error. However, the assumption here is that we can simulate 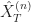
^2] =
\mathbb V(\tilde f_N)
+
(\mathbb E [\tilde f_N ]- \bar f )^2 \,.\end{aligned}")
As before the variance goes down at 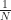

Numerical Approximation of SDEs. The simplest scheme for simulating an SDE is the Euler-Maruyama scheme: Here  h + \sigma (\hat X_{t_n}) \Delta W_{n}
\tag{Euler-Maruyama}\end{aligned}") where
where 

 h + \sigma (\hat X_{t_n}) \Delta W_{n}
+\frac{1}{2} \sigma'(\hat X_{t_n}) \sigma(\hat X_{t_n}) [ (\Delta W_{n})^2 - h ]
\tag{Milstein}\end{aligned}") Is can be shown that the error of the Euler-Maruyama scheme can be found to be
Is can be shown that the error of the Euler-Maruyama scheme can be found to be
] - \mathbb E[ f(X_T)] = O(h)
\qquad
\text{and}
\qquad
\mathbb E \Big[ \sup_{t\in [0,T]} (\hat X_t - X_t)^2 \Big]^{\frac{1}{2}}= O(h^{\frac{1}{2}})\end{aligned}")
while for Milstein’s method
] - \mathbb E[ f(X_T)] = O(h)
\qquad
\text{and}
\qquad
\mathbb E \Big[ \sup_{t\in [0,T]} (\hat X_t - X_t)^2 \Big]^{\frac{1}{2}}= O(h) \,.\end{aligned}")
Bias and Variance again. We can now see that the bias and variance from above is
^2] =
\mathbb V(\tilde f_N)
+
(\mathbb E \tilde f_N - \bar f )^2
=
O\left( \frac{1}{N} + h^2 \right)\end{aligned}")
Thus to get this error to be less than 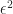
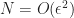
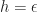

The aim of Multi-Level Monte-Carlo (MLMC) is to reduce the computational cost required to get the RMS below 
Simulating Brownian Motion at different levels. The easiest way to approximate a brownian motion is to take normal distributions 
}_t = \sum_{i: 2^{-l} i \leq t} Z^{(l)}_i \, .\end{aligned}")
Here for “level” 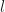

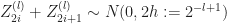
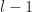
}_t = \sum_{i: 2^{-l+1} i \leq t} Z^{(l)}_{2i}+Z^{(l)}_{2i+1} \, .\end{aligned}")
We can also go the other way from course grained to fine grained, since if 

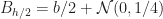
Numerical Approximation of SDEs with different levels. Now suppose that we wish to compute ![\mathbb E [f(X^{(l)}) - E f(X^{(l-1)}]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E+%5Bf%28X%5E%7B%28l%29%7D%29+-+E+f%28X%5E%7B%28l-1%29%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
}) - f(X_T^{(l-1)})]
&=
\mathbb V [ f(X_T^{(l)}) -f(X_T) - f(X_T^{(l-1)}) + f(X_T)]
\\
& \leq
\left(
\mathbb V [f(X_T^{(l)}) -f(X_T) ]^2
+
\mathbb V [ f(X_T^{(l-1)}) -f(X_T) ]^2
\right)^{\frac{1}{2}}
\\
&
=
\begin{cases}
O(h^{(l)}) & \text{Euler-Maruyama}\\
O((h^{(l)})^2) & \text{Milstein}
\end{cases}\end{aligned}")
(Here we assume that 

\end{aligned}")
Multi-Level Estimation. Notice that we can form an estimator of with
}_0}{N_0}+\sum_{l=1}^L \frac{1}{N_l} \sum_{n=1}^{N_l} \left( \hat P_l^{(n)} - \hat P^{(n)}_{l-1} \right)\end{aligned}")
where we take independent samples with 

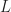

The total cost of the estimation is

The total variance of estimation is

(Here we work on the basis that there is an independent mechanism generating the samples from level
The following result calculates the optimal number of samples to perform at each level.
The cost minimization

has optimal solution
\end{aligned}")
and the optimal cost is
^2\end{aligned}")
The proof is a straight-forward convex optimization argument. It is interesting that there is a non-trival solution reached. It should be noted that without applying a multi-level approach (i.e. doing just one level) the variance of a single sample path is typically 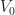
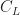

If we think of 

^2 / C_L V_0
\leq
\begin{cases}
\sqrt{L} \frac{V_0}{C_L} &\text{if } \sqrt{V_{l'}C_{l'}} \text{ is decreasing} \\
\sqrt{L} \frac{V_L}{C_0} &\text{if } \sqrt{V_{l'}C_{l'}} \text{ is increasing}
\end{cases}\end{aligned}")
In both cases we see a multiplicative reduction in cost for the same variance estimate of the SDE. This bound can be improved by splitting into cases more careful. But, since 
References.
Multi-Level Monte Carlo is first presented in a very readable paper by Giles ’08. It has since found a wealth of applications. Giles maintains and excellent summary of the area on his webpage [link].
M.B. Giles. ‘Multi-level Monte Carlo path simulation’. Operations Research, 56(3):607-617, 2008.
