We discuss a canonical multi-arm bandit setting. The stochastic multi-arm bandit with finite arms and bounded rewards. We let 


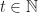


We let 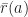
We define
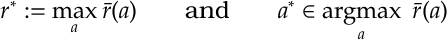
and also we define

We do not know these averages in advance and we only know the rewards from the times that we play each machine – we are only allowed to play one machine per unit time.
We let 
Assumption. There is some function 

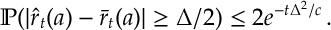
Many reasonably behaved distributions obey this condition. For instance, any bounded random variable and Gaussian random variables. This assumption can be relaxed.
A policy chooses a sequence of arms, 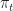

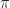

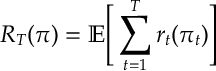
Def. [Regret] The regret of policy 
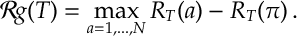
The regret is a frequently used metric of choice for bandit problems and many other areas of statistical learning.
The following lemma shows that we can analyse the regret by understanding the number of times we play a sub-optimal arm or equivalently calculating the probability that we play a sub-optimal arm.
Lemma [SMAB:Lem1] For a multi-arm bandit problem with Bernoulli rewards
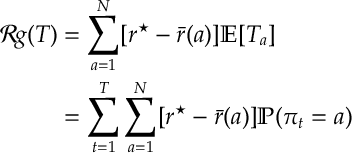
where 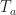
Proof. We can expand the reward of the optimal arm with
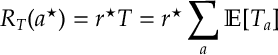
and, by independence, we can replace the reward with its expectation as follows
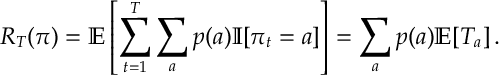
Now subtracting from gives the regret and the first equality. The second equality follows immediately from the fact that
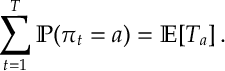
QED.
Explore and Commit.
Explore and commit gives a simple way of understanding the explore-exploit trade-off and why a regret of 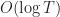
Suppose we implement the following policy:
Explore-and-Commit.
- We play each arm
- We play the best arm there after.
Given we are going to run our bandit experiment for
Theorem. For 
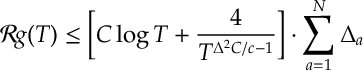
In the above, notice we need 
Proof. Let 


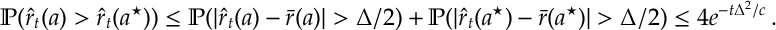 I.e. either
I.e. either 
We can split the regret into its explore and commit phases and then apply the above inequality:
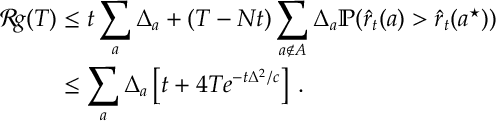
(At this point it is worth noting that the term in square brackets can easily be minimized, and it is minimized at 

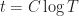
QED.
Deterministic Exploration.
The exploration phase in explore and commit does not have to all happen that the beginning. An easy way to deal with exploration is to decide in advance when you are going to explore each arm.
Specifically, for each arm 

Deterministic Exploration. At time
- If
play arm
- If no such arm exists, play the arm with highest reward found during exploration.
If 


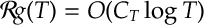
This is an exercise.
Epsilon-Greedy.
Rather tracking how long you need to play each arm a simple heuristic, with a similar proof to deterministic exploration is to randomize.

- with probability
, play an arm uniformly at random.
- Else, with probability
, play the arm with highest reward.
The proof for this policy is very similar to the deterministic exploration case. (We just need to apply a [Bernstein] concentration bounds to the amount of exploration.) Similar to before if 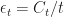
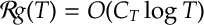
Again this is an exercise for the reader.
At this point, it is worth noting that we can get arbitrarily close to 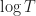
As we see shortly, with the Lai-Robbins lower bound, 
Upper Confidence Bound.
The proofs so far have relied on the bound
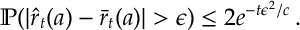
We noted that if we take 
Based on this, the Upper Confidence Bound algorithm looks at the values of 

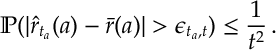
Given this holds for
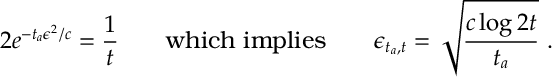
From now on we will take 
UCB choses the highest empirical mean plus error:
Upper-Confidence Bound (UCB).
- Choose any arm such that
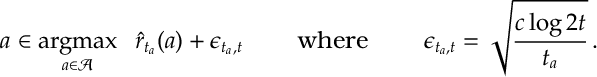
Notice for UCB algorithm so long as arm 
Theorem. The regret of UCB is
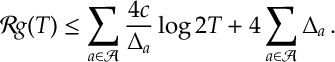
Proof. Given Lemma [SMAB:Lem1], we investigate the probability that UCB might select a sub-optimal arm. We will see that it occurs either because of insufficient exploration (which we will see is an issue that can only occur a small –order
Specifically, suppose at time 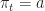

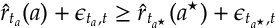
where 
In additional to playing arm
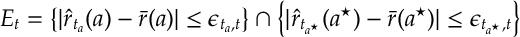
Then using the bounds in 


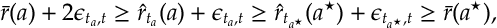
which3 in turn implies 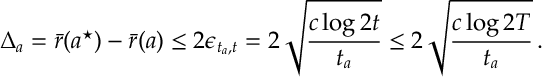
So we have a bound on how much we explored arm
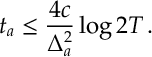
We can interpret this as saying: when we have good concentration, we choose the wrong arm,
Now we can also bound the probability that the event 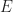
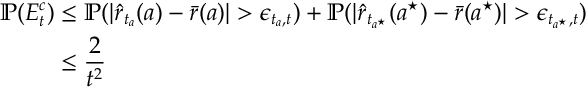
Putting everything together,
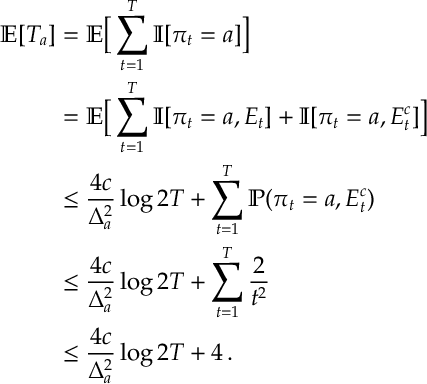
In the first inequality above apply , i.e. there can be at most 
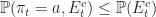
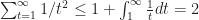
The result then follows by applying the above bound to the identity in Lemma [SMAB:Lem1], that is 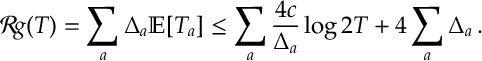
QED.
References.
There are quite a few great sources to go for Bandits. [This post is me revising really as I might teach some bandits next semester.] The reviews of Bubeck & Cesa-Bianchi, Lattimore & Szepesvari and Slivkins all give good coverage. Also there are associated blogs [I am a bandit] and [bandit alas]. The paper of Auer et al. provided a primary source for the above. Epsilon greedy and bandits are discussed in Sutton and Barto’s classic text.
- Regret Analysis of Stochastic and Nonstochastic Multi-armed Bandit Problems. Sébastien Bubeck, Nicolò Cesa-Bianchi (https://arxiv.org/abs/1204.5721)
- Bandit algorithms by Tor Lattimore and Csaba Szepesvari. 2020 [CUP]
- Introduction to bandits by Alex Slivkins
- https://blogs.princeton.edu/imabandit/
- https://banditalgs.com
- Finite-time Analysis of the Multiarmed Bandit Problem. Auer, Cesa-Bianchi & Fischer. Machine Learning volume 47, pages235–256(2002)
- Reinforcement Learning: An Introduction. Richard S. Sutton and Andrew G. Barto. http://www.incompleteideas.net/book/the-book-2nd.html
 .
.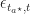 in the above bound.
in the above bound.