We continue the earlier post on finite-arm stochastic multi-arm bandits. The results so far have suggest that, for independent identically distributed arms, the correct size of the regret is of the order . We now more formally prove this with the Lai and Robbins lower-bound .
We suppose that there are arms as described at the very beginning of this section. We let be the probability distribution of the rewards from arm . For the Lai and Robbins lower-bound, it is useful to think of as a subset of size with values from a set of parameters , i.e. , and that is the probability distribution of rewards under the parameter choice . (To be concrete, think of being the interval and being a Bernoulli distribution with parameter .)
Asymptotic Consistency. To have a reasonable lower-bound we need to assume a reasonable set of polices. For instance, we need to exclude polices that already know the reward of each arm. Lai and Robbins consider amougst policies that are asymptotically consistent, which means, for each set of arms , for all
(1)
for every . I.e. a policy is a “good” policy if it can do better than any power in playing sub-optimal arms. (Recall here is the set of optimal arms, and is the number of times we play arm by time .)
The Lower Bound. The Lai–Robbins Lower Bound is the following:
Theorem [Lai and Robbins ’85]
and thus
where here is the Relative Entropy (defined in the appendix) between the distribution of arm , and the distribution of the optimal arm, .
For independent rewards and independent rewards independent rewards , under mild conditions, there exists a function such that
(2)
and
(3)
(The term is is just the ratio between and and is formally called Radon-Nikodym derivative.) For the Lai Robbins lower-bound, we also require the assumption that
as . This is required to get the constants right in the theorem but is not critical to the overall analysis.
We now prove the Lai and Robbins Lower-bound.
Proof. We take an increasing sequence of integers . We will specify it soon but for now it is enough to assume that . We can lower-bound the expected number of times arm is played as follows:
(4)
Here we see that we want to take as large as possible while keeping the probability away from . When arm was replaced by an arm whose mean reward is the larger than each arm in (i.e. ) then we can analyze this probability:
(5)
In the inequality above we apply Markov’s Inequality and the asymptotic consistency assumption . (Note the above bound holds for every so in informal terms we could think of the above bound as being .)
We can change arm for arm through the change of measure given above in . This involves the sum of independent random variables which by and the weak law of large numbers satisfies:
Here we apply the shorthand and .
We now have various pieces in place where we can now analyze the probabilities as follows:
In the first equality (6), we split the probability according to how close is to . In the inequality (7), we remove the condition from the first term and apply the change of measure to the second term (2). The condition on and the definition of yields (8). Finally follows from the bound on given in (5).
So, we have
and recall we want the probability above to stay away from . The only term that can grow is in the exponent . So the largest we can make without this growing is by taking
This gives
which applied to the bound (4) gives
Thus
which is the required bound on . (Some technical details: Here after taking the limit we set to zero, to zero and set to . We can do this because the bound holds for all and . Also is an arbitrary parameter such that so we apply our assumption that as .)
Finally, for the regret bound we recall that
Thus applying the bound on each term gives the regret bound
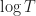




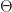
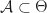
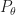
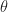
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)


\end{aligned}")

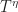

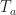


}\end{aligned}")
}{\log T}
\geq
\sum_{a\in\mathcal A}\frac{\Delta_a}{D(P_a ||P_{\star})}\, \end{aligned}")


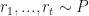
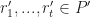

 \in C)
=
\mathbb E' \left[ e^{\sum_{s=1}^t D(r'_s)} \mathbb I [(r_1,...,r_t) \in C] \right]\end{aligned}")
 = \mathbb E [ D(r)]\, .\end{aligned}")

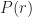
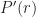
 \rightarrow D(P || P_{a})")

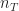

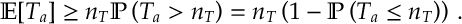





=
\mathbb P' (T-T_{a'} \geq T- n_T)
\leq
\frac{
\mathbb E[ T- T_{a'} ]
}{
T-n_T
}
=
\frac{
o(T^{\eta})}{T-n_T}
= o(T^{\eta-1})\, .\end{aligned}") (5)
(5) 
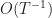
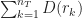
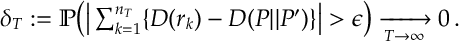



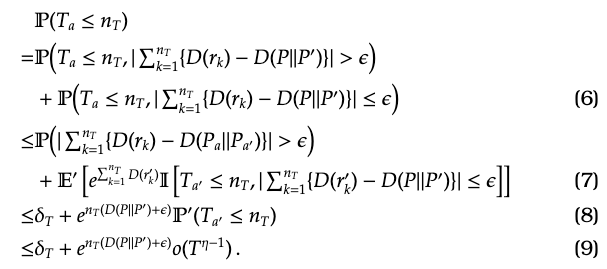

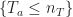

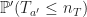

\leq \delta_T
+
e^{n_T (D(P||P')+\epsilon)}
\mathbb P'(T_{a'} \leq n_T)\end{aligned}")
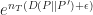
 \frac{\log (T)}{D(P||P')+\epsilon} \, .")

\leq
\delta_T
+
o(T^{-\eta})=o(1)\,.\end{aligned}")
) = (1-2\eta) \frac{\log (T)}{(D(P||P')+\epsilon)}( 1- o(1))\end{aligned}")
}\end{aligned}")
![\mathbb E[T_a]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BT_a%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
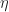




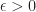


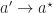
 = \sum_{a\notin\mathcal A^\star} \Delta_a \mathbb E [ T_a] \end{aligned}")
}{\log T}
\geq
\sum_{a\in\mathcal A}\frac{\Delta_a}{D(P_a ||P_{\star})}\, .\end{aligned}")


The explanation is so clear. I had a hard time understanding the original paper. Thank you so much.
LikeLike