The exponential family of distributions are a particularly tractable, yet broad, class of probability distributions. They are tractable because of a particularly nice [Fenchel] duality relationship between natural parameters and moment parameters. Moment parameters can be estimated by taking the empirical mean of sufficient statistics and the duality relationship can then recover an estimate of the distributions natural parameters.
Def [Exponential Family of Distributions] An exponential family is probability distributions of the form
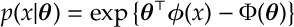
where
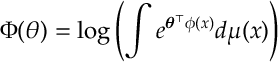
for 

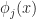
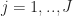

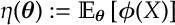 for
for 


A happy family! A large number of probability distributions: Normal, Poisson, Geometric, Binomial, Gamma, Exponential… are in the exponential family.
The really nice thing about exponential families is the relationship between sufficient statistics and natural parameters: there is a [Legendre-Fenchel] duality between them.
MLEs. A consequence of this is we can often calculate a maximum likelihood estimator (MLE). Suppose we know what the function 
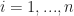
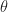

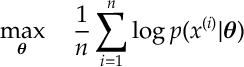 by
by
- Calculating
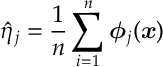
- and taking
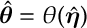
Cross Entropy. We can generalize this MLE statement slightly as follows. Suppose that 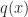


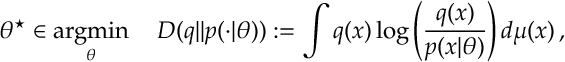
which we note is equivalent to maximizing the cross entropy
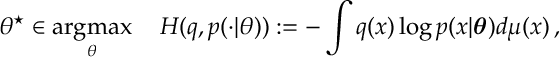
then 

Some Results. Most of this can be verified through the following sequence of results which we do not prove here but are, for the most part, an application of Legendre-Fenchel duality to the log-likelihood function.
Suppose that 
a) [MGF] The moment generating function of 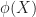
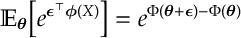
b) [Moments]
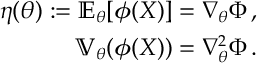
c) [Convex] 

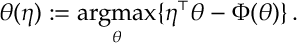
d) [Duality of Moments] If we define 
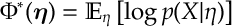
Hence
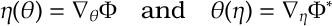
e) [Relative Entropy] As discussed above, for any distribution 
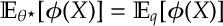
f) [MLE] For data

is given by
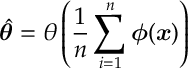
A Brief Proof.
a) Follows from definition of
b) Differentiate the MGF.
c) 
d) For LF-transforms if strictly convex then gradients [and their inverses] are unique.
e) Note this is just part c) with ![\eta = \mathbb E_q [\phi(X)]](https://s0.wp.com/latex.php?latex=%5Ceta+%3D+%5Cmathbb+E_q+%5B%5Cphi%28X%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)





Great reading your bblog post
LikeLike