We consider the problem of sequentially investing in a set of stocks.
However to start with we begin with the example of gambling on horses.
- Consider a sequence of
horse races.
- Each race has
horses and only one hose can win.
- Let
be the unit vector indicating the winning horse in the
th race i.e.
with the one in the position of the
- Let
be the proportion of our wealth that we invest in horse
given the winners so far
.
- If horse
wins we multiply our wealth by
and
for all
.
- We wish to compare the performance of our prediction policy for betting
and some set of experts
.

We want to compare the performance of our policy with the best expert. First we show that we can express this in a regret framework.
Ex 1. Argue that after 
}{p_T(\bm H_T)} \qquad\qquad \text{where} \qquad p_T(\bm H_T) = \prod_{t=1}^T p_t(\bm h_t | \bm H_t )")
and similarly for 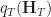
Ans 1. Starting with an initial wealth of 


 m_t(\bm h_t) \qquad \text{and} \qquad C \prod_{t=1}^T q_t(\bm h_t | \bm H_{t-1} ) m_t(\bm h_t)")
Now divide the second term by the first and maximize over 
Ex 2. [Continued] Argue that the above ratio can be expressed in terms of regret:
 = L_T(p) - \min_{q\in \mathcal Q} L_T(q)")
where the loss of a probability distribution 
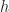
 = \log \frac{1}{p(h)}")
Ans 2. Take logs in [1] }{p_T(\bm H_T)} \right) = \log \frac{1}{p_T(\bm H_T)} - \min_{q\in \mathcal Q} \log \frac{1}{q_T(\bm H_T)}") and
and
} = \sum_{t=1}^T \log \frac{1}{p_t(\bm h_t | \bm H_{t-1})} = \sum_{t=1}^T l(p_t | \bm h_t) = L_T(p_T)\, .")
Def 3. [Minimax Regret] We look at the worse regret that a specific strategy
 &= \max_{\bm H_T} \mathcal R\! g_T(p , \mathcal Q; \bm H_T) \\ &= \max_{\bm H_T} \max_{q_T\in \mathcal Q} \log \left( \frac{q_T(\bm H_T)}{p_T(\bm H_T)} \right) \end{aligned}")
and then we look for the best strategy
 = \min_{p} \mathcal V_T( p,\mathcal Q)")
Here 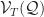
As we will see there is a unique policy that achieves this regret.
Def 4. [Normalized Maximum Likelihood Forcaster] This is the policy defined by
 = \frac{ \max_{q \in \mathcal Q} q_T(\bm H_T) }{ \sum_{\bm H'_T} \max_{q \in \mathcal Q} q_T(\bm H'_T) }")
You can bet a proportion wealth
where there is only a prize for winning
Ex 5. For any class of experts
 = \mathcal V_T( \mathcal Q)")
Ans 5. For a distribution 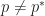

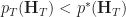
 \geq \log \left( \frac{ \max_{q\in \mathcal Q} q_T(\mathcal Q) }{ p_T(\bm H_T ) } \right) & \geq \log \left( \frac{ \max_{q\in \mathcal Q} q_T(\mathcal Q) }{ p^*_T(\bm H_T ) } \right) \\ & = \log \left( \sum_{\bm H'_T} \sup_{q\in\mathcal Q} q_T(\bm H'_T ) \right) =\mathcal V_T( p^* ,\mathcal Q) \, .\end{aligned}")
So 
Ex 6. [Continued] Show that for all
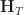
 = \log \left( \frac{ \sup_{q\in \mathcal Q} q_T(\bm H_T) }{ p^*_T(\bm H_T) } \right) = \log \left( \sum_{\bm H'_T} \sup_{q\in\mathcal Q} q_T(\bm H'_T ) \right)\, .")
Ans 6. This follows from the answer to [5].
Sequential Investment
We now develop put theory for investment strategies. Here there is now longer one winning horse/stock. We consider the goal of maximizing final wealth with respect to a set of reference strategies.
- An investor trades over
- We consider a market with
- A market vector
gives the (relative) prices of stocks over each period given period.
- For a sequence of market vectors
,
, we let
denote the history of market vectors before time
- An investment is a probability distribution
that give the proportions of (one unit of) wealth invested in each asset. This results in an increase in wealth of
 Q_i\, .")
- An investment strategy,
, is a sequence of investments
for each time
.
Def 7. [Wealth Factor] The wealth factor of an on investment strategy is given by
 = \prod_{t=1}^T \big\{ \bm S_{t}^\top \bm \pi_t (\mathcal H_{t-1}) \big\}")
Def 8. [Market Vector] For a vector 
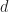
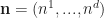

Def 9. [Wealth Factor] For a sequence of investments and stock prices 

 = \prod_{t=1}^T \left( {\mathbf n}_t\cdot {\mathbf S}_t \right)")
Def 10. [Investment Strategy] An investment strategy 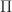


Ex 11. [Buy-and-Hold] Buy-and-hold, 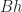

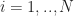
 = \sum_{i=1 }^N Q(i) \prod_{t=1}^T S_t(i)\, .")
Ans 11. It is clear the increase in asset 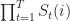
Ex 12. [Constantly rebalanced portfolio] A constantly rebalanced portfolio, 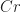

 = \prod_{t=1}^T \left( \bm F^\top \bm S_t \right)")
Ans 12. Now the increase in wealth at time
 S_t(i).")
Thus the total increase is the product of these terms.
Def 13. [Minimax Regret] For a class of investment strategies 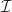
 =\log \left(\max_{P\in \mathcal P} \mathcal W\! f ( P , {\mathcal H}_T)\right) - \log \mathcal W\! f ( \Pi , {\mathcal H}_T)\, .\end{aligned}")
The minimax regret is then
 = \min_{\bm \Pi}\max_{{\mathcal H}_T\in \mathbb{R}_+^T} \mathcal R\!g_T(\Pi, \mathcal P)")
Ex 14. [Interpreting the minimax wealth ratio] Show that if 
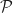
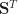
 \leq W\! f(\Pi,{\mathbf H}_T) e^{F_T}.")
(From this exercise we can interpret the regret as the factor from which we are away from the best expert.)
Ex 15. Show that if
 \leq F_T")
then there exists a policy
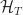
 \leq W\! f(\Pi,{\mathbf H}_T) e^{F_T}.")
(i.e. The wealth factor of the policu 

Ans 15.
 =:\mathcal W_T(\mathcal P) \leq F_T & \implies \exists\, \Pi \text{ s.t. } \qquad \max_{{\mathbf H}_T\in \mathbb{R}_+^T} \mathcal R\!g_T(\Pi, \mathcal P)\leq F_T \\ \implies & \exists \, \Pi \text{ s.t. } \forall \mathcal H_T, \qquad \mathcal R\!g_T(\Pi, \mathcal P)\leq F_T \\ \implies \exists \, \Pi \text{ s.t. }& \forall \mathcal H_T, \qquad\max_{P\in \mathcal P}W\! f(\Pi,{\mathbf H}_T) \leq W\! f(\Pi,{\mathbf H}_T) e^{F_T}. \end{aligned}")
The minimax wealth ratio is the best possible logarithmic wealth ratio & = \max_{{\mathbf H}_T\in \mathbb{R}_+^T} \max_{P \in {\mathcal P} } \;\log \left( \frac{ \mathcal W\! f ( P , {\mathbf H}_T) }{ \mathcal W\! f (\bm \Pi , {\mathbf H}_T) } \right) \\ & = \mathcal R\!g_T(\Pi, \mathcal P) \end{aligned}")
 = \min_{\bm \Pi} \mathcal W_T(\bm \Pi, {\mathcal P}).")
Def 16. [Kelly Market Vector] A market vector that has only one non-zero component is called a Kelly Market vector, i.e.
Note that we considered exactly Kelly market vectors in the previous horse race example.
We want to consider the differences for the “investment policies“ and “prediction policies” for the (horse) betting problem considered previously.
For every investment policy we can define a prediction policy:
Ex 17. Given an investment policy
 = \pi_t( i | \bm H_{t-1})")
Similarly, for every prediction policy we can define an investment policy:
Ans 17. Given a prediction strategy 
 \propto \sum_{\bm H_{t-1} \in \{0,1\}^N} p_t ( j | \bm H_{t-1} ) p_{t-1}(\bm H_{t-1}) \prod_{\tau=1}^{t-1}S_{\tau}(\bm h_{\tau})")
Nb, note that the normalization constant is given by
 \prod_{\tau=1}^{t-1} S_{\tau}(\bm h_{\tau})")
Ex 18. The wealth factor
 = F_{t+1} := \sum_{\bm H_{t+1}} p_t(\bm H_{t}) \prod_{\tau=1}^{t-1} S_{\tau}(\bm h_{\tau})")
where 
Ans 18. From Def. 7, 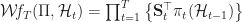
 & = \sum_{\bm h_t} S_t(\bm h_t)\pi_t( \bm h_t | \mathcal H_{t-1} ) \\ & = \frac{1}{F_t} \sum_{\bm h_t} S_t(\bm h_t) \sum_{\bm H_{t-1} \in \{0,1\}^N} p_t ( j | \bm H_{t-1} ) p_{t-1}(\bm H_{t-1}) \prod_{\tau=1}^{t-1}S_{\tau}(\bm h_{\tau}) \\ & = \frac{1}{F_t} \sum_{\bm H_{t} \in \{0,1\}^N} p_{t}(\bm H_{t}) \prod_{\tau=1}^{t}S_{\tau}(\bm h_{\tau}) \\ & = \frac{ F_{t+1} }{ F_t }\, .\end{aligned}") Thus
Thus
 = \prod_{t=1}^T \left( \frac{F_{t+1}}{F_t} \right) = F_{t+1}\, .")
In prinicple the investment problem should be more difficult that the prediction problem (used in horse racing). But the result below shows that actually they are in some sense equivalent.
Thrm 19. For a set of constantly rebalanced portfolios 
 = \mathcal V_T(\mathcal P)\, .")
Moreover, in this case, the minimax optimal investment strategy is the investment strategy induced by the normalized maximum likelihood prediction policy.
The first example confirms the intuition that investing is harder than prediction:
Ex 20. [Continued – from Thrm 19] Show that
 \geq \mathcal V_T(\mathcal P)")
Ans 20.
 = \max_{\mathcal H_t} \max_{\tilde{\Pi} \in \mathcal I} \log \left( \frac{ \mathcal W\! f ( \tilde{\Pi} , \mathcal H_T ) }{ \mathcal W\! f ( {\Pi} , \mathcal H_T ) } \right) & \geq \max_{\bm H_t \in \{ 0, 1\}^{N\cdot T}} \max_{\tilde{\Pi} \in \mathcal I} \log \left( \frac{ \mathcal W\! f ( \tilde{\Pi} , \bm H_T ) }{ \mathcal W\! f ( {\Pi} , \bm H_T ) } \right) \\ & = \max_{\bm H_t \in \{ 0, 1\}^{N\cdot T}} \max_{\tilde{\Pi} \in \mathcal P} \log \left( \frac{\tilde{\pi}(\bm H_T) }{ {\pi}(\bm H_T) } \right) \\ & = \mathcal V_T(p,\mathcal P) \geq \mathcal V_T (\mathcal P)\end{aligned}")
The first inequality holds since the Kelly market vectors are a subset of the set of Market Vectors. The subsequent equality holds since
 = \prod_{t=1}^T \big( S_t(\bm h_t) \pi_t(\bm h_t | \bm H_{t-1}) \big) = \bm \pi_T (\bm H_T) \prod_{t=1}^T S_t(\bm h_t)")
and we can replace policies in
Ex 21. Show that for non-negative numbers 

Ans 21.

Ex 22. Show that the wealth factor for any investment policy can be expressed as a sum over the Kelly market vectors
 = \sum_{\bm H_T} \prod_{t=1}^T S_t(\bm h_t) \pi_t(\bm h_t | \mathcal H_{t-1})")
Ans 22.
 & = \prod_{t=1}^T \left( \sum_{i=1}^N S_t(i) \pi_t(i | \mathcal H_{t-1}) \right) = \prod_{t=1}^T \left( \sum_{\bm h_t} S_t(\bm h_t) \pi_t(\bm h_t | \mathcal H_{t-1}) \right) \\ & = \sum_{\bm H_T} \prod_{t=1}^T S_t(\bm h_t) \pi_t(\bm h_t | \mathcal H_{t-1})\, , \end{aligned}")
for 
Ex 23. Show that for
 \leq \max_{P\in \mathcal P} \max_{\bm H_T} \log \left( \frac{ \prod_{t=1}^T p_t(\bm h_t | \mathcal H_{t-1}) }{ \pi_T(\bm H_{T}) } \right)\, .")
Ans 23.  \right\} & \overset{Def. \ref{SI:MMR}}{=} \max_{P\in \mathcal P} \frac{ \mathcal W\! f ( P , {\mathcal H}_T) }{ \mathcal W\! f ( \Pi , {\mathcal H}_T) } \\ & \overset {[\ref{SI:6.5},\ref{SI:6}]}{=} \frac{ \sum_{\bm H_T} \prod_{t=1}^T S_t(\bm h_t) p_t(\bm h_t | \mathcal H_{t-1}) }{ \sum_{\bm H_{T+1}} \pi_T(\bm H_{T}) \prod_{\tau=1}^{t-1} S_{\tau}(\bm h_{\tau}) } \\ & \overset{[\ref{SI:4}]}{\leq} \max_{P\in \mathcal P} \max_{\bm H_T} \frac{ \prod_{t=1}^T p_t(\bm h_t | \mathcal H_{t-1}) }{ \pi_T(\bm H_{T}) }\, .\end{aligned}")
(Def. ?? = Def. 13, [??,??]= [18,22], [??]=[21].)
Ex 24. [Continued] Show that for 
 \leq \mathcal V_T(\mathcal P).")
Ans 24. For a constantly rebalanced portfolio, 
 & \overset{[\ref{SI:7}]}{\leq } \max_{\bm H_T} \log \left( \frac{ \max_{P\in \mathcal I} p_T(\bm H_t ) }{ \pi^*_T(\bm H_{T}) } \right)\\ & \overset{Def.\, \ref{SI:NMLF}}{=} \log \left( \sum_{\bm H'_t} \max_{P\in \mathcal P} p_T(\bm H'_t ) \right) \overset{[\ref{SI:2.5}]}{=} \mathcal V_T(\mathcal P)\, .\end{aligned}")
Here [??] = [23] , Def. ?? = Def. 4, and [??] = [6].
Ex 25. [Continued] Show that Thrm 19 holds. That is that
 = \max_{\mathcal H_T } \mathcal R\! g_T ( \Pi^* , \mathcal I ; \mathcal H_T) = \mathcal V_T(\mathcal P)\, .")
Ans 25. := \min_{\Pi} \max_{\mathcal H_T} \mathcal R\! g_T ( \Pi , \mathcal I ; \mathcal H_T) \leq \max_{\mathcal H_T} \mathcal R\! g_T ( \Pi^* , \mathcal I ; \mathcal H_T) \overset{[\ref{SI:8}]}{\leq} \mathcal V_T(\mathcal P)\, .") (Here [??]=[24]) and by [20] the inequalities also hold in the other direction.
(Here [??]=[24]) and by [20] the inequalities also hold in the other direction.
