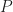The Neural Tangent Kernel is a way of understanding the training performance of Neural Networks by relating them to Kernel methods. Here we overview the results of the paper [Jacot et al. here]. The paper considers a deep neural network with a fixed amount of data and a fixed depth. The weights applied to neurons are initially independent and normally distributed. We take a limit where the width of each layer tends to infinity.
The main observations of the paper are the following:
- The function represented by a neural network changes according to a kernel when undergoing gradient descent training. This is called the Neural Tangent Kernel (NTK).
- Under a random normally distributed initialization, the NTK is random. However, under an infinite width limit, this kernel is non-random and the output of each neuron an independent gaussian distribution with zero mean and a fixed covariance.
- In the limit, these weights and thus this kernel will not change during training. This is called “Lazy training”.
- In this limiting regime, the neural network parameter converge quickly to a global minimum with weight parameters that are arbitrarily close to the initialized neural network.
These results are significant as they give a way of understanding why Neural networks converge to a optimal solution. (Neural networks are know to be highly non-convex objects and so understanding their convergence under training is highly non-trivial.) What the following argument does not (fully) explain is why neural networks are so expressive, why they generalize well to unseen, or why in practice neural networks outperform kernel methods.
Why Lazy Training Helps Convergence.
We give a short heuristic explanation as to why Lazy training helps us understand the convergence of neural networks. Suppose that the weights of a neural network remain close to the values of their initial weights. That is
 \approx W_0 \, .\end{aligned}")
Now suppose we wish to solve
}-F(W,x^{(i)}))^2 \quad \text{over} \quad W \in \mathbb R^P\end{aligned}")
where here 
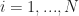
Notice under stochastic gradient decent 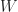
},\hat x)(\hat y - F({W(t)},\hat x) ) ] \, ,\end{aligned}")
where here 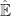


},x)}{dt}
& =\nabla_W F({W(t)},x)^\top \frac{dW}{dt}\notag \\
& = - \hat{\mathbb E} \left[ \Big\{\nabla_W F({W(t)},x)^\top \nabla_W F({W(t)},\hat x) \Big\}( F({W(t)},\hat x) - \hat y) \right]\, . \label{NTK:diff0}\end{aligned}")
The term in curly brackets defines a kernel:
 = \nabla_W F({W},x)^\top \nabla_W F({W},\hat x)\, .\end{aligned}")
This kernel is the Neural Tangent Kernel; it’s the kernel that you get from the tangent of a neural network, 
}(x,\hat x) \approx K^{W_0}(x,\hat x) \, .\end{aligned}")
Now if the Kernel defines a positive definate matrix on the data (I.e. if 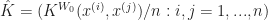
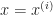
},x^{(i)})}{dt}
& = - \sum_{j=1}^N \hat K (x^{(i)},x^{(j)}) ( F({W(t)},x^{(j)}) - y^{(j)}) \,,\quad i=1,...,N.\end{aligned}")
(*)
We can analyze the error between the Neural network’s estimate and the data 

Since 
 = \epsilon (0) e^{-\hat K t} \xrightarrow[t\rightarrow\infty]{} 0 \, .\end{aligned}")
Now we see that if weights and the Neural Tangent Kernel defined by is (approximately) constant then the neural network trained under converges fast to a state with zero loss.
Next we need to argue that weights and the neural tangent kernel remain approximately constant during training. But first we define a bit more notation.
Neural Network Model.
We consider a dense 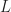
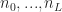

We let 
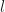
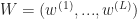

Given the activations 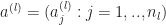
} =
\frac{1}{\sqrt{n_l}}
\sum_{j=1}^{n_l}
w_{ij}^{(l+1)} a_j^{(l)} + w_{i0}^{(l)} \beta \end{aligned}")
and then we define
} = \sigma(z_i^{(l+1)}), \qquad i=1,...,n_l \, .\end{aligned}")
(Notice that above we rescale the weights by a factor of 
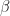
Starting with inputs 





We recall the definition of the Neural Tangent Kernel as given above
Definition [Neural Tangent Kernel] For a neural network with weights 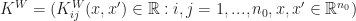
&:= \nabla_W F_i(W,x)^\top \nabla_W F_j(W,x') \\
&= \sum_{p=1}^{P}
\partial_{w_p} F_i(W, x) \partial_{w_p} F_i(W,x')\end{aligned}")
where here 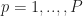
Neural Networks with Gaussian Weights.
The following shows how initializing the Neural Network effects the distribution of its output. We show that in a multi-layer neural network initialized with Gaussian weights at each neuron as an output that is independent and Gaussian distributed when the width of each layer tends to infinity.
In this limit, each layer affects the covariance of the next layer in a constant way. We can use this to show that the initial Neural Tangent Kernel (which is random in the prelimit) tends to a non-random Kernel.
Proposition 1. In the limit as 


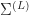
}(x,x') &= \frac{1}{n_0} x^\top x' + \beta^2
\\
\Sigma^{(l+1)}(x,x') & =
\mathbb E_{(z,z') \sim \mathcal N(0, \Sigma^{(l)}(x,x'))}
\left[
\sigma(z) \sigma(z')
\right]
+ \beta^2.\end{aligned}")
The Neural Tangent Kernel is such that 


}(x,x') = & \Sigma^{(1)}(x,x')\\
K^{(l+1)}(x,x')
= & \dot{\Sigma}^{(l)}(x,x') K^{(l)}(x,x') + {\Sigma}^{(l)}(x,x') \, ,\end{aligned}")
where
}(x,x') & =
\mathbb E_{(z,z') \sim \mathcal N(0, \Sigma^{(l)}(x,x'))}
\left[
\dot \sigma(z)\dot \sigma(z')
\right] \, .\end{aligned}")
Proof. The result follows by induction on the number of layers 
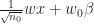
Lets assume the induction hypothesis that, in the limit where 

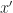
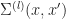

 \xrightarrow[n_1,...,n_{L-1} \rightarrow \infty ]{} K^{(L)}(x,x')\end{aligned}")
where 
Knowing what happens layer 

}(W,x) = \frac{1}{\sqrt{n_l}} \sum_{j=1}^{n_{l+1}} w_{ij}^{(L+1)} \sigma(F^{(L)}_j(W,x))\end{aligned}")
and, if we differentiate a parameter indexed by 
}_p} F_i^{(L+1)}
=
\begin{cases}
\frac{1}{\sqrt{n_{L+1}}}
\sigma(F^{(L)}_j), & \text{if } l=L+1\text{ and } p =(i,j) \, , \\
\frac{1}{\sqrt{n_{L+1}}}
\sum_{j=1}^{n_{L+1}} w_{ij}^{(L+1)}
\dot \sigma(F_j^{(L)}) \partial_{w_p^{(l)}} F_j^{(L)}\, ,
& \text{if } l \leq L \, , \\
0 \, , & \text{otherwise.}
\end{cases}\end{aligned}") (Note that this is just BackPropogation)
(Note that this is just BackPropogation)
Let’s analyse . Notice that if we condition of the weights upto layer 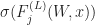

}(W,\cdot) | W^{(L)}) \sim \mathcal N (0, \hat \Sigma^{(L+1)}) \end{aligned}")
where
}(x,x') = \frac{1}{n_l} \sum_{i=1}^{n_L} \sigma(F_i^{(L)}(W^{(L)},x) )\sigma(F_i^{(L)}(W^{(L)},x')) \, .\end{aligned}")
and the outputs are (conditionally) independent over 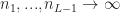
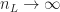
}(x,x') \xrightarrow[n_L \rightarrow \infty ]{w.p. 1} \Sigma^{(L+1)}(x,x')\, ,\end{aligned}")
where 

Next, let’s analyse the NTK. Given , we can see that there are two cases depending on whether the weights belong to the final layer or not: I.e. the NTK is
}_p} F_i^{(L+1)}
\partial_{w^{(L)}_p} F_j^{(L+1)}
}_{(A)} +
\underbrace{
\sum_{l \leq L} \sum_p
\partial_{w^{(l)}_p} F_i^{(L+1)}
\partial_{w^{(l)}_p} F_j^{(L+1)}
}_{(B)}\end{aligned}")
Given , we deal with the two terms 
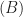
Notice from , the terms in 
For term
}_p} F_i^{(L+1)}
\partial_{w^{(l)}_p} F_j^{(L+1)}
=
\sum_{i', j'}
w_{ij'}^{(L+1)} w_{jj'}^{(L+1)} \dot{\sigma} ( F_{i'}^{(L)})\dot{\sigma} ( F_{j'}^{(L)})
\partial_{w^{(l)}_p} F_{i'}^{(L)}
\partial_{w^{(l)}_p} F_{j'}^{(L)}\end{aligned}") So
So
}_p} F_i^{(L+1)}(x)
\partial_{w^{(l)}_p} F_j^{(L+1)}(x')
\\=&
\sum_{i', j'}
w_{ii'}^{(L+1)} w_{jj'}^{(L+1)} \dot{\sigma} ( F_{i'}^{(L)}(x))\dot{\sigma} ( F_{j'}^{(L)}(x'))
\left[
\sum_{l \leq L} \sum_p
\partial_{w^{(l)}_p} F_{i'}^{(L)}(x)
\partial_{w^{(l)}_p} F_{j'}^{(L)}(x')
\right]
\\
\xrightarrow[n_1,..,n_{L-1} \rightarrow \infty ]{}
&
\sum_{i', j'}
w_{ii'}^{(L+1)} w_{jj'}^{(L+1)} \dot{\sigma} ( F_{i'}^{(L)}(x))\dot{\sigma} ( F_{j'}^{(L)}(x'))
K^{(L)}(x,x') \delta_{i'j'}
\\
=&
\sum_{i'=1}^{n_l}
w_{ii'}^{(L+1)} w_{ji'}^{(L+1)} \dot{\sigma} ( F_{i'}^{(L)}(x))\dot{\sigma} ( F_{i'}^{(L)}(x'))
K^{(L)}(x,x')
\\
\xrightarrow[n_L \rightarrow \infty ]{}
&
\delta_{ij} \dot{\Sigma}(x,x') K^{(L)}(x,x') \, .\end{aligned}") In the above we note that term in square brackets is the NTK for the depth
In the above we note that term in square brackets is the NTK for the depth 
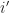
Lazy Weights.
We now sketch out why weights remain approximately constant during training. Recall that weights change according to }({W(t)},\hat x)d^{(L+1)}(t) ) ] \end{aligned}")
Previously we took 
In the limit where 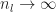


}(t) - w^{(l)}(0)\right) \right\|_{op}
&
= 0
\\
\lim_{n_L \rightarrow \infty} ... \lim_{n_1 \rightarrow \infty}
\left\| \frac{1}{\sqrt{n_l}} \left( F^{(l)}(t) - F^{(l)}(0)\right) \right\|_{\hat{\mathbb E}}
&
= 0\end{aligned}")
(Here 

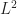
We give a sketch proof as otherwise we will spend too much time defining norms etc… To make notation a bit shorter we write 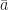
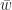
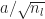

Proof Sketch. (see original paper for full proof — https://arxiv.org/abs/1806.07572 ) First we show 
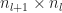
}(0) ||_{op} \leq \sqrt{n_{l+1}} \max_{i=1,...,n_{l}} \left( \sum_{j=1}^{n_l} w_{ij}^{(l)}(0)^2 \right)^{\frac{1}{2}} \, .\end{aligned}")
If the components of 

Next we argue that the scaled activations 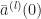


}(0)^2\, .\end{aligned}")
Now let’s analyze the change in 
}= \hat{\mathbb E} [ \partial_{w^{(l)}_{ij}}F^{(L+1)}({W(t)},\hat x) \cdot d^{(L+1)}(t, \hat x) ) ] \end{aligned}")
We know for 
}_p} F_i^{(k)}
=
\frac{1}{\sqrt{n_{k}}}
\sum_{j=1}^{n_{k}} w_{ij}^{(k)}
\dot \sigma(F_j^{(k-1)}) \partial_{w_p^{(l)}} F_j^{(k-1)}\, ,\end{aligned}")
and 
}
=
\frac{1}{\sqrt{n_l}}
\hat{\mathbb E} [
a^{(l)} \cdot d^{(l)}(t,\hat x)
]\end{aligned}")
where we inductively define
}(t) = \frac{1}{\sqrt{n_{k}}}
\sum_{j=1}^{n_{k}} d^{(k)}(t) w_{ij}^{(k)} \dot \sigma(F_j^{(k-1)}) \, .\end{aligned}")
(Already at this point the division by
Now it is not hard to check that 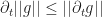

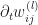
}|| \leq \frac{1}{\sqrt{n_l}}||\bar a^{(l)} ||\cdot || d^{(l)}||
\leq
\frac{c}{\sqrt{n_l}}||\bar F^{(l)} ||\cdot || d^{(l)}||\end{aligned}")
where 
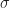
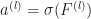
We now have two terms to deal with 

}({W(t)},x)
& = \hat{\mathbb E} \left[ K_{{W(t)}}^{(l)}(x,\hat x) d^{(l)}(t,\hat x)\right]\, .\end{aligned}")
where 

}({W(t)},x)||
& \leq \frac{1}{\sqrt{n_l}} ||K_{{W(t)}}^{(l)}||\cdot || d^{(l)}||\, .\end{aligned}")
So to understand 
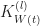

} = \frac{w^{(l)}}{\sqrt{n_l}}\dot \sigma K^{(l-1)} \dot \sigma \frac{w^{(l)} }{\sqrt{n_l}}+ \frac{a^{(l)}a^{(l)}}{n_l} + \beta^2\end{aligned}")
So
} || \leq \beta^2 + c^2 ||\bar w^{(l)}||^2 || K^{l-1} || + c || \bar F^{(l)} ||^2\end{aligned}")
also analyzing
} ||\leq c ||d^{(l-1)}|| ||\bar w ||_{op} \,.\end{aligned}")
Thus both 



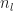


}(t)||+||\bar F^{(l)}(t)|| \right\}
\leq \frac{1}{\sqrt{n_{\min}}}P \left( \sum_l ||\bar w^{(l)}(t)||+||\bar F^{(l)}(t)||\right)\end{aligned}")
for some polynomial