Sequential Monte-Carlo is a general method of sampling from a sequence of probability distributions 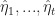
Here, we have the update equations
 & = \int P(x_t | x_{t-1} ) \hat \eta_{t-1}(dx_{t-1}) \\
\hat \eta_t(x_t) & =
\frac{W_t(x_t) \eta_t(x_t)
}{
\int W_t(x'_t) \eta_t(x'_t) dx'_t
}\end{aligned}")
Notice if we take 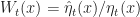
However, we can approximately sample from the required distribution and use that as a proxy. We can then update with the same equations as above replacing the continuous 


More precisely, SMC does the following:
1) Resample. For 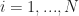
 \, .\end{aligned}")
2) Reweight.
 := \sum_{i=1}^N \frac{W_{t+1}(\hat x_{t+1}^i)}{ W^\Sigma_{t+1} } \delta_{\hat x_{t+1}^i}(x)\, ,\end{aligned}")
where
 = \frac{\hat \eta_{t+1} (\hat x_{t+1}^i)}{ \eta_t(\hat x_{t+1}^i)}
\quad\text{and}\quad W^\Sigma_{t+1} = \sum_{j=1}^N W_{t+1}(\hat x_{t+1}^j) \, .\end{aligned}")
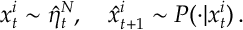
It is worth noting that the resampled RVs 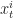
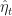
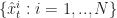


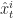
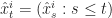
Roughly why this works. Although we can say more precisely why things work out for this algorithm, let’s sketch out why it works. Suppose that 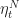
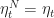

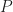
 \right]
=
\frac{\sum_{i=1}^N f({\hat x_{t+1}^i})W_{t+1}({\hat x_{t+1}^i})}{\sum_{j=1}^N W_{t+1}({\hat x_{t+1}^j})} \, .\end{aligned}")
We can apply the strong law of large numbers to each of the two sums above. Notice that
W_{t+1}({\hat x_{t+1}^i})
&
=
\int f(\hat x) W_{t+1}(\hat x) P(\hat x| x) \hat \eta_t(x) dx d\hat x
\\
&
=
\int f(\hat x) \left[ \frac{\hat \eta_{t+1} (\hat x)}{\eta_t(\hat x)} \right] P(\hat x| x) \hat \eta_t(x) dx d\hat x
\\
&
=
\int f(\hat x) \hat \eta_{t+1}(\hat x) d\hat x \, .\end{aligned}")
This holds for 
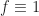
 \right]
=
\int f(\hat x) \hat \eta_{t+1}(\hat x) d\hat x \, .\end{aligned}")
Thus we see that in the limit where
Hidden Markov Models
As an example SMC can be used for Hidden Markov models. Suppose that 
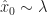
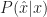

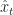
 \sim q(O_t | \hat x_t)\end{aligned}") I.e. the distribution of
I.e. the distribution of 
Like with the Kalman filter we wish to calculate
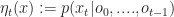
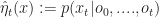

Letting 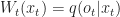


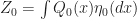
 & = \int P(x_t | x_{t-1} ) \hat \eta_{t-1}(dx_{t-1}) \\
\hat \eta_t(x_t) & =
\frac{W_t(x_t) \eta_t(x_t)
}{
\int W_t(x'_t) \eta_t(x'_t) dx'_t
}
\\
Z_t
&=
Z_{t-1}
\int W_t(x'_t) d\eta_t(x'_t) \end{aligned}")
If we are given 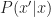

Convergence Proof.
We now prove the convergence of SMC (in 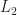
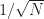

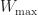
Theorem. For all bounded continuous
 d \hat \eta^N_t (x)
-
\int f(x) d \hat \eta_t (x)
\right\}^2
\right]
\leq \frac{f_{\max}^2 W_{\max}^2c_t}{N}\end{aligned}")
where 
Proof. The proof proceeds by induction applying the same bounds that we proved from standard Monte-Carlo and self-normalized importance sampling (cf. and Proposition [MC:SNI]).
Notice at time 

-
\int f(x) d \hat \eta_0(x)
\right\}^2
\right]
=
\frac{1}{N} \mathbb V(f(\hat x_0)) \leq \frac{f_{\max}^2}{N}\, .\end{aligned}")
So the result holds at
We now suppose the induction hypothesis that the result holds at time 

First notice that, similar to self-normalized importance sampling, we can replace the self-normalized sum with a non-self-normalized sum. Specifically,
 d \hat \eta^N_{t+1}(x) - \frac{1}{N} \sum_{i=1}^N W_{t+1}(\hat x_{t+1}^i) f(\hat x_{t+1}^i)
\\
=
&
\sum_{i=1}^N \frac{W_{t+1}(\hat x_{t+1}^i)}{W^\Sigma_{t+1}} f(\hat x_{t+1}^i) - \frac{1}{N} \sum_{i=1}^N W_{t+1}(\hat x_{t+1}^i) f(\hat x_{t+1}^i)
\\
=
&
\left[ \sum_{i=1}^N \frac{W_{t+1}(\hat x_{t+1}^i)}{W^\Sigma_{t+1}} f(\hat x_{t+1}^i)
\right]
\left\{
1 - \frac{1}{N}\sum_{i=1}^N W_{t+1}(\hat x_{t+1}^i)
\right\}\end{aligned}")
Note that the term in square bracket is bounded by 
![\|X \|_{L_2} := \mathbb E [X^2]^{1/2}](https://s0.wp.com/latex.php?latex=%5C%7CX+%5C%7C_%7BL_2%7D+%3A%3D+%5Cmathbb+E+%5BX%5E2%5D%5E%7B1%2F2%7D+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 d \hat \eta^N_{t+1} (x)
-
\int f(x) d \hat \eta_{t+1} (x)
\right\|_{L_2}
\notag
\\
\leq
&
\left\|
\int f(x) d \hat \eta^N_{t+1} (x)
-
\frac{1}{N} \sum_{i=1}^N f(\hat x_{t+1}^i) W_{t+1}(\hat x_{t+1}^i)
\right\|_{L_2}
\notag
\\
&
+
\left\|
\frac{1}{N} \sum_{i=1}^N f(\hat x_{t+1}^i) W_{t+1}(\hat x_{t+1}^i)
-
\int f(x) d \hat \eta_{t+1} (x)
\right\|_{L_2}
\notag
\\
\leq
&
f_{\max}
\left\|
1 - \frac{1}{N}\sum_{i=1}^N W_{t+1}(\hat x_{t+1}^i)
\right\|_{L_2}
\label{SMC:fin0}
\\
&+
\left\|
\frac{1}{N} \sum_{i=1}^N f(\hat x_{t+1}^i) W_{t+1}(\hat x_{t+1}^i)
-
\int f(\hat x) W(\hat x)P(\hat x| x) d \hat x d \hat \eta_{t} (x)
\right\|_{L_2}
\label{SMC:fin}\end{aligned}") In the final inequality above, we now that
In the final inequality above, we now that 
We analyze the term , noting that the term is the same when we take 
 W_{t+1}(\hat x) \big| \hat \eta_t^{N}\right]
= \int f(\hat x) W_{t+1}(\hat x) P(\hat x| x) \hat \eta^{N}_t(dx) \, .\end{aligned}")
Thus for we have
 W_{t+1}(\hat x_{t+1}^i)
-
\int f(\hat x) W(\hat x)P(\hat x| x) d \hat x d \hat \eta_{t} (x)
\right\|_{L_2}
\notag
\\
\leq
&
\left\|
\frac{1}{N} \sum_{i=1}^N f(\hat x_{t+1}^i) W_{t+1}(\hat x_{t+1}^i)
-
\int f(\hat x) W(\hat x)P(\hat x| x) d \hat x d \hat \eta^N_{t} (x)
\right\|_{L_2}
\notag
\\
&
+
\left\|
\int f(\hat x) W(\hat x)P(\hat x| x) d \hat x d \hat \eta^N_{t} (x)
-
\int f(\hat x) W(\hat x)P(\hat x| x) d \hat x d \hat \eta_{t} (x)
\right\|_{L_2}
\notag
\\
\leq
&
\frac{f_{\max}W_{\max}}{\sqrt{N}} + \frac{f_{\max} W_{\max}c^{\frac{1}{2}}_t}{\sqrt{N}}\, .
\label{MC:SNI01}\end{aligned}")
The first term in follows by the same argument that we used to derive . The second term follows by our induction hypothesis applied to the function 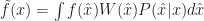
 d \hat \eta^N_{t+1} (x)
-
\int f(x) d \hat \eta_{t+1} (x)
\right\|_{L_2}
\leq 2 \frac{f_{\max}W_{\max}}{\sqrt{N}} + 2\frac{f_{\max} W_{\max}c^{\frac{1}{2}}_t}{\sqrt{N}}\end{aligned}")
Thus we see that the require bound holds at time ^2\,.\end{aligned}") This completes the induction step and the proof.
This completes the induction step and the proof.

-
Here we have the caveat that we require
for any
.↩
