Markov Decisions Problems; Bellman’s Equation; Two examples
A Markov Decision Process is a Dynamic Program where the state evolves in a random/Markovian way.
As in the post on Dynamic Programming, we consider discrete times , states , actions and rewards . However, the plant equation and definition of a policy are slightly different.
Def 1 [Plant Equation] The state evolves according to functions . Here
where are IIDRVs uniform on . This is called the Plant Equation. As noted in the equivalence above, we will often suppress dependence on . Also, we will use the notation
Def 2 [Policy] A policy choses an action at each time as a function of past states and past actions . We let be the set of policies.
A policy, a plant equation, and the resulting sequence of states and rewards describe a Markov Decision Process. Objective is to find a process that optimizes the following objective.
Def 3 [Markov Decision Problem] Given initial state , a Markov Decision Problem is the following optimization
Further, let (Resp. ) be the objective (Resp. optimal objective) for when the summation is started from time and state , rather than and .
Ex 1 [the Bellman Equation]Setting for
The above equation is Bellman’s equation for a Markov Decision Process.
Ex 2 You need to sell a car. At every time , you set a price and a customer then views the car. The probability that the customer buys a car at price is . If the car isn’t sold be time then it is sold for fixed price , . Maximize the reward from selling the car and find the recursion for the optimal reward when .
Ex 3 You own a call option with strike price . Here you can buy a share at price making profit where is the price of the share at time . The share must be exercised by time . The price of stock satisfies for IIDRV with finite expectation. Show that there exists a decreasing sequence such that it is optimal to exercise whenever occurs.
Answers
Ans 1, the set policies that can be implemented from time to , is the product actions at time and the set of policies from time onward. That is .
2nd equality uses structure of , takes the term out and then takes conditional expectations. 3rd equality takes the supremum over , which does not depend on , inside the expectation and notes the supremum over is optimized at a fixed action (i.e. the past information did not help us.)
Ans 2 The optimal reward from time onward (assuming you still have the car) satisfies:
If then . (Note the relation is monotone and converges to fixed point if .)
Ans 3 Taking the and subtracting gives
1) , because all policies implemented from time are subset of policies from time .
2) is decreasing and cts in because is and, since expectation and maximum preserve these properties, so is by induction on .




![f_t: \mathcal{X}\times \mathcal{A}_t \times [0,1] \rightarrow \mathcal{X}](https://s0.wp.com/latex.php?latex=f_t%3A+%5Cmathcal%7BX%7D%5Ctimes+%5Cmathcal%7BA%7D_t+%5Ctimes+%5B0%2C1%5D+%5Crightarrow+%5Cmathcal%7BX%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 \equiv f_t(x_t,a_t)")

![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
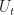
] = \mathbb{E} [G(f_t(x_t,a_t))]")
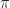
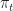


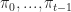
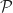
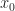
 =& \text{Maximize} \quad R_T(x_0,\Pi):= \mathbb{E} \left[ \sum_{t=0}^{T-1} r_t(x_t,\pi_t) + r_T(x_T)\right]\\ &\text{over} \qquad\qquad \Pi \in \mathcal{P}.\notag \end{aligned}")
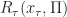

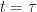




 = \sup_{a_t\in\mathcal{A}_t} \left\{ r_t(x_t,a_t) + \mathbb{E}_{x_t,a_t} \left[ W_{t+1}(x_{t+1})\right] \right\}.")
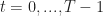








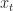
 for
for 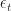


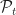


 &= \sup_{\Pi_t \in \mathcal{P}_t} \mathbb{E}_{x_t \pi_t} \left[ \sum_{t=0}^{T-1} r_t(x_t,\pi_t) + r_T(x_T)\right]\\ &= \sup_{\pi_t } \sup_{\Pi \in \mathcal{P}_{t+1}} \Bigg\{ r_t(x_t,\pi_t) + \mathbb{E}_{x_t \pi_t} \Bigg[\mathbb{E}_{x_{t+1} \pi_{t+1}}\Bigg[\sum_{\tau=t+1}^{T-1} r_{\tau}(x_\tau,\pi_\tau) + r_T(x_T)\Bigg]\Bigg]\Bigg\}\\ &= \sup_{a\in\mathcal{A} } \Bigg\{ r_t(x_t,a) + \mathbb{E}_{x_t\, a} \Bigg[ \underbrace{\sup_{\Pi \in \mathcal{P}_{t+1}}\mathbb{E}_{x_{t+1} \pi_{t+1}}\Bigg[\sum_{\tau=t+1}^{T-1} r_{\tau}(x_\tau,\pi_\tau) + r_T(x_T)\Bigg]}_{=W_{t+1}(x_{t+1})}\Bigg]\Bigg\} \end{aligned}")



p +(1-D(p)) W_{t+1}\right\}")



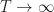

-x = \max\left\{ -p, \mathbb{E}\left[W_{t+1}(x+\epsilon_t) -x \right] \right\}")




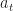
![p=\mathbb{E}\left[W_{t+1}(a_t+\epsilon_t) -a_t\right]](https://s0.wp.com/latex.php?latex=p%3D%5Cmathbb%7BE%7D%5Cleft%5BW_%7Bt%2B1%7D%28a_t%2B%5Cepsilon_t%29+-a_t%5Cright%5D+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
