In loose terms, the mixing time is the amount of time to wait before you can expect a Markov chain to be close to its stationary distribution. We give an upper bound for this.
We consider the following setup:
- We consider a discrete time Markov chain on finite state space
and transition matrix
.
- We assume that the Markov chain is irreducible and aperiodic and has stationary distribution,
.
- We will, at the end, assume that our Markov chain is reversible,1 that is for all
it satifies detailed balance

Here is a rough description of the main idea. We could diagonalize 


where 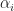



We want to compare the marginal distribution of the Markov chain at a fixed time to the stationary distribution.
- For two probability distribution
and

- For each
, the mixing time with respect to the total variation norm is
 = \min \Big\{ n \geq 0 : \Big|\Big| P^n_{x,\cdot} - \pi \Big|\Big|_{TV} \leq \epsilon, \forall x\in\mX \Big\}.")
We prove some results about a mixing times with respect to a norm which is much more taylored to our chain; we then go back to total variation.
- For
and
, we define the norm
and inner product
by
^2,\qquad <f,g>_\pi = \sum_{x\in\mX} \pi_x f_x g_x.")
- Note that the the distance
is convex. So in the above definition, once we have reached the mixing time from each initial state
, the chain is mixed from all initial distributions.
For the following proposition, we define
 = \frac{P^n_{xy}}{\pi_y}\qquad\text{and}\qquad \tau_{\pi}(\epsilon) = \min \Big\{ n \geq 0 : \Big|\Big| f^n_x - 1 \Big|\Big|_{\pi} \leq \epsilon, \forall x\in\mX \Big\}.")
The mixing time 
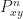


Prop 1.  \leq \frac{1}{1- ||{P}||} \log \frac{1}{\epsilon \sqrt{\pi_{\min}}} \qquad\text{ where }\quad \pi_{\min}= \min_i \pi_i\quad\text{ and }\quad || {P}|| = \sup_{\substack{f:\mX\rightarrow \bR\\ \bE f =0 }} \frac{||{P} f ||_{2,\pi}}{||f||_{2,\pi}}.\label{PNorm}")
Proof. Observe that  = \sum_y \frac{P_{zy}}{\pi_y} P^n_{xy}= \sum_y P^n_{xy}\frac{P_{yz}}{\pi_z} = \frac{P^{n+1}_{xz}}{\pi_z} = f_x^{n+1}(z).")
So, in short, 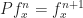
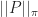
 ||_\pi \leq || P ||_\pi \cdot || f_x^{n-1} -1 ||_\pi \leq ... \leq || P ||^n_\pi \cdot || f_x^{0} -1 ||_\pi \leq ||P||^n_\pi \cdot \frac{1}{\sqrt{\pi_{\min}}} .") The final inequality is a straightforward bound on
The final inequality is a straightforward bound on 
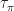

rearranging for 

The above bound gives the main flavour, we expect convergence to stationarity to be exponentially fast. Still, there is work left: our distance metric depends on our stationary distribution and we need to guarentee that 
We use the following lemma (which we don’t currently prove). The result for the better part is a statement of Spectral Theorem, which states an analogous result for symmetric matrices.2 As a consequence, the lemma below involves making the observation that for a reversible chain 
Lemma 1. For the transition matrix of a reversible Markov chain, eigenvalues of are all real valued each with magnitude less than one (with one attaining this value) and their eigenvectors form an orthogonal basis (with repect to 
However, we use it to prove the following lemma
Lemma 2.

Proof. The definition of 

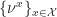


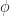



Clearly this is maximized by chosing all off the weight of 
The above lemma extracts a definition for
 \leq \tau_\pi (\epsilon).")
Basically 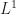
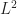
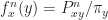
 - 1 \Big| \leq \left( \sum_{y\in\mX} \pi_y \Big( f^n_{x}(y) - 1 \Big)^2 \right)^{\frac{1}{2}}= \Big|\Big| f^n_x - 1 \Big|\Big|_{\pi}.")
Putting together the last two lemmas and Proposition [Mix:Prop], we have the following result.
Theorem. where
where 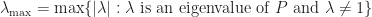
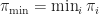
Literature
The arguments here are based on reading the two sources:
Montenegro, Ravi, and Prasad Tetali. “Mathematical aspects of mixing times in Markov chains.” Foundations and Trends® in Theoretical Computer Science 1.3 (2006): 237-354.
Levin, David A., and Yuval Peres. Markov chains and mixing times. Vol. 107. American Mathematical Soc., 2017.
