The Weighted Majority Algorithm is a randomized rule used to learn the best action amongst a fixed reference set.
We consider the following setting
- There are a fixed set of actions
which one may choose. There are a set of outcomes
.
- After choosing an action
, an outcome
occurs and you receives a reward
. Over time a policy
chooses actions
and outcomes
,
- It is assumed that the function
is known by the policy.
- The accumulated a net reward is
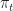
:=\sum_{t=1}^T r(\pi_t,y_t).")
We are interested in how our dynamic policy
- For this reason, we consider the regret of policy
:=\max_{i=1,...,N}\left\{ \rho(i,T) -\bE \rho(\pi,T)\right\}.")
- We can only retrospectively find the best fixed policy, whilst our policy
quantifies how we regret not having had the information to have chosen the best fixed policy.
- Note a ‘good’ policy would have low regret. For instance, we might hope our dynamic policy is as good as the best fixed policy, i.e.
.
Using Blackwell’s Approachability Theorem, we saw that low regret policies exist. See Section [Blackwell]Theorem [blackwell:regret]. One of the key advantages of such algorithms is that is does not place statistical assumptions on the outcome sequence 
Weighted Majority Algorithm
For parameter 


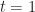
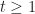

We can derived the following regret bound
Theorem: If policy
(1) With 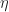
 \leq \eta^{-1} \log(N) + \frac{\eta T}{2},")
for choice 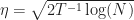
 \leq 2\sqrt{2T \log(N)}.")
(2) For
 \geq \frac{1 }{1-e^{-\eta}} \left\{ \eta \max_{i=1,...,N} \rho(i,T) +\log N\right\}.")
(3) For 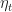
 \leq \eta_T^{-1} \log(N) + \frac{1}{8} \sum_{t=1}^T \eta_t,")
for choice 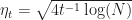
 \leq \sqrt{ T \log N}") •
•
Proof:
(1) Observe
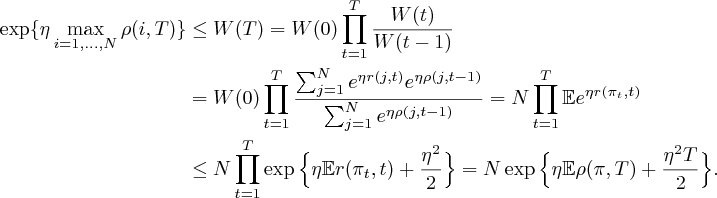
In the second inequaltiy, we apply the Azuma-Hoeffding Inequality, see Section [Azuma]. Taking logs and rearranging, we gain the required expression . Substituting
(2) We note the following inequality holds
} \leq \bE [ (e^\eta -1)r(\pi_t,t) +1 ] \leq \exp\{ (e^{\eta}-1) \bE r(\pi_t,t)\}.")
In the first inequality, we bound with the line segment above the exponential. In the second inequality, we apply the bound 
\} \leq N \prod_{t=1}^T \bE e^{\eta r(\pi_t,t)} \leq N \exp\{(e^{\eta}-1) \bE \rho(\pi,T) \}.")
Taking logs and rearranging gives the required bound.
(3) The crux of the proof (1) was that the function 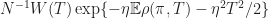

We can express our weights differently, notice,
= \frac{\frac{1}{N}s_{i,t-1}^{\eta_t/\eta_{t-1}} }{\frac{1}{N} \sum_{j=1}^N s_{j,t-1}^{\eta_t/\eta_{t-1}}},\qquad \text{where}\qquad s_{i,t-1} & = \exp\left\{-\eta_{t-1} \rho(i,t-1) + \eta_{t-1} {\mathbb E} \rho(\pi, t-1) - \frac{1}{8}\eta_{t-1}\sum_{k=1}^{t-1} \eta_k \right\}\\ \text{and}\qquad\quad S(t) & = \frac{1}{N} \sum_{i=1}^N s_{i,t}.\notag \end{aligned}")
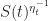
^{\frac{1}{\eta_t}} % &\leq \left( \frac{1}{N} \sum_{j=1}^Ns_{j,t-1}^{{\eta_t}/{\eta_{t-1}}}\cdot e^{-\eta_t r(j,t) + \eta_t\bE r(\pi_t,t) - \frac{\eta_t^2}{8}} \right)^{\frac{1}{\eta_t}} \\ % & = \underbrace{\Bigg( \bE e^{-\eta_t r(\pi_t,t) + \eta_t (\bE r(\pi_t,t)) - \frac{\eta_t^2}{8}}\Bigg)^{\frac{1}{\eta_t}} }_{\leq 1, \text{ by Azzuma-Hoeffding}} \times \underbrace{ \left( \frac{1}{N} \sum_{j=1}^N s_{j,t-1}^{\eta_t/\eta_{t-1}}\right)^{\frac{1}{\eta_t}}}_{\leq S(t-1)^{\frac{1}{\eta_{t-1}}} \text{ by Jensen's Ineq}} \leq S(t-1)^{\frac{1}{\eta_{t-1}}} \end{aligned}")
Since 


