This is a quick note on policy gradients in bandit problems. There are a number of excellent papers coming out on the convergence of policy gradients [1 ,2, 3]. I wrote this sketch argument a few months ago. Lockdown and homeschooling started and I found I did not have time to pursue it. Then yesterday morning I came across the following paper Mei et al. [1], which uses a different Lyapunov argument to draw an essentially the same conclusion [first for bandits then for general RL]. Although most of the time I don’t talk about my own research on this blog, I wrote this short note here just in case this different Lyapunov argument is of interest.
Further, all these results on policy gradient are [thus far] for deterministic models. I wrote a short paper that deals with a stochastic regret bound for a policy gradient algorithm much closer to projected gradient descent, again in the bandit setting. I’ll summarize this, as it might be possible to use it to derive stochastic regret bounds for policy gradients more generally. At the end, I discuss some issues around getting some proofs to work in the stochastic case and emphasize the point that 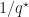
We consider a multi-arm bandit setting. Here there are a finite set of arms 


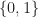

A policy gradient algorithm is an algorithm where you directly parameterize the probability of playing each arm and then you perform a gradient descent/stochastic approximation update on these parameters. The most popular parameterization is soft-max: here the probability of playing arm 
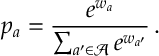
Here there are the weights 
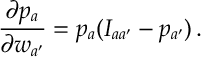
where here 
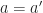


We want to maximize expected the reward (plus or minus a constant 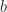
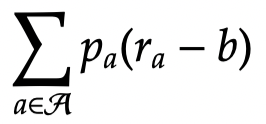
So given the last two expressions, for each arm
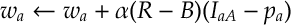
where 



If we can model change in these weights over time with the following o.d.e.
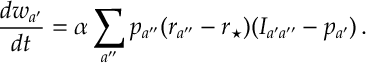
Here we let 
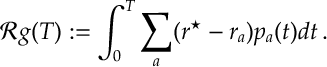
This measures how much reward has been lost by not playing the optimal arm.
Given the above we also define
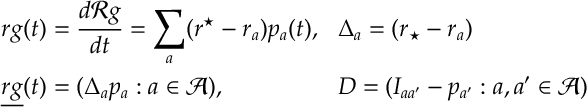
The following short argument bounds the change in the regret:
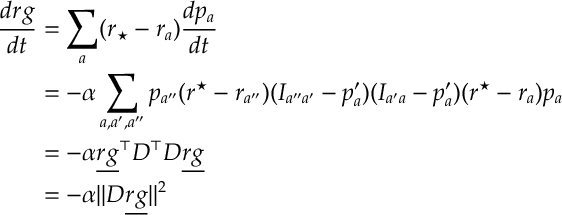
Let’s analyze the above term
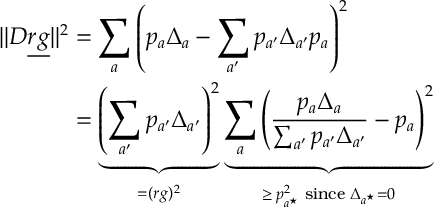
Therefore we have the bound
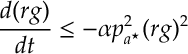
Dividing by 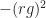

So notice things depend on the probability of playing the optimal arm. Assuming all arms start are equal the optimal arm 
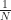

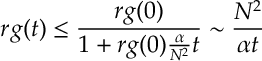
Thus we have
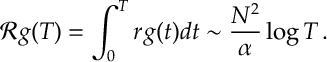
(Notice the dependence on 

Stochastic Regret Bounds
So do these sorts of convergence results flesh out when we allow for stochastic effects. A proof for a slightly different policy works, and I’ll sketch out the main argument then the technical issues.
First convergence for probabilities can’t go faster than 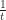
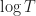


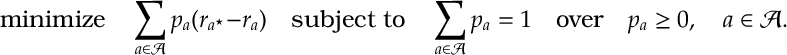
We can just not reparameterize and apply projected gradient descent.
SAMBA. Analogous to the soft-max discussion above. This is how to derive a stochastic policy gradient algorithm in this case. [Projected] Gradient descent the perform the update 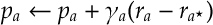 for
for 

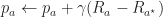



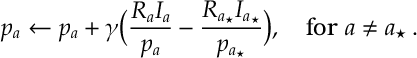
This gives a simple recursion for a multi-arm bandit problem. A name for this is SAMBA: stochastic approximation multi-arm bandit. Catchy acronyms aside, one can see this is really a stochastic gradient descent algorithm with some correction to make sure we don’t get too close to the boundary. Shortly, I’ll argue that we need to let 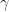
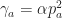
Learning rate and o.d.e. analysis. Let’s consider the learning rate 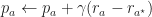

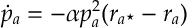
whose solution is
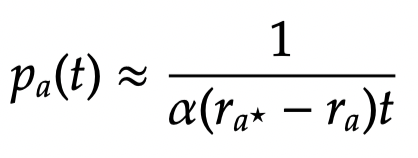
This implies
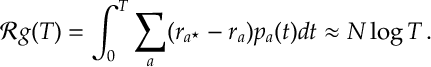
This suggest a learning rate of 
Discrete time analysis. A discrete time version of the above result is the following lemma
Lemma. If 
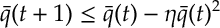
for some 
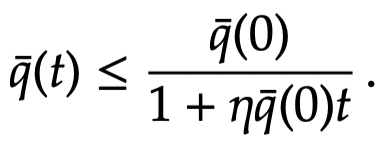
A proof of this is given at the end of this post.
martingale analysis. Notice if we let 

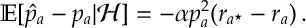
If we define 
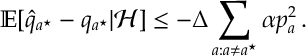
where 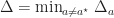
By Jensen’s inequality:
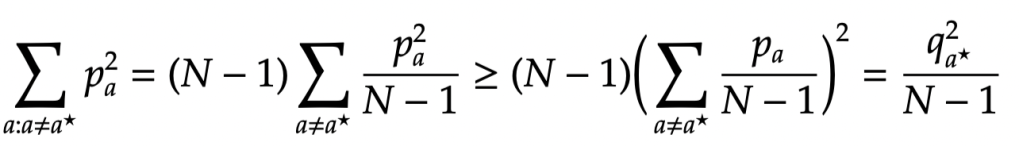
Thus applying the above bound gives
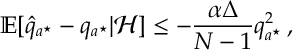
Here we have a positive super-martingale, so by Doob’s Martingale Convergence Theorem 
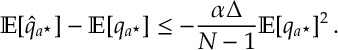
Thus the lemma above gives
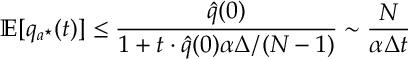
which then leads the following stochastic regret bound
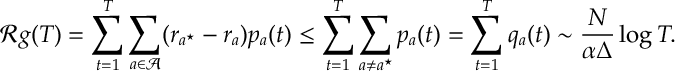
Discussion on Convergence Issues. Both soft-max and SAMBA step rules require some form of best arm identification. For SAMBA this is explicit in that we need 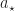
One thing that seems to come out of the analysis for both soft-max [when you include 2nd order terms] and SAMBA is that if the learning rate is too big then then this random walk switches from being transient [and thus converging on the correct arm] to being recurrent [and thus walking around the interior of the probability simplex within some region of the optimal arm]. One way to deal with this is to slow decrease the learning rate either as a function of either time 
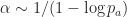
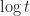


A final point is that in all the analysis so far [both softmax and SAMBA], we have used an o.d.e. of the form
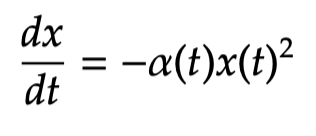
which suggests that we apply a Lyapunov function of the form:
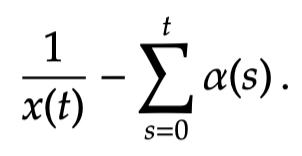
Proving martingales properties for these Lyapunov functions seems to be a key ingredient for getting stochastic proofs to work.
Appendix.
Proof of Lemma. Dividing the expression by 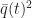
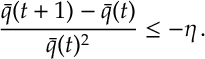
Since 
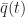
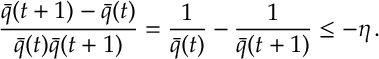
Summing from 
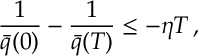
which rearranges to give
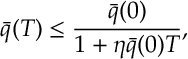
as required.
References
- Mei J, Xiao C, Szepesvari C, Schuurmans D. On the Global Convergence Rates of Softmax Policy Gradient Methods. arXiv preprint arXiv:2005.06392. 2020 May 13.
- Agarwal, A., Kakade, S. M., Lee, J. D., and Mahajan, G. Optimality and approximation with policy gradient methods in markov decision processes. arXiv preprint arXiv:1908.00261, 2019.
- Bhandari J, Russo D. Global optimality guarantees for policy gradient methods. arXiv preprint arXiv:1906.01786. 2019 Jun 5.
