- Continuous-time dynamic programs
- The HJB equation; a heuristic derivation; and proof of optimality.
Discrete time Dynamic Programming was given in previously (see Dynamic Programming ). We now consider the continuous time analogue.
Time is continuous 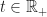


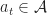
Def 1 [Plant Equation] Given function 
.")
This is called the Plant Equation.
Def 2 A policy 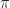
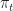





Def 3 [Continuous Dynamic Program] Given initial state 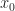
:=\; &\text{Minimize} \qquad C({\bf a}) := \int_{0}^{T}\!\! e^{-\alpha t}c_t(x_t,a_t) dt + e^{-\alpha T}c_T(x_T)\\ & \text{subject to} \qquad \frac{dx_{t}}{dt}= f_t(x_t, a_t), & t\in\mathbb{R}_+ \notag \\ & \text{over}\qquad \quad\qquad a_t \in \mathcal{A},& t\in\mathbb{R}_+\notag \end{aligned}")
Further, let 

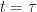

When a minimization problem where we minimize loss given the costs incurred is replaced with a maximization problem where we maximize winnings given the rewards received. The functions 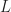


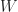


Def 4 [Hamilton-Jacobi-Bellman Equation] For a continuous-time dynamic program , the equation
+ \partial_t L_t(x) + f_t(x,a)\partial_x L_t(x) - \alpha L_t(x). \right\}")
is called the Hamilton-Jacobi-Bellman equation. It is the continuous time analogoue of the Bellman equation [[DP:Bellman]].
Ex 1 [A Heuristic derivation of the HJB equation] Argue that, for 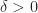
")
is a good approximation to the plant equation . (A heuristic argument will suffice)
Ex 2 [Continued] Argue (heuristically) that following is a good approximation for the objective of a continuous time dynamic program is
 := \sum_{t\in\{0,\delta,...,\delta(T-1)\} } (1-\alpha \delta)^{ {t}/{\delta}}c_t(x_t,a_t) \delta + (1-\alpha \delta)^{ {t}/{\delta}}c_T(x_T) \end{aligned}")
Ex 3 [Continued]Show that the Bellman equation for the discrete time dynamic program with objective and plant equation is
 = \min_{a\in \mathcal{A}}\left\{ c_t(x,a)\delta + (1-\alpha \delta) L_{t+\delta}(x_t+\delta f_t(x,a)) \right\}")
Ex 4 [Continued]Argue, by letting 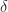
+ \partial_t L_t(x) + f_t(x,a)\partial_x L_t(x) - \alpha L_t(x). \right\}")
Ex 5 [Optimality of HJB] Suppose that a policy 

(Hint: consider 

Linear Quadratic Regularization
Def 5. [LQ problem] We consider a dynamic program of the form 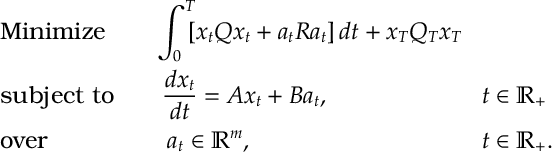
Here 



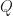
Ex 6. [LQ Regulatization] Show that the HJB equation for an LQ problem is
 + (Ax + Ra)^\top \partial_x L_t(x) \right\}")
Ex 7. [Continued] We now “guess” that the solution to above HJB equation is of the form 

 x")
and thus for the minimum in the HJB equation to be zero we require
+ \Lambda(t)A + A^\top \Lambda(t) - \Lambda(t) B R^{-1} B^{\top} \Lambda(t) -Q \right]x")
Ex 8. [Continued] Show that for the HJB equation to be satisfied then it is sufficent that
 = -Q-\Lambda(t)A - A^\top \Lambda(t) + \Lambda(t) B R^{-1} B^{\top} \Lambda(t)\quad and\quad \Lambda(T)=Q_T.")
Def 6. [Riccarti Equation] The differential equation is called the Riccarti equation.
Ex 9. [Continued] Argue that a solution to the Riccarti Equation is optimal for the LQ problem.
Answers
Ans 1 Obvious from definition of derivative.
Ans 2 Obvious from definition of (Riemann) Integral and since 

Ans 3 Immediate from discrete time Bellman Equation.
Ans 4 Minus 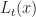
 L_{t+\delta}(x+\delta f) - L_t(x)}{\delta} \xrightarrow[\delta \rightarrow 0]{ }\partial_t L_t(x) + f_t(x,a)\partial_x L_t(x) - \alpha L_t(x).")
Ans 5 Using shorthand 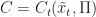
\right)&=e^{-\alpha t} \left\{ c_t(\tilde{x}_t,\tilde{\pi}_t) - \left[ c_t(\tilde{x}_t,\tilde{\pi}_t) - \alpha C + f_t(\tilde{x}_t,\tilde{\pi}_t) \partial_x C + \partial_t C\right]\right\}\\ &\leq e^{-\alpha t} c_t(\tilde{x}_t,\tilde{\pi}_t) \end{aligned}")
The inequality holds since the term in the square brackets is the objective of the HJB equation, which is not maximized by 
Ans 6. Immediate from Def 4.
Ans 7. 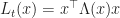
 = 2 \Lambda(t) x \quad \text{and} \quad \partial_t L_t(x) = x^\top \dot{\Lambda}(t) x")
Substituting into the Bellman equation gives
 x + 2 x^\top \Lambda(x) ( A x + B a) \right\}")
Differentiating with respect to
 B =0")
which implies
 x")
Finally substituting into the Bellman equation, above, gives the required expression
Ans 8. For the minimum in the HJB equation to be zero, we require
+ \Lambda(t)A + A^\top \Lambda(t) - \Lambda(t) B R^{-1} B^{\top} \Lambda(t) -Q \right]x")
Thus for the term in square brackets to be zero is sufficent.
Ans 9. This is just applying [5].
